
Training data
for machine learning
Take full control of your data labeling process, timeframe and quality.
Build reliable algorithms with quality datasets of any size.
Data labeling for ML models
With Toloka, you can control the accuracy of data labeling to develop high performing ML models.
Fastest Time-to-Result
Launch your project in minutes with our preset solutions and 24/7 data labeling for fast results.High Quality
Place your confidence in custom-built algorithms tuned for superb data accuracy at scale.True Scalability
Unlock scalability with versatile features, a highload system, and easy integration into ML pipelines.Transparent Pricing
Pay per label with no minimums and stay under budget with significant cost savings at scale.
Data labeling
for Сomputer Vision
Our platform supports annotation for image classification, object detection and recognition, semantic segmentation, and more. Labeling tools include bounding boxes, polygons and keypoint annotation.
Learn more
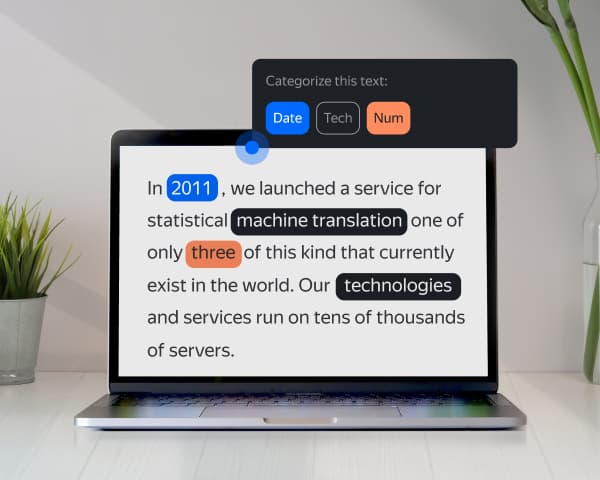
Data labeling for Natural Language Processing
Our platform supports annotation for named entity recognition (NER), text classification, speech recognition, sentiment analysis, intent classification, text recognition, and more.
Learn moreView Live Demo
Access the Demo. See Toloka in action.
Toloka offers flexible project configuration: use our presets for a faster start, or take
full control to customize your projects for the most complex labeling needs. Options
include adaptive tools and automation to develop a robust data pipeline that
evolves with you. Hands on or hands off — it's up to you.
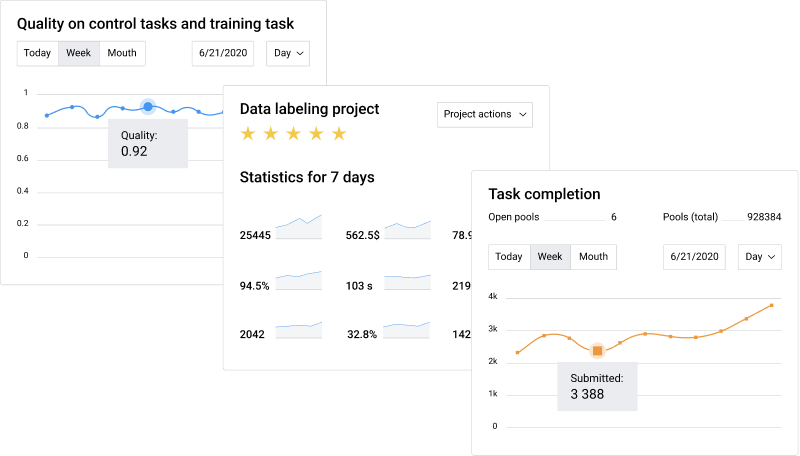
Real-time insights
Track your projects with real-time statistics on progress, spending, quality, time spent on tasks and active users involved. Leverage detailed analytics to fine-tune as necessary and make timely decisions to optimize speed, quality and budget.
Success stories
Have a data labeling project?
Take advantage of Toloka technologies. Chat with our expert to learn how to get reliable training data for machine learning at any scale.