New Metric: Markup Consistency in a Dataset
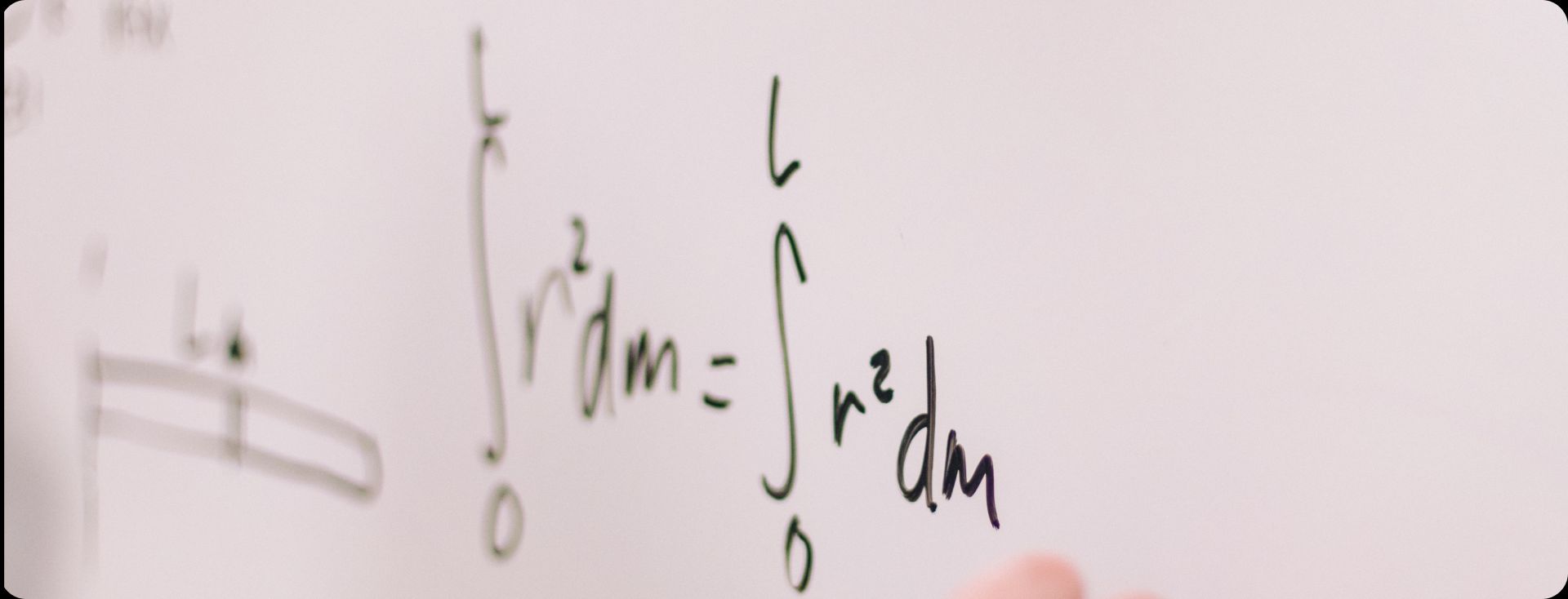
Subscribe to Toloka News
Subscribe to Toloka News
In this post, we'll share our insights on quality control in Toloka. While we plan to develop and use this information to simplify quality control settings for ourselves, we believe it's a positive contribution to the crowdsourcing community as a whole.
We'll be discussing projects with classification tasks and an overlap greater than 1:
In these projects, requesters can combine two indicators — accuracy in control tasks and accuracy by majority vote (or consistency accuracy for short) — to ban frauds from the project while adhering to restrictions on the quality control budget.
The quality control budget is the amount that can be paid for control tasks, which is calculated based on the ratio of control tasks to main tasks. The more control tasks there are, the easier it is to accurately assess the quality of a performer's responses and how well they understand the instructions. However, more control tasks also means less responses for main tasks. (To keep things simple, we won't discuss overlap settings used to optimize the overall project budget in this post.)
Why is it better to use two indicators at once?
There's more than one reason why we use two indicators to assess quality control.
Firstly, advanced frauds can "hack" control tasks: they pass those, but give useless responses in main tasks. If this is the case (assuming the number of frauds is relatively low), consistency-based quality control alone can help catch these users.
Secondly, relying solely on consistency-based quality control doesn't tell us whether users properly understood the instructions. We should also note that trying to gauge a user's performance by increasing the number of control tasks may be beyond the budget, but since gauging consistency accuracy is "free", we can learn to use consistency control in place of control tasks.
How do we make quality control a mere optimization task?
Given the limited budget and the need for quality markup, a requester has to determine the following three factors when configuring quality control settings:
- the number of control tasks (percentage, limited by the quality control budget)
- the accuracy threshold of control tasks
- the consistency accuracy threshold.
We want our requesters to be able to define these three parameters at once: this maximizes a certain metric used to gauge the overall quality of the markup. As for what that metric is, we propose using post-hoc rating probability based on the majority vote (or MV rating). We'll be calling this metric consistency going forward (we haven't seen the term used in any literature on crowdsourcing, but we think it best gets the point across).
Formal definition

We should also note that this metric is consistent with advanced aggregation model algorithms (such as Dawid Skene and GLAD), which use unknown model parameters and aggregated task scores to generate the most likely estimates for submitted ratings (which is the same as a post-hoc aggregated score probability based on chosen parameters and performer scores).
Consistency plain and simple
We can think of the average consistency of a dataset as the probability of a dataset having errors. We think that this does a better job at evaluating the markup quality in a dataset than the average skill level when each response in the dataset was marked (which is now available in the requester interface).
Examples
To compare what we can learn from consistency and average skill levels, let's look at two examples (assuming the fraud percentage is low):
Example 1 Let's say our data set has a lot of highly skilled performers, but responses in tasks are inconsistent. This makes it hard to pick a clear aggregate response, and that kind of evaluation may result in bad dataset markup. For example, take the following set of values for a single task:

Despite the high average value of the skill (80) being evaluated, the consistency metric would make it clearer if the resulting markup contains any errors. Consistency for tasks with a binary score:

Example 2 Let's say our dataset includes a lot of performers with lower skill levels, but their responses remain consistent If we pick the right overlap settings in this kind of scenario, we can choose a better aggregated response and get quality dataset markup. For example, take the following set of values for a single task:

Despite the low average value of the skill (60) being evaluated, markup consistency is high:

We assume that a low average consistency in a project may be a sign of poor quality control, which is why we want to show Toloka requesters the average consistency for all Toloka tasks from August
Average consistency for August 2020
For now, we can only calculate consistency values for projects that use no more 10 classes for evaluation. Since this is the average value for all main tasks in one month, it makes sense to look at how this metric is reflected in large projects (that have at least 100 main tasks per month). You can also view the table below for a uniform sample with different consistency values for projects with more than 10K main tasks in August:
| Project title | Av. skill by control tasks | Av. skill by consistency | Av. consistency |
|---|---|---|---|
| Comparing translations of Russian words and phrases into German | 82.23107904 | 79.36405202 | 0.076615554 |
| Evaluating responses and Yandex.Station actions. Expanded context. Music scenario | 78.72075213 | 80.44344562 | 0.140748306 |
| Side-by-side, search | 77.97712163 | 73.1589179 | 0.173233164 |
| Evaluating similar images | 83.77622478 | 84.36309599 | 0.204803946 |
| Banner moderation (checking text) | 92.89002558 | 99.91747965 | 0.242403267 |
| Is the object needed for the request | 83.27502816 | 81.16731255 | 0.28376269 |
| Identifying brands on banners. GO | 98.60875502 | 87.9095285 | 0.349130378 |
| Choosing the best translation (ru->en) | 80.72487178 | 79.68606376 | 0.414450987 |
| Does the site match the request? (2 gradations, mobile) | 87.55593833 | 88.51671078 | 0.462360591 |
| Is the document good? | 86.77184429 | 84.13691697 | 0.5240317 |
| Assessment of collections from Yandex.Collections (v2) | 89.24063768 | 86.74645777 | 0.55017285 |
| Is this a medical site? | 97.57765935 | 96.9073936 | 0.582259962 |
| Kişisel asistanin verdiği cevaplarin kalite değeri (new changes) | 90.65194986 | 91.44174877 | 0.625294721 |
| Count animals (including insects) | 95.62296331 | 93.58568692 | 0.673175879 |
| Identifying adult requests | 97.81312319 | 99.23603669 | 0.711690093 |
| Identifying topic change in dialog | 88.61013614 | 86.35797744 | 0.756580622 |
| Comparing news | 91.93318368 | 78.66238593 | 0.794130113 |
| Semantic matching phrases and queries | 93.88603556 | 88.75220227 | 0.841185449 |
| Choosing chatbot responses 3 | 91.12318868 | 90.27988835 | 0.865226058 |
| Side-by-side, design | 88.77357973 | 72.58320828 | 0.894701694 |
| Selecting a 3D object correctly | 93.39667698 | 96.4265263 | 0.925126879 |
If this metric is low for your project, we recommend changing your quality control settings manually (maybe by adding a consistency accuracy threshold).
Future plans for applying consistency
- We plan on giving recommendations for setting accuracy thresholds for control tasks, for consistency accuracy, and for the percentage of control taks to achieve target consistency values within a particular budget. We hope these recommendations make the quality control settings interface easier for requesters to use.
- As an approach to creating combo-skills in Toloka: consider quality from different projects so that the resulting value maximizes consistency across other projects.
- Use consistency to optimize picking performers in overlaps.
- Consider the contribution made by each performer and the way it affects average consistency. That will let you pinpoint users who raise or lower the average consistency value and positively impact the whole platform, not just a single project.
We're sure there's a bright future for consistency.

Recent articles




Have a data labeling project?
