ROVER
crowdkit.aggregation.texts.rover.ROVER | Source code
ROVER( self, tokenizer: Callable[[str], List[str]], detokenizer: Callable[[List[str]], str], silent: bool = True)Recognizer Output Voting Error Reduction (ROVER).
This method uses dynamic programming to align sequences. Next, aligned sequences are used to construct the Word Transition Network (WTN):
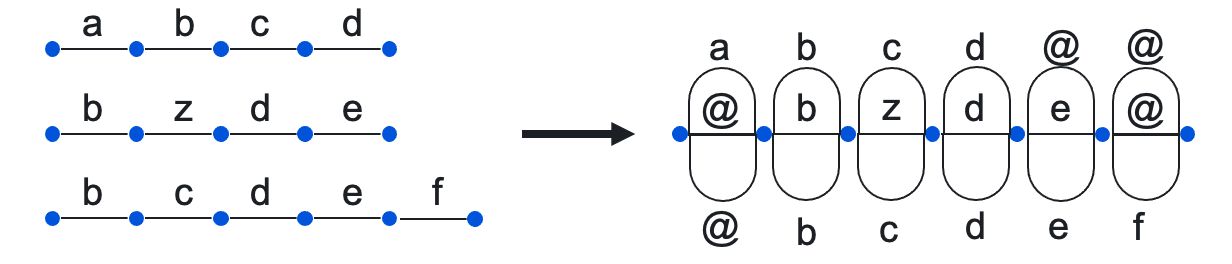
Finally, the aggregated sequence is the result of majority voting on each edge of the WTN.
J. G. Fiscus, "A post-processing system to yield reduced word error rates: Recognizer Output Voting Error Reduction (ROVER)"
1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings, 1997, pp. 347-354.
https://doi.org/10.1109/ASRU.1997.659110
Parameters description
| Parameters | Type | Description |
|---|---|---|
tokenizer | Callable[[str], List[str]] | A callable that takes a string and returns a list of tokens. |
detokenizer | Callable[[List[str]], str] | A callable that takes a list of tokens and returns a string. |
silent | bool | If false, show a progress bar. |
texts_ | Series | Tasks' texts. A pandas.Series indexed by |
Examples:
from crowdkit.aggregation import load_datasetfrom crowdkit.aggregation import ROVERdf, gt = load_dataset('crowdspeech-test-clean')df['text'] = df['text'].str.lower()tokenizer = lambda s: s.split(' ')detokenizer = lambda tokens: ' '.join(tokens)result = ROVER(tokenizer, detokenizer).fit_predict(df)Methods summary
| Method | Description |
|---|---|
| fit | Fits the model. The aggregated results are saved to the texts_ attribute. |
| fit_predict | Fit the model and return the aggregated texts. |
Last updated: March 31, 2023