Perplexity enhances LLMs with holistic quality evaluation

Subscribe to Toloka News
Subscribe to Toloka News
Summary
Client: Perplexity AI
Task: Evaluating helpfulness of gpt-3.5 (RAG) vs. pplx-70b-online
Goal: Select the optimal model for a conversational search interface and get deep insights into model quality
Metrics evaluated: Helpfulness, Truthfulness, Safety
Perplexity is revolutionizing information search with their LLM-powered search service. The interactive search bot can answer almost anything users throw at it, by asking follow-up questions to pin down the intent and then summarizing findings from across the internet, finishing off with links to reliable sources like the icing on the cake.
While other large language models are also good at answering questions, they sometimes provide unsupported information, don't cite all their sources, and occasionally refuse to answer harmless questions out of an abundance of caution. Different models on the market vary in their output, sometimes showing striking differences in readability and helpfulness of answers.
Perplexity stands out for its ability to provide well-structured answers to complicated questions with lots of details. But to stay on top, they needed to make sure they were using the best model for the job.
The challenge: Compare models on helpfulness
The Perplexity team wanted to design a comprehensive LLM evaluation plan. They were seeking a data partner to support their human evaluation needs and turned to Toloka to supplement their evaluation efforts.
Model quality is not easy to measure. How do we decide what makes an answer helpful? There are a few criteria that usually come to mind:
- It's thorough and covers all information that is relevant to the query.
- It's free of redundant words and repetitive phrases or ideas.
- It's well-structured so it's easy for readers to understand the key points.
- It's truthful and free of unsupported or fake information.
Our evaluation focused on truthfulness and helpfulness.
The goal was to compare two models and choose the optimal model to use in production: gpt-3.5 (RAG) (the most popular model for the task) versus pplx-70b-online (Perplexity's custom model). GPT-3.5 (RAG) refers to GPT-3.5 accessed via API and plugged into Perplexity's search index for up-to-date information.
The Perplexity team had already performed similar evaluations, with results published in their blog. However, the main difference was they were running comparisons with a setup where GPT-3.5 doesn't have access to the internet . Our experiment set out to compare two online models, both accessing the same search index. In this experiment, the search results were held constant, and the only variable was the model itself generating the response. We also developed a unique evaluation methodology for detailed helpfulness metrics, which gave us slightly different results.

The solution: A 2-stage pipeline for holistic evaluation
For holistic evaluation of helpfulness, we get the best results by breaking down the evaluation task. We split the evaluation pipeline into two steps:
-
Point-wise truthfulness evaluation. Annotators analyze the query and answer pairs generated by each model. They rate the factuality of each sentence by checking the snippets provided (snippets are website excerpts used to generate the answer). We use the labels to calculate the Truthfulness metric and then compare the scores of the two models.
-
Side-by-side helpfulness evaluation. Annotators read a query and compare the answers from Model 1 and Model 2, label each sentence on relevancy, and decide which answer is better (or they are equally good or equally bad). We use these labels to calculate the win rate of one model over the other.
Modern LLMs are extremely good at text generation, and mistakes are hard to detect with the naked eye, especially in long texts like the ones generated for these tasks. To improve the quality of human labeling, we use fine-grained evaluation throughout the pipeline. Expert annotators highlight and evaluate each sentence individually, which helps them notice more detail and analyze the texts more carefully, resulting in better accuracy.
Because these evaluation tasks are complex, one of the most important parts of the process is finding expert annotators with the right skills for the job. We rely on our group of AI Tutors, trained and highly motivated editors who handle a wide range of tasks for GenAI, including data collection, content creation, complex evaluation tasks, and more.
The details: How the evaluation pipeline works
Stage 1: Point-wise truthfulness evaluation
Annotators classify each generated text sentence-by-sentence using color highlighting for these classes:
-
Supported - The sentence is completely supported by the source.
-
No need to check - The sentence is common knowledge or repetitive.
-
Not enough info - The sentence is not completely supported by the source.
-
Refutes - The sentence contradicts the source.
-
Discrepancy between sources - Sentence is supported by one source and refuted by another.
-
Gibberish (Absurd) - The sentence is gibberish.
Then they rate the text overall for Factuality. If all the sentences are either green or pink, factuality is supported. If there are other colors, factuality is not supported.

Stage 2: Side-by-side helpfulness evaluation
Annotators compare two model responses for the same search query by highlighting the sentences with 4 color categories:
Then annotators look at the text overall and answer several questions, including “Does response have clear structure?” and “Does response answer the query?”. These questions guide annotators to make the final decision and choose which response is more helpful or declare a tie.

The results: And the winner is…
Evaluation results proved that pplx-70b-online is significantly more helpful than gpt-3.5 (RAG), with the same level of truthfulness. The Perplexity team can be fully confident in running their custom LLM for production.
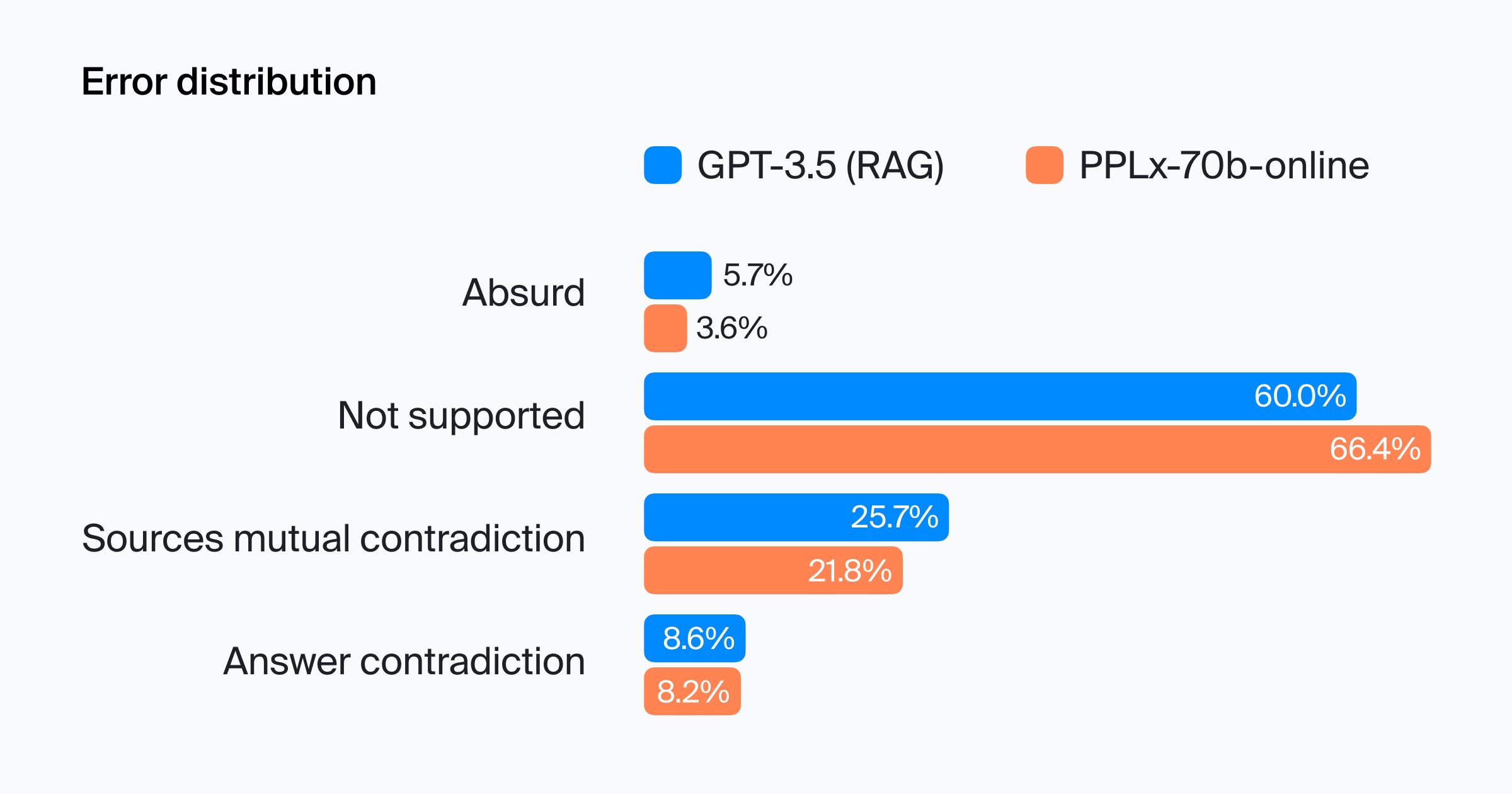
Truthfulness
No significant difference in truthfulness quality was detected between the two models. Four types of errors were detected:
- Absurd. The model's response contains gibberish or doesn't make sense.
- Not supported. Information in the response is not supported by the sources.
- Sources mutual contradiction. The sources contradict each other and a fact taken from one source is different in another source. Or facts contradict each other.
- Answer contradiction. The response contains facts that contradict the sources.
Helpfulness
Perplexity's in-house model (pplx-70b-online) generated significantly more helpful results than gpt-3.5 (RAG).
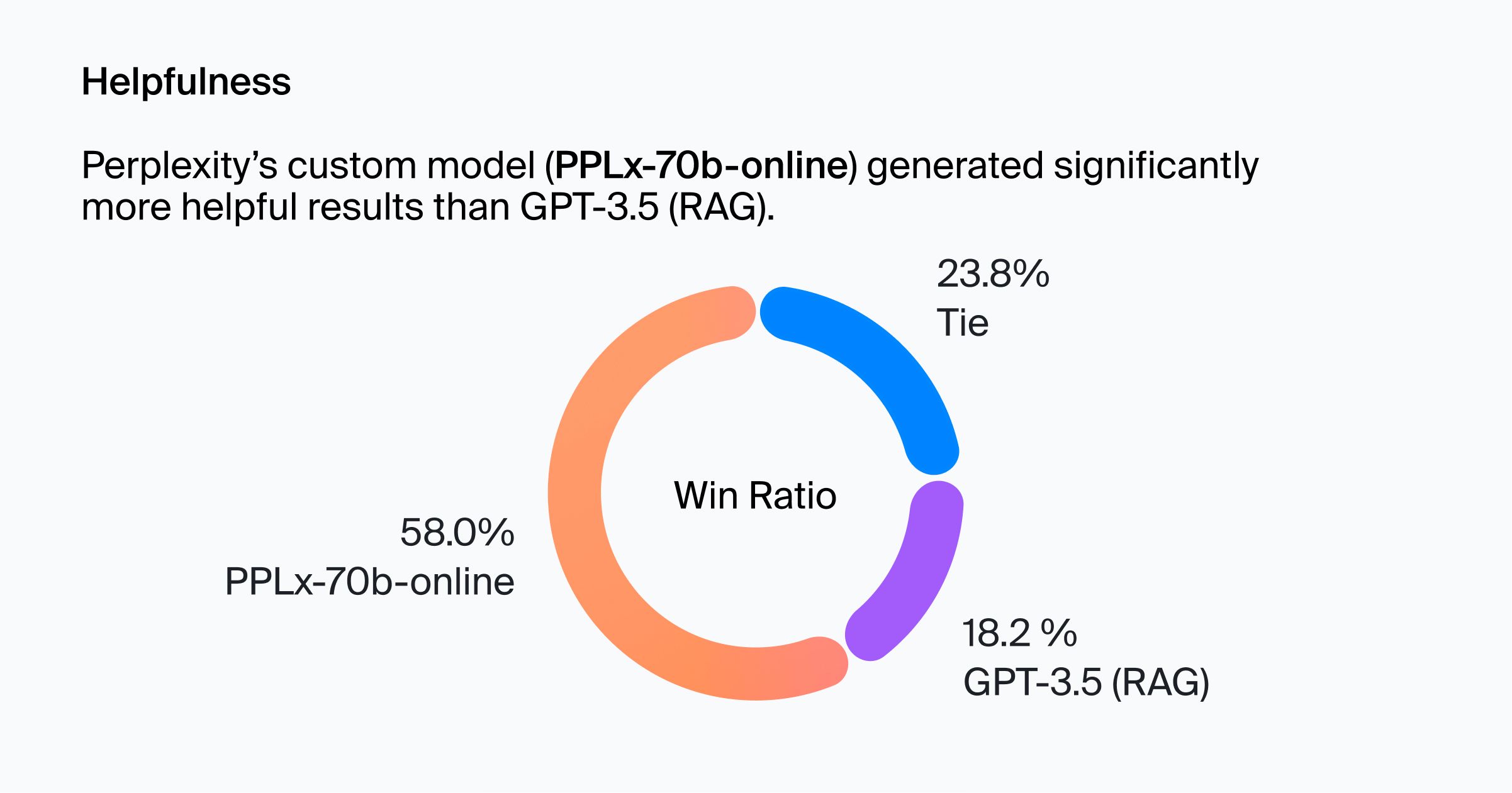
The share of cases when one model won helpfulness. Perplexity's pplx-70b-online significantly outperforms gpt-3.5 (RAG).
The outcome: Insights into model quality
Perplexity's in-house model is a clear winner in the helpfulness aspect, supported by detailed answers with a clear structure. The team benefited from solid metrics for confident decision-making that will lead to happier users.
In addition, our deep evaluation revealed aspects of the model's performance with room for improvement. Based on evaluation results, we provided recommendations with a detailed list of ways to improve the factuality and repetitiveness of model responses.
Factuality mistakes are hard to detect in modern GenAI systems, but fine-grained evaluation pinpointed several issues:
- Multiple sources with different quantitative factoids. In this case, the model tends to choose one and ignore the others. We don't know which one is correct, so the solution should warn the user about the situation instead of picking one.
- Incorrect summarization. When there are two dates and statements, the model combines the sentences into one and selects only one date.
- Pure hallucination. Occasionally the model provides facts that are not supported by the sources.
- Errors with table parsing. The model takes information from one row and combines it with a date, quantity, or other information from a different row.
The evaluation pipeline established with this project can be useful for other companies who are interested in LLM applications, such as fine-tuning models for specific use cases or comparing different model versions.
Learn more about Toloka Deep Evaluation:
Learn more
Recent articles




Have a data labeling project?
