LLM costs vs quality: How Eightify picked the right GPT model

Subscribe to Toloka News
Subscribe to Toloka News
The challenge
The outcome
YouTube has over 3 billion videos, with 30,000 hours of video uploaded every hour. Eightify helps users consume more content with video summaries that extract the key ideas from any video in any language.
The ChatGPT-powered tool generates two types of summaries:
- A timestamped paragraph-by-paragraph summary, perfect for semantic search on the video and navigation.
- A TL;DR overview with a list of key takeaways from the video, meant to be consumed instead of the source material.
The Eightify team set out to choose the best base model for their TL;DR summary and partnered with Toloka to compare the performance of GPT-3.5 and GPT-4 in this context. The goal was to find the models' weak points, meaningfully describe those issues, and perform an in-depth quality evaluation — and then run a cost-benefit analysis to decide whether they should switch from GPT-3.5 to the more expensive GPT-4.
Toloka proposed a taxonomy of metrics and set up a human-powered evaluation pipeline. Read on to find out what the pipeline looked like and what conclusions Eightify came to in the end.
I was thoroughly impressed by the team at Toloka AI. They delved into topics that we had been wrestling with for a year and managed to understand the intricacies in just 10 minutes. Their efficiency was exceptional — we had results within a week.
— Alex Katayev, CTO Founder @ Eightify
As we handle a growing number of cases and users, we need robust data to make changes to our pipeline. Toloka AI has proven to be an excellent partner for this task.
The challenge: Designing robust and scalable quality evaluations
It's notoriously difficult to evaluate “how well” an entire video — say, an interview — is distilled into a short list of key insights.
The notion of quality is quite complex here. As we delved into the video summaries, we recognized several important aspects:
- Did the LLM accurately understand the ideas from the original video?
- Did it convey those ideas fully and in detail?
- Did it miss something important?
- Did it introduce any hallucinations or diverge from the source?
It's not easy to formalize the differences between a good summary and a bad one. The smart approach is to decompose the evaluation into several quality aspects and consider them separately. But even with the strengths of modern LLMs, it's not feasible to automate these types of quality measurements. For instance, how would you reliably know which phrasing of a particular idea is most faithful to the source?
Human annotation is also challenging in this context. Evaluators need to put in long hours checking the content of videos, and they need to be extremely attentive to detail to catch the model lying. It becomes even more difficult to scale up evaluations in order to get adequately large and diverse samples. Toloka's expert annotators face the challenge with dedication and precision.

The solution: A specialized taxonomy of metrics
Here's what we're interested in with the TL;DR summary (we refer to this task as key point distillation):
- The model should include everything of relevance and importance in the summary.
- It should include it accurately — with no errors — and convey it effectively.
- It should not include anything extraneous or redundant.
In terms of our metrics taxonomy, this boils down to 6 separate metrics. They are listed in the order of importance, meaning the first one has the largest impact on quality.
1) Context attribution (or Faithfulness)
Factual inaccuracies are sometimes introduced when extracting details on the key information, e.g. statements are attributed to the wrong speaker.
Undue explanations or general knowledge offerings may be observed with automatic summaries, e.g. the model might add some information on a speaker's background that's not present in the original text.
Oftentimes the model provides unwarranted opinions, judgments or conclusions purely by itself, without direct support from the source material, e.g. exaggerating and describing something the speaker merely discusses as "crucial for ..." / speculating on the opportunities or consequences, as in "this could potentially change the ...".
Entire discussion topics may be outright hallucinated by the model with nothing within the source even slightly resembling or being in any way related to what's written in the summary. Although this is rare, it's absolutely critical.
2) Completeness (or Recall)
The models often miss some vital parts of the source material (e.g. some products are missed in a "top-10 products for ..." video summary) or significant information / key insights.
3) Coherence
It is extremely common for automated summaries to be overly vague and lack substantive details when including some key information from the source, e.g. tangential mentions like “the conversation then turns to the question of AI safety” without any further expansion are quite frequent.
It's also common for the extracted information to be presented out of important context, lacking comprehensiveness, e.g. by providing an isolated quote from a speaker without explaining what message it attempts to convey.
4) Relevance
Automated summaries are often sprinkled with non-essential points and immaterial details from the source, e.g. mentioning products advertised in the video or adding the speaker's personal reactions or illustrations that don't contribute much to the development of the topics discussed.
5) Conciseness
There's an abundance of generic fluff in summaries, unsubstantive statements you could throw out and not change the meaning or lose any relevant details on the key information, e.g. addendums such as "which could benefit the users greatly".
6) Non-repetitiveness
LLMs are prone to repeating the same messages when composing a summary, especially if those messages are repeated in the source.
How it works: The evaluation pipeline
We evaluate the output from GPT-3.5 and GPT-4 in a side-by-side comparison, which gives us a straightforward estimation of “fuzzy” metrics. In other words, we get more stable results this way because it's easier to compare two texts and choose which one is more coherent than it is to rate them both on coherence from 1 to 10.
With each annotation sample, the evaluators read the source text first (before comparing the summaries) and enumerate and highlight the key points — those parts that should be included in the summary.
Source markup sample: highlights and numbers
As a byproduct, this part of the markup produces high-quality data that is extremely useful for fine-tuning or prompting.
We make sure evaluators don't see the model-generated summaries at this stage to reduce bias in discovering the key points.
After the evaluators finish marking key points, they receive the summarized lists for comparison. For both of the summaries, they examine each of the list items and consider 3 questions:
- Which of the key points does this item refer to?
- Do parts of the item refer to non-essential (unhighlighted) details?
- Are there any parts of the item that are not attributable to the source at all?
Summary markup sample: key references (green), redundancies (yellow) and errors (red, with explanations added)
This helps the annotators produce a more grounded and accurate evaluation of Completeness, Context attribution, and Relevance. Once again, labeling generates useful data as a byproduct.
Next, they consider each of the evaluation criteria (the six metrics selected for this task) and choose which of the summaries is better (or whether it's a tie).
Finally, the annotators pick the best summary overall — taking into account the previously made side-by-side evaluations, the order of precedence for the criteria, and their own personal preferences.
Results and insights
The results show GPT-4 leading in faithfulness and recall, but the two models rank so closely on the four other criteria that the differences are not statistically significant.
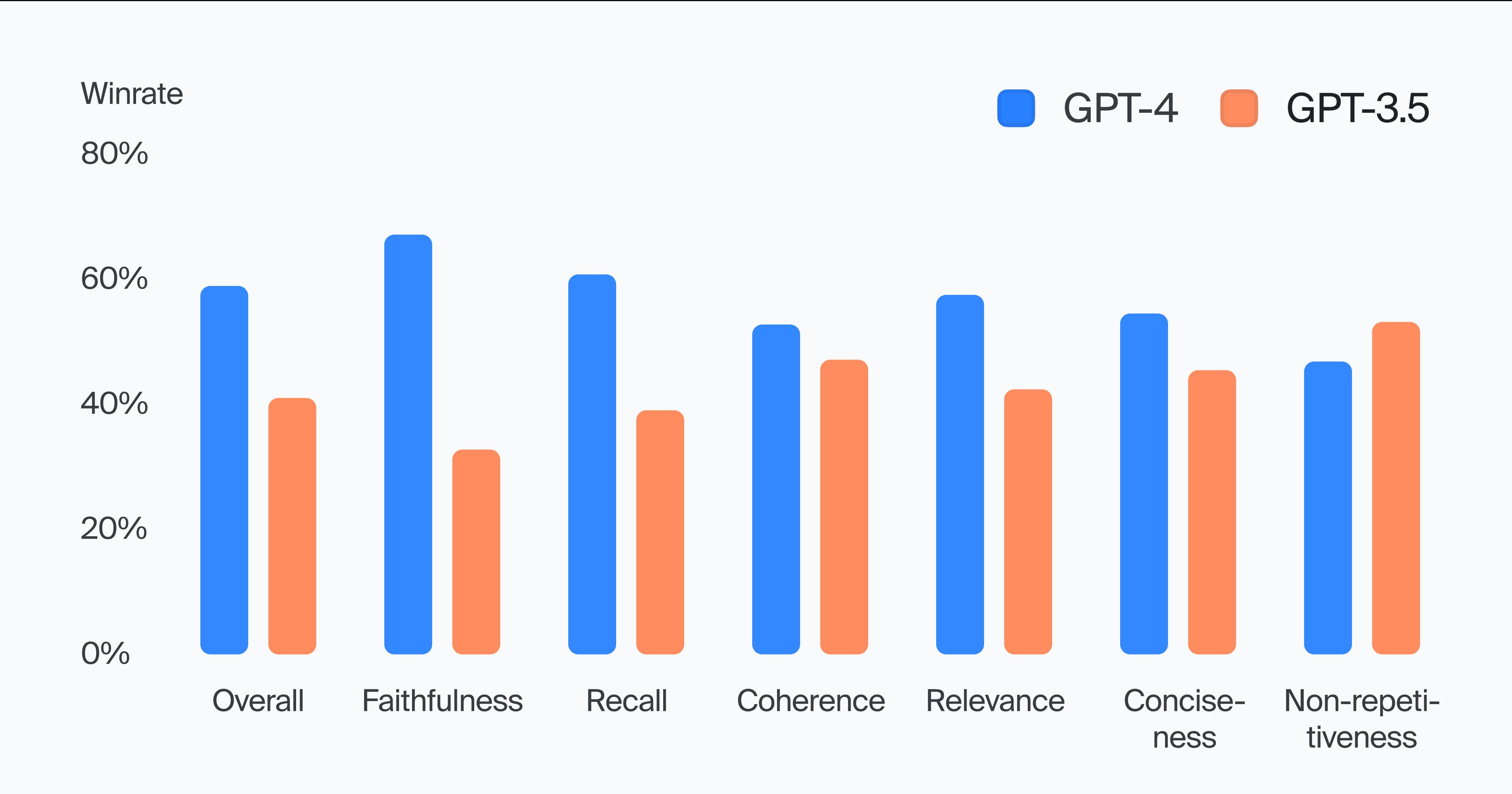
The overall GPT-4 win rate does significantly exceed the 50% mark, at 59% wins. (The overall win rate is the percentage of evaluations where annotators picked GPT-4 output as the best summary overall.)
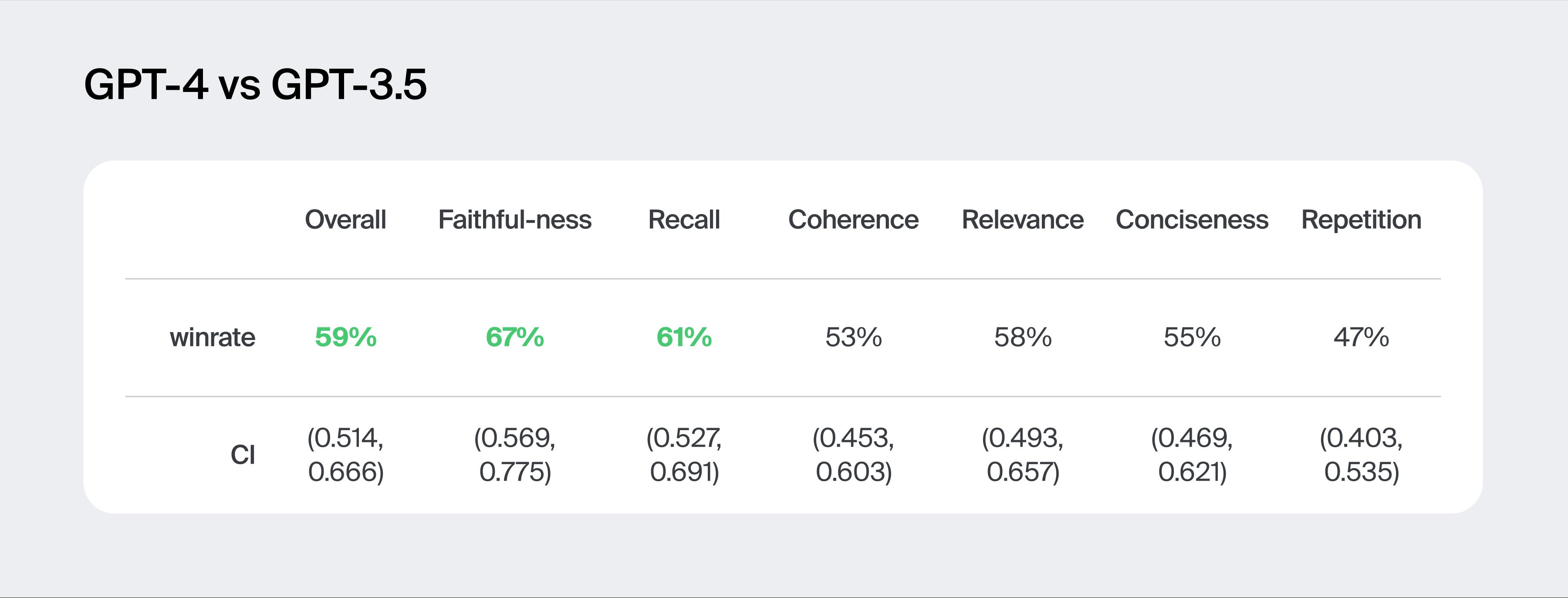
The results reflected in the metrics are in line with the impression we get after examining the sample data manually. Subjectively, it feels like GPT-4 is more accurate at detecting and extracting significant information, while in terms of presentation, quality of clarifications, and abundance of redundancies — the models are on par with each other.
The following two examples illustrate the different strengths of the models.
Example 1
Source piece
And last, you can also specify the model that you would like to use. I want to use the medium model. You have five different models that you can choose from. On the low end, you have the tiny model. This takes up the least space. It also works the quickest, but you get the worst accuracy. On the other end, you have the large model. It takes up about a gig and a half. It also takes the longest time to process. But you also get the highest quality level. I found that a good sweet spot is going with the medium model
GPT-3.5 (attempts to be more "interpretive", but results in a misinterpretive deviation)
💻 Choosing the right model is crucial (it's more like "allowing" than "crucial" in the source text) for having good accuracy and processing time when using Whisper AI's speech to text technology.
GPT-4 (closer to the original wording, resulting in an accurate retelling)
🤔 Whisper AI offers five different models — from a tiny one to the largest 1.5Gb one — enabling the user to trade-off speed and storage space vs accuracy
Example 2
Source piece
Submit to the things you must do, because the thinking has already been done by you. Shut your mind off and relinquish yourself of the burden of overthinking. Learn what it feels like to put your rationalization on mute. Take a deep breath and do what you need to do. Trust the more authentic voice in your head and let it override your weaker self, because over time, this authentic self will become your primary voice. And the more you listen to your authentic self, the more you'll develop a stronger sense of identity
GPT-3.5 (succeeds at an “interpretive” retelling)
🤔 Surrender to the things you've set out to do, don't overthink it, trust your authentic part to develop a strong sense of identity
GPT-4 (uses a direct quote and doesn't fully convey the thought as a result)
🤫 "Trust the more authentic voice in your head and let it override your weaker self, because over time, this authentic self will become your primary voice."
Outcome
Our evaluation results suggest that Eightify won't benefit by switching to a GPT-4 based pipeline. For the purposes of video summarization, the differences in quality are not significant enough to justify the higher cost of GPT-4.
Eightify's production pipeline has multiple stages prior to the GPT call (segmentation, preprocessing, and so on) that do most of the heavy lifting, so the performance gap between the GPT-4 and GPT-3.5 pipelines is not that large. The only real potential for improvement is in the faithfulness aspect, and even that might be achieved without upgrading to GPT-4 — for example, by using a few dedicated fact-checking runs with a smaller model such as GPT-3.5 fine-tuned on the error highlights and comments.
In the same vein, further pipeline enhancements might bridge the gap completely. To improve conciseness and non-repetitiveness, additional “editor mode” GPT-3.5 runs with proper few-shot prompting would probably deliver a significant uplift. But switching to GPT-4 wouldn't make a difference by itself.
To implement and test these approaches, you'd need fine-grained quality analysis, measurable performance indicators, and a good amount of annotated data — and that's where Toloka's evaluation pipelines shine.
Building a production pipeline for your app?
Similar to Eightify, if you have an extensive pipeline that does substantial work before the API calls to the LLM, you probably won't increase your return on investment by choosing a more expensive base model.
A good strategy is to start with a solution that uses a lower-cost model in a custom domain-specific pipeline, instead of implementing an expensive model right off the bat. You won't sacrifice much in terms of performance and your application will be much more cost-effective.
Toloka can perform a comprehensive evaluation to compare model performance in the context of your business goals and help your team make an informed decision. To discuss metrics and next steps, reach out to our evaluation team.
Learn more about Toloka Deep Evaluation:
Learn more
Recent articles




Have a data labeling project?
