← Blog
/

Agents don't have a capability problem. They have a comprehension problem.
Toloka Arena is live. See how your model ranks.
We ran 18 frontier models through ~1,000 private enterprise tasks and graded 75,000+ runs field by field against an expert ground truth. The best model reliably finishes about half. The half it misses is not random noise and not a gap in raw capability. It is a failure of comprehension: stable, shared across the frontier, and invisible to the model making it.
Renaud de la Gueronniere · Creator and technical architect, Toloka Arena and TolokaForge · May 2026
An AI agent demo is a single run that worked. A production deployment is the same task, a thousand times, with a customer on the other end. The gap between those two things is the entire problem, and almost nothing measures it.
Public benchmarks do not. They leak into training data within months of release, they are scored on a single attempt, and a frontier model can now locate and decode an answer key mid-evaluation. A headline benchmark score in 2026 measures optimization pressure as much as capability.
So I built the opposite. Toloka Arena is a set of private, expert-authored enterprise environments that have never been on the internet. We ran 18 frontier models through them blind, with a target of five repeated runs per task, and graded every run on the final state of the database, field by field, against a ground-truth answer written by a domain expert. No LLM-as-judge. No partial credit for a confident paragraph. This post is what 75,000-plus of those trials show.
What follows is a diagnosis by elimination. “Unreliable” has a set of comfortable explanations, and each one is testable. It is sampling noise, so retry it. It is a weaker model, so pick a better one. The next release will fix it. It only needs the policy retrieved into context. We tested all of them. On 75,000 graded trials, every explanation is wrong.
What the data shows instead is a single failure with a handful of properties. The frontier’s enterprise errors are:
Stable: a retry is the same wrong answer.
Shared: models from rival labs fail the identical task the identical way.
Persistent: a version upgrade does not touch them.
Invisible: the agent reports success either way.
Directional: when it is wrong it errs toward inaction.
Put together they say one thing. Reliability is not an engineering gap, it is a comprehension gap: the agent does not understand what correct means under a specific policy, it cannot tell that it does not, and the whole frontier is wrong in the same place. The findings below are that argument, run one comfortable explanation at a time.
What the data says |
|---|
The best model completes 52% of routine enterprise tasks reliably. Half the field scores under a third, and three are near zero. |
"Flaky" is the wrong word. When a GPT or Claude model fails a task it can sometimes pass, ~74% of the time every failing run misses the same field the same way. The error is fixed; only whether you catch it is random. |
The misconception is shared, and structured. Residualize the failure fingerprint and the lab families fall out unsupervised, then it splits the Claude line: four Chinese open-weight models fail like the Claude 4.6 generation, not like the GPT frontier, and it holds after controlling for capability. |
Failures come in two kinds. A new model version, and a higher reasoning setting, fix the coin-flips and leave the blind spots almost untouched: hard-failed tasks survive an upgrade 93% to 99% of the time. |
The agent cannot tell. Its "done" does not track the run; a non-GPT model reports "done" on 28% to 45% of its failures, and GPT only looks better because it rarely narrates "done" on any run. |
Failure is judgment, not mechanics. Models get ~93% of functional fields right and ~77% of policy-driven judgment fields. |
The errors have a direction. When a frontier agent gets a judgment call wrong it errs toward under-reaction, 74% of the time on the flag and notification fields, every one of 18 models. It downgrades priority, drops escalations, skips required notices. |
01. The benchmark
A test you cannot study for
Seven enterprise domains: logistics, airline operations, an airline travel desk, a quick-service-restaurant back office, a travel marketplace, a bank HR service desk on Dynamics 365, and discrete manufacturing. Each is a working software environment, not a prompt. The agent is handed a real customer request and a live tool surface — Dynamics 365, Salesforce, Workday, a Zendesk instance, an airline passenger-service system, a warehouse-management system — with dozens of API tools and a policy document it has to read and apply.
A task is graded by running it to completion and comparing the final database state to an expert-authored golden state, field by field. A trial passes only if every graded field matches. We target five repeats per task; pass^k is scored only on task cells with at least k completed repeats. The headline metric is pass^5: the task counts as solved only if all five runs pass. That is the deployment bar. A workflow that works four times in five is not a feature, it is an incident.
One note on scope. The leaderboard is the full 18-model official run. The trial-by-trial analyses that follow — flakiness, cross-model correlation, self-report, field accuracy, escalation and failure modes — are computed from the per-trial transcript export, on a fixed 18-model panel across the six cleanly-graded domains. Both layers are stated again in the method note.
Key numbers:
18
Frontier models, run blind
7
Full enterprise domains, real software environments
75,172
Graded trial records; pass^k uses task cells with at least k repeats
0
Test cases ever published online
02. The leaderboard
The best agent in the world is barely at half
GPT-5.5, run at maximum reasoning effort, leads at 52% pass^5. On barely half of routine enterprise tasks does the best available model succeed five times out of five. A tight cluster of GPT and Claude models follows in the high 40s, then a cliff: Sonnet 4.6 at 36%, then DeepSeek V4 Pro at 33%, the strongest openweight model. Below them the rest of the field is mostly in the teens or single digits, and three models are effectively at zero.
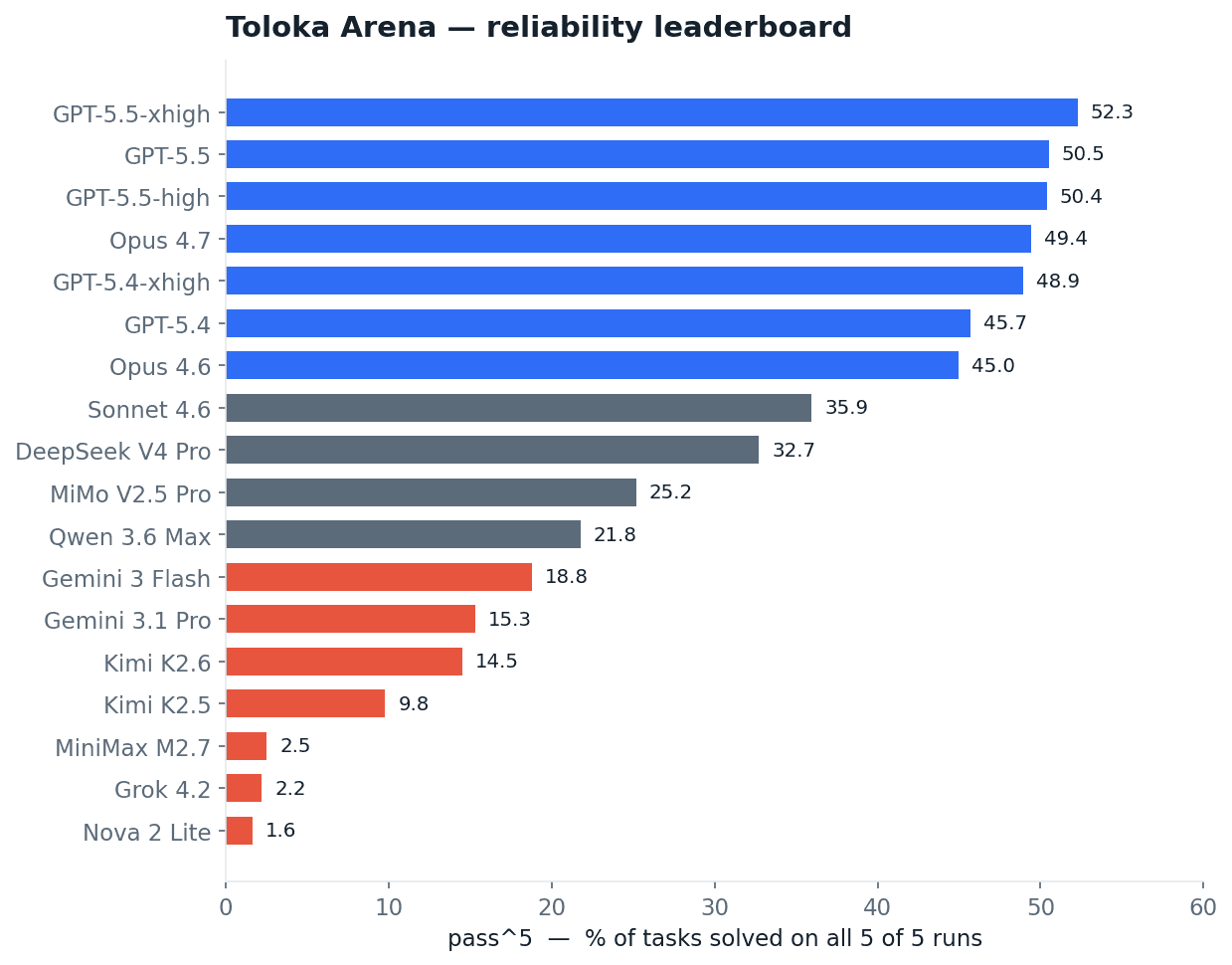
Fig 1. pass^5 for all 18 models: the share of tasks a model solves on all 5 of 5 runs.
Takeaway
The best agent on the market is roughly a coin flip on routine enterprise work. Even on the most generous scoring it rises to about 60%, and on no scoring does any model clear 70%. Any deployment plan that assumes 80%-plus reliability is planning against a number no model in this study reaches.
03. Reliability
"Works once" is not "works"
Score the same models on a single attempt, pass@1, the metric every public leaderboard uses, and they look 11 to 23 points better, except the three models already near zero, which have little room to fall. As you raise the bar from one passing run to five, every model slides down, and the slide is steepest for the models that looked strongest on a single shot.
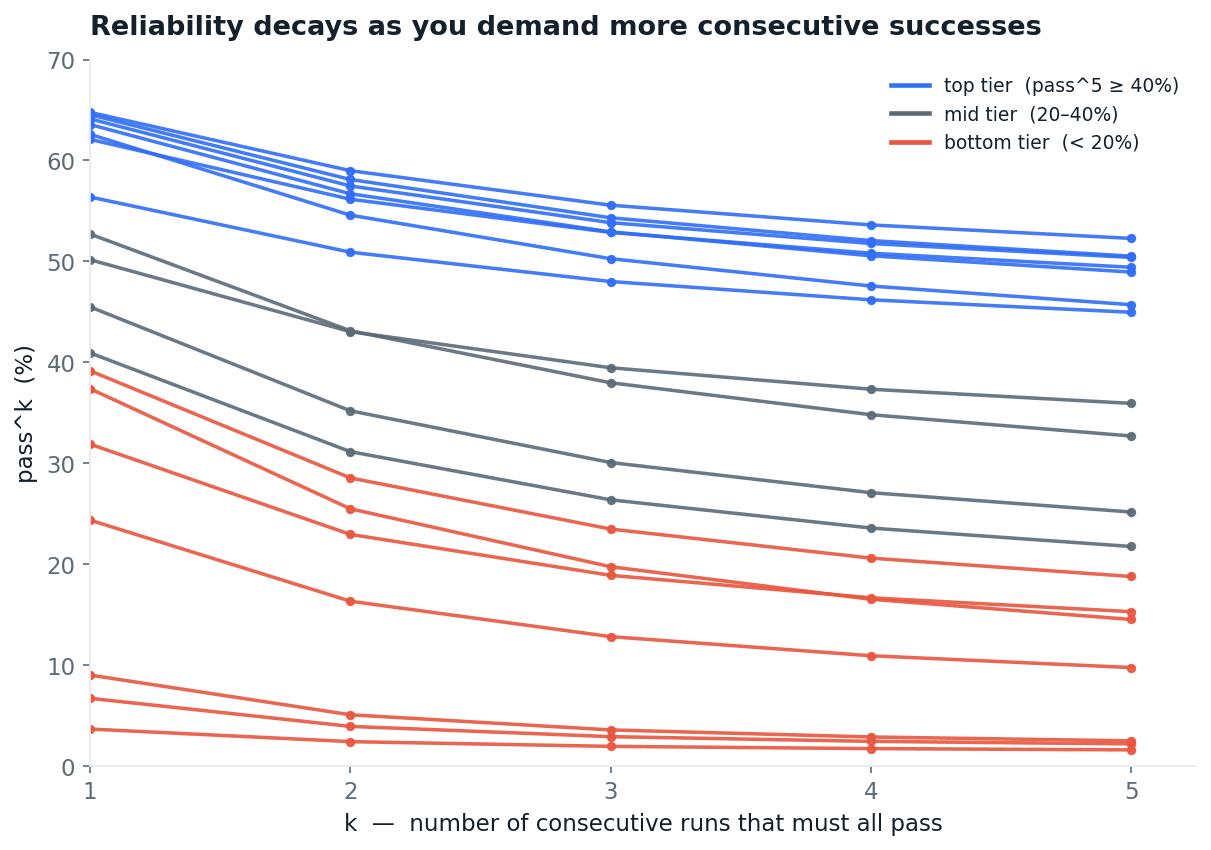
Fig 2. pass^k as a function of k, the number of consecutive runs that must all pass. Every curve decays.
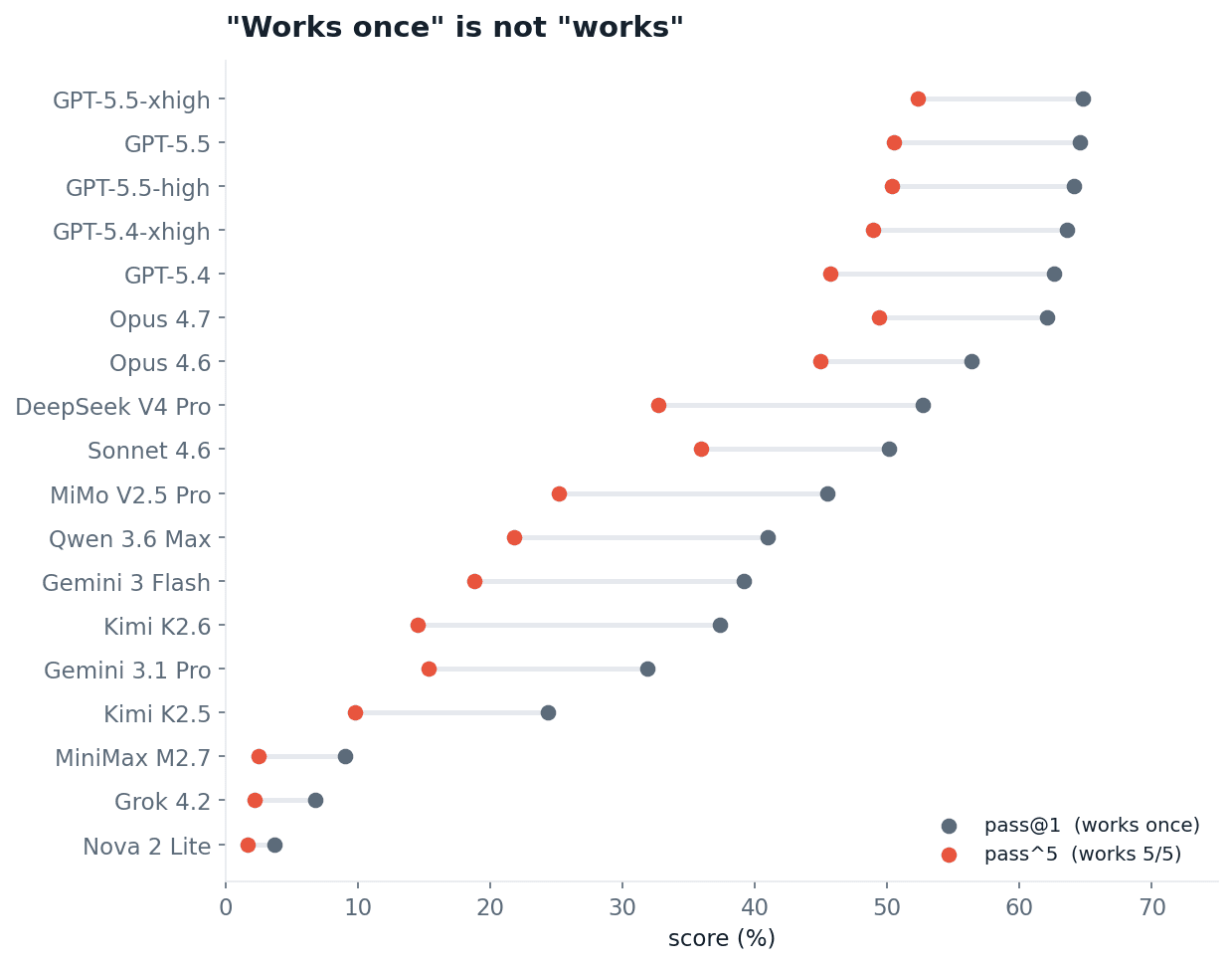
Fig 3. Single-attempt score (pass@1) versus five-of-five score (pass^5). The whole field shifts left when reliability is required.
Takeaway
Public leaderboards report single-attempt scores. The number that matters for production — pass^5, AKA every task passing reliably, not just once — is 11 to 23 points lower for most models. Budget for the lower one.
04. Domains
There is no best model, and the routing is finer than you think
The aggregate leaderboard hides that the ranking is not stable. Break pass^5 out by domain and the order reshuffles in every column. Opus 4.6 wins manufacturing outright and sits mid-pack elsewhere. Sonnet 4.6 is strong on logistics and weak on the rest. The bank HR domain is hard for every model in the study. A single aggregate number is a portfolio average of seven very different tests
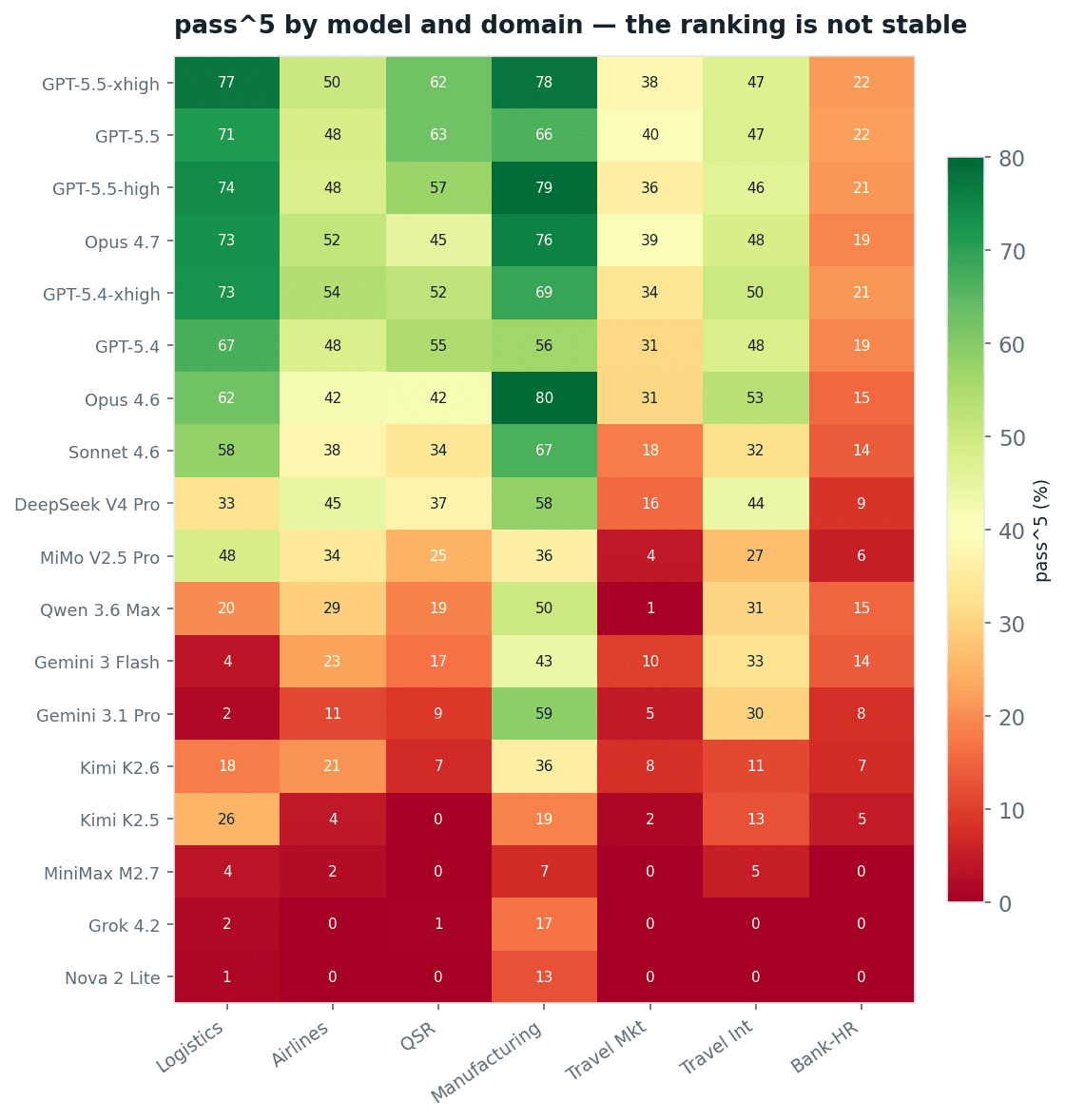
Fig 4. pass^5 by model and domain. The leader changes column to column.
It is tempting to read that as a routing problem: send each domain to its best model. We measured the payoff. Routing every domain to its oracle-best model scores 54.5%, against 52.3% for the best single model. The whole gain from perfect per-domain routing is 2.2 points.
But that small number hides a large one. Run the oracle a level finer. On the transcript panel the best single frontier model reliably solves 48% of tasks; an oracle that picks the best of the top six models for each individual task reaches 69%. That is 21 points of real complementarity between the frontier models, and domain routing captures almost none of it: on the same panel, routing by domain label buys 1.6. The models are genuinely good at different things, but the “things” are not domains. They are individual workflows, individual policy clauses, individual state transitions. A task-level oracle is not a deployable system, you cannot know the right model in advance. It is a measurement: the headroom is real, it is large, and it is invisible to a public leaderboard or any domain-level benchmark. Mapping which model covers which task is exactly what a private, field-level, many-model benchmark is for.
Takeaway
There is no single agent to standardize on. Routing by domain buys about 2 points. The complementarity that matters, 21 points of it, operates at a task level, not by domain. Which model to trust changes workflow by workflow, and only a per-task map can see it.
05. Difficulty
Most tasks are out of reach, and the test knows it
If difficulty were spread evenly, the number of models that solve a given task would cluster around the middle. It does not. The single most common outcome is a task that no model solves reliably. Nearly half of all tasks are solved by two models or fewer, and just one task is solved by all 18.
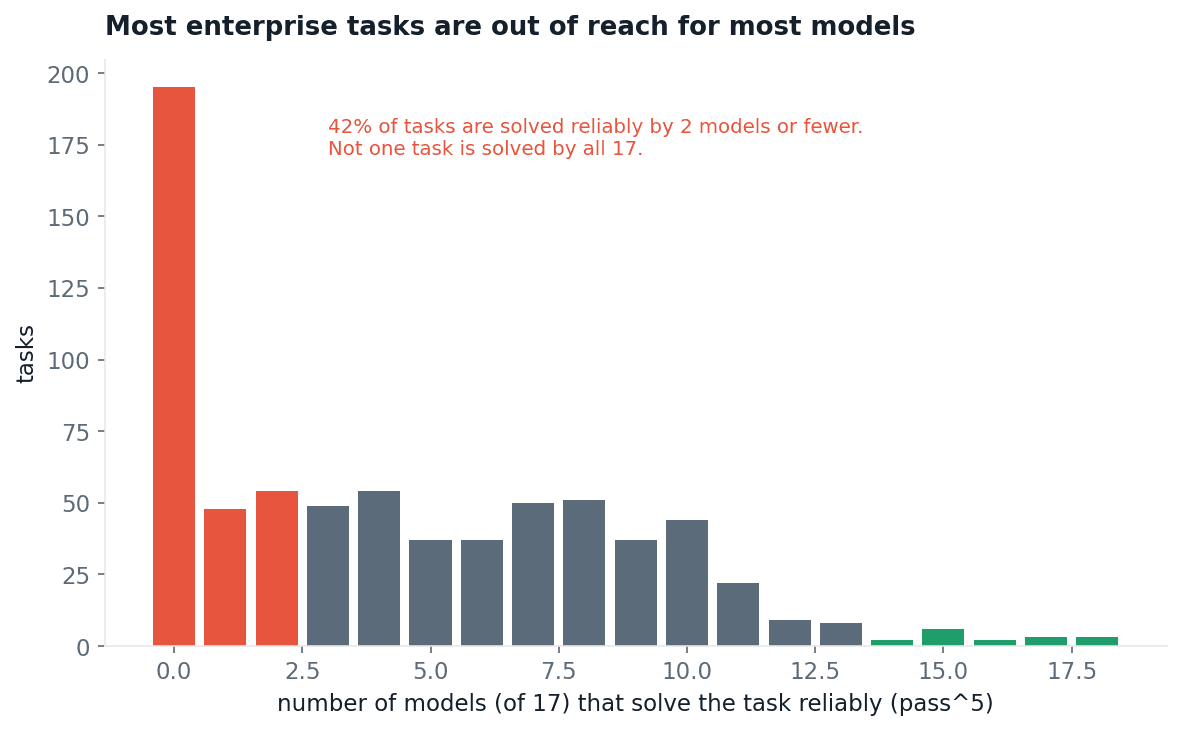
Fig 5. For every task, how many of 18 models solve it reliably. The distribution piles up at the hard end.
That raises a fair question: are the hard tasks just broken? They are not. 97% of tasks are solved by at least one run somewhere, so they are feasible. And the benchmark discriminates: plot each task’s difficulty against how cleanly it separates strong models from weak ones, and 60% of items land above a 0.3 discrimination threshold. The hardest and easiest items separate nobody, as expected; the large middle band is doing real measurement work.
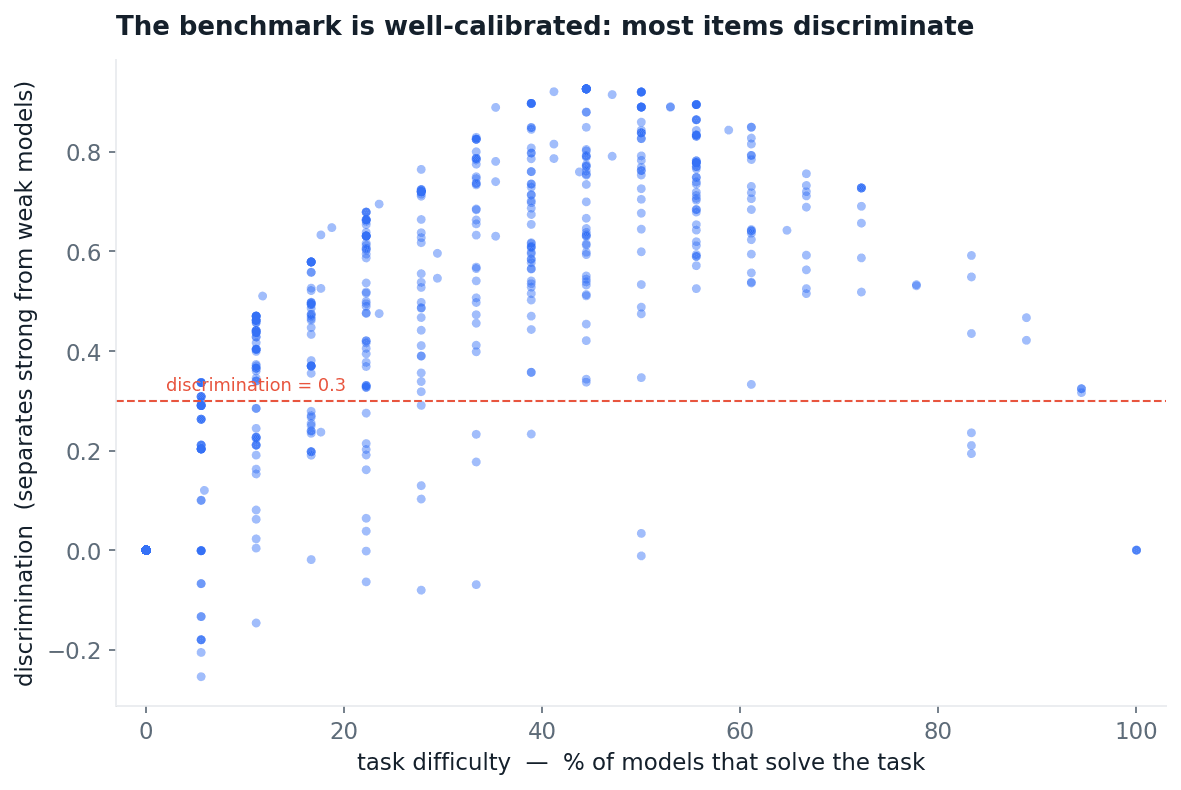
Fig 6. Each dot is a task: its difficulty against how well it separates strong from weak models. The inverted-U is the signature of a well-constructed test.
Takeaway
Close to half of these enterprise tasks are solved reliably by at most one or two of the models tested. A pilot that hand-picks tasks will post a number production will never reproduce. Scope pilots on a random draw, not a curated one.
06. Finding 1
Flakiness is a stable misconception, not noise
The myth
A flaky task is sampling noise. Retry it, vote, raise the temperature, and it averages out.
A model’s task outcomes pile up at the extremes: it passes a task all five times or fails it all five times. But a real fraction sit in between, passing on some runs and failing on others. Those are the flaky tasks.
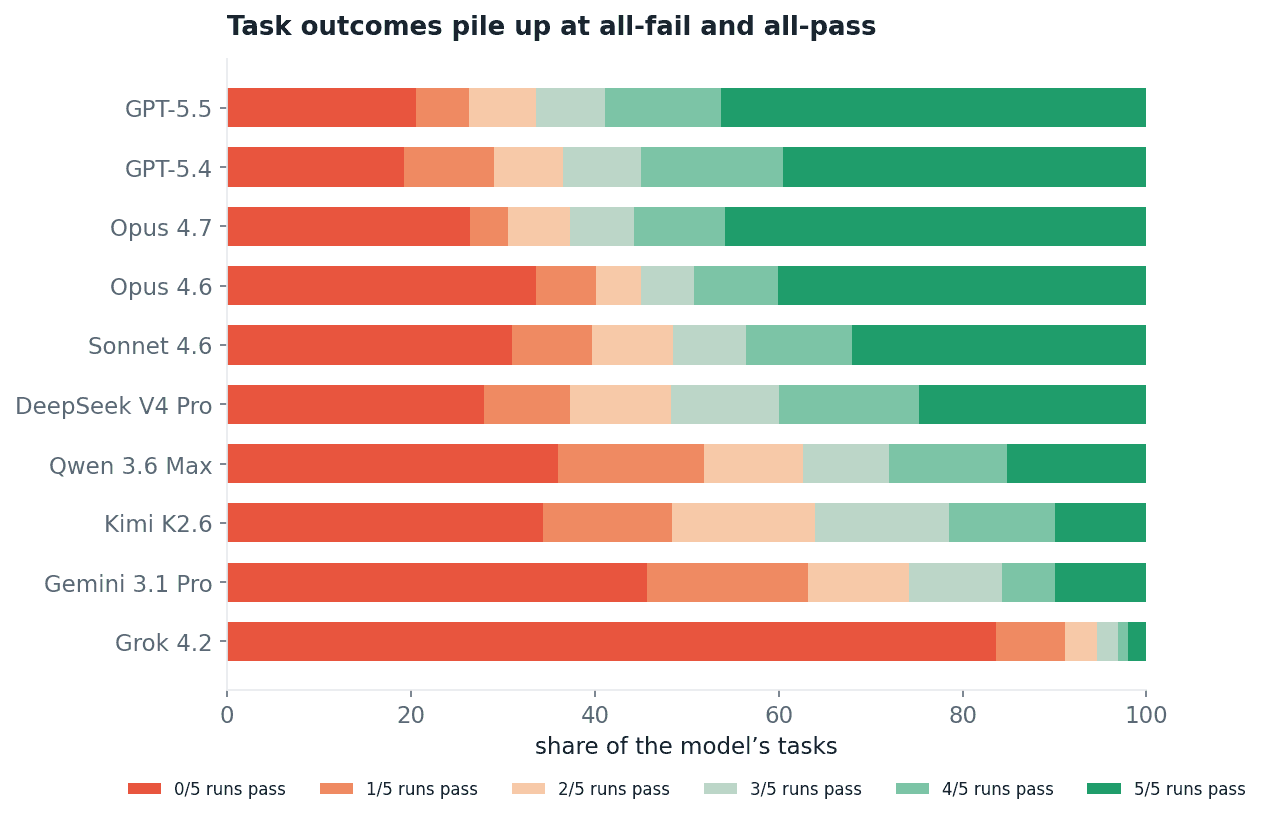
Fig 7. For each model, the share of its tasks that pass 0, 1, 2, 3, 4 or 5 of 5 runs.
We checked what actually happens on the failing runs of those flaky tasks. For each one we took the runs that failed and asked whether they failed the same way.
When a GPT or Claude model fails a flaky task more than once, roughly three times in four every failing run misses the identical field with the identical wrong value.
It is not exploring and it is not noisy. The model has one specific wrong belief about the task, and on the runs where it passes, sampling simply routed around it. The pattern is strongest in the GPT and Claude models, at about three in four, and weakens down the field, as Figure 8 shows: the weaker open-weight models fail less consistently, nearer one in two. The misconception is sharpest exactly where capability is highest.
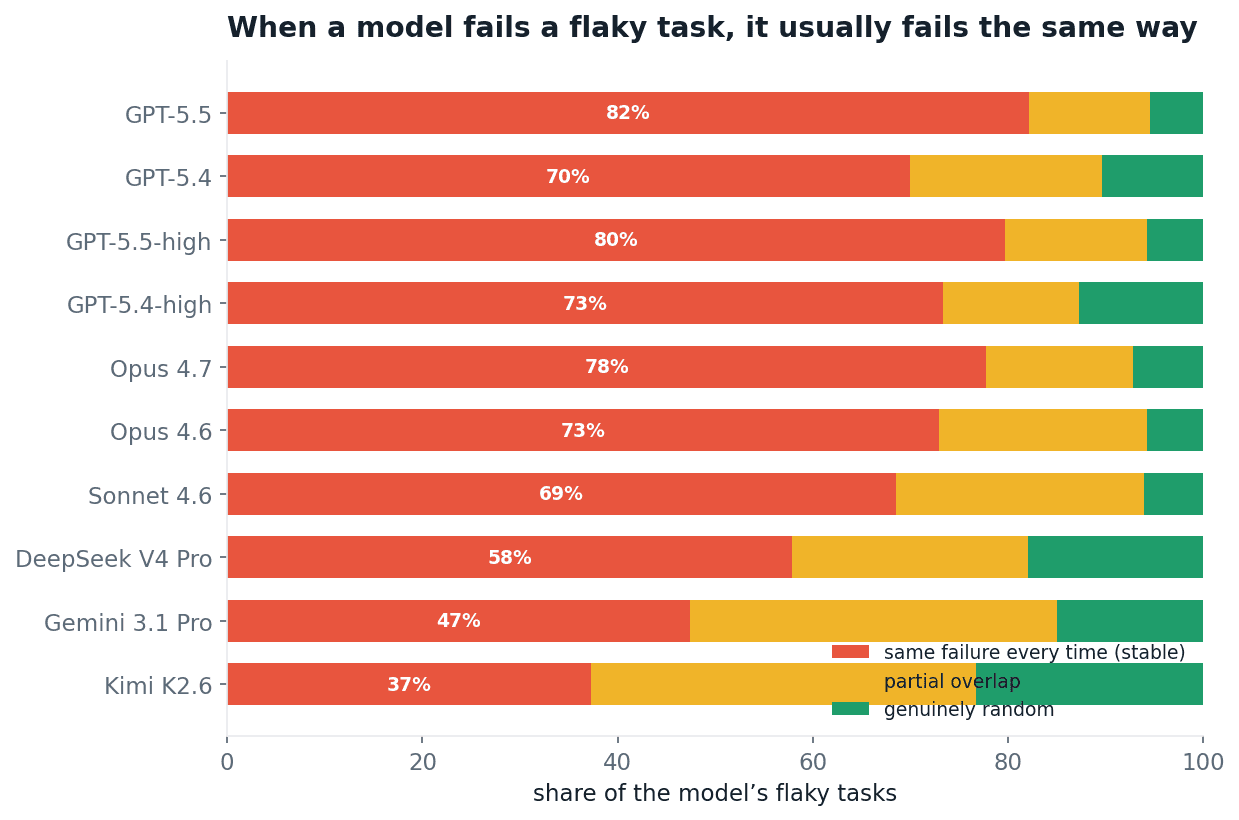
Fig 8. For each model's flaky tasks (those with at least two failing runs, so "same way" is a real test), whether the failing runs fail the same way. Red: an identical field error in every failing run. The GPT and Claude models sit highest; the rate falls off for the weaker open-weight models.
Here is one task, run five times. A guest reports that a rental listing advertised three bedrooms and the property had two. GPT-5.5 has to process the case and record the refund.
Exhibit · GPT-5.5 · travel-marketplace task SD-019 · 5 runs
In all five runs the agent issues the identical $313 refund and writes near-identical case notes. The only thing that changes is one field — how it classifies the refund:
Run | Completeness | Status |
|---|---|---|
Run 1 | Partial | Fail |
Run 2 | Full | Pass |
Run 3 | Full | Pass |
Run 4 | Partial | Fail |
Run 5 | Full | Pass |
The action is deterministic. The judgment is a weighted coin. The model does not know, from the policy, whether this case is a full or a partial refund, so the wrong answer is always the same wrong answer.
Takeaway
Retries and majority-voting do not fix a stable misconception. A retry is the same loaded coin, not a fresh roll. Reliability has to be trained in, not sampled in after the fact.
07. Finding 2
The misconception is shared, and it carries a fingerprint
The myth
Unreliability is a weak-model problem. The frontier leader is solid; just pick a better model.
The blind spot is not the model’s alone. We took every pair of frontier models from different labs that both failed the same task and compared how they failed. They share at least one identical field-level error — the same field set to the same wrong value — 74% of the time. Their single most common error is identical 49% of the time. The honest test is against a null: take the same two models on two unrelated tasks in the same domain, and those figures fall to 32% and 18%. The agreement on a shared task is roughly 2.5x what chance would produce.
Figure 9 makes the structure visible. Each cell is the correlation between two models in which tasks they solve. The top-left block, the GPT and Claude models, is one warm square: they succeed and fail together.
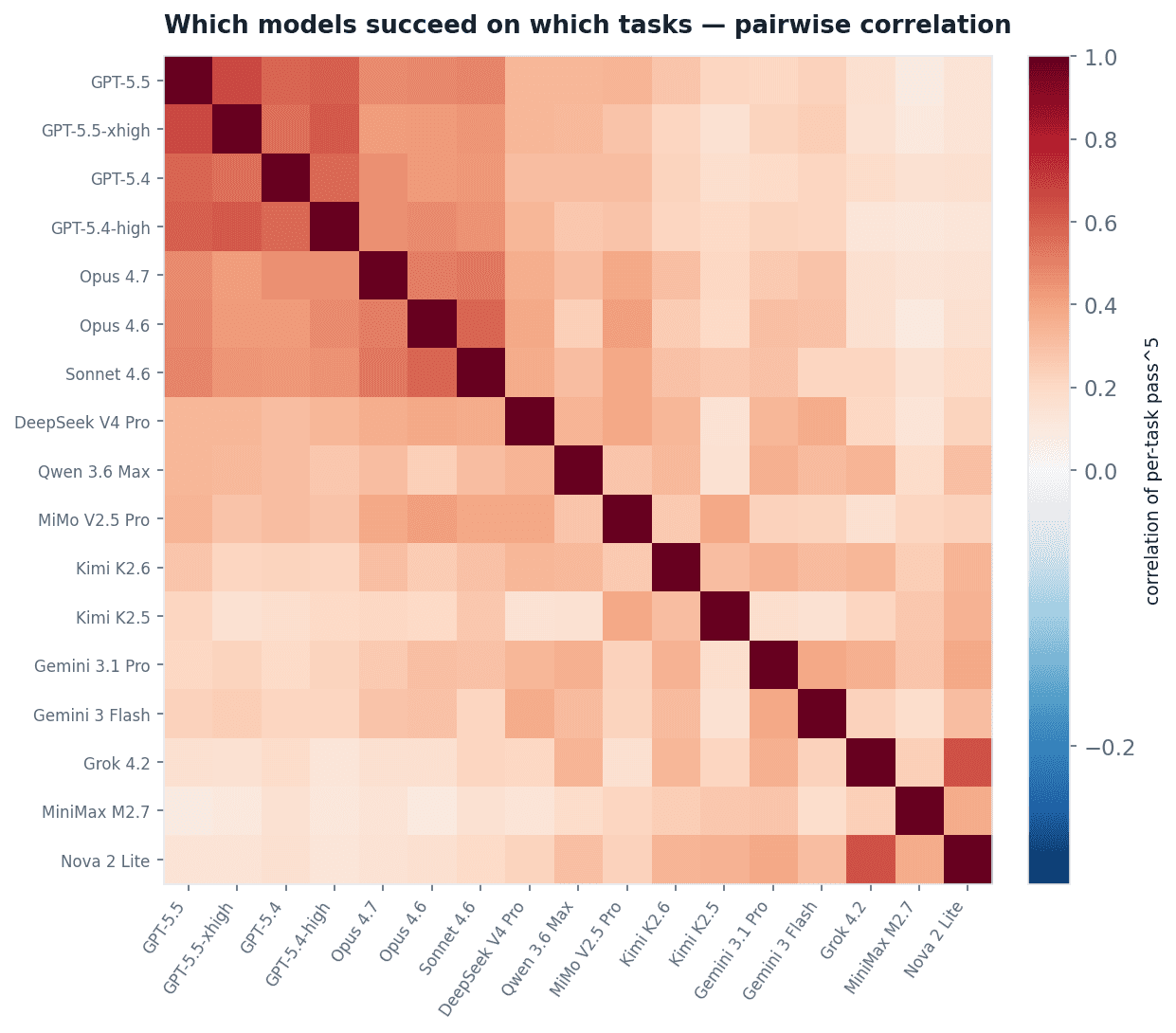
Fig 9. Pairwise correlation of per-task pass^5 across 18 models. Red means the two models solve and fail the same tasks. The frontier cluster is visually one block.
Models from different labs are not making independent mistakes. They fail the same tasks, the same way, with the same wrong value.
When models from different labs converge on the same wrong judgment, far above chance, the error is not idiosyncratic to one model. Whether that traces to shared training data, shared feedback regimes, or genuinely ambiguous tasks is the open question. What is certain is that it is structural, and that a singlemodel benchmark cannot see it at all.
Now push on that. If two models make the same mistake, the mistake is a fingerprint. Score every pair of the 18 models by how often their dominant error on a co-failed task is the identical wrong field value, and a structure appears. But the raw score has a confound that has to be removed before it can be trusted: a strong model fails rarely, and when it does the error tends to be a generic one many models share, so raw similarity has a hub. Every weak model’s nearest raw twin comes back as Opus 4.6, not because they were built alike but because Opus 4.6’s errors are common. Raw similarity measures strength, not lineage.
The fix is to residualize. Double-centre the match matrix: subtract from each pair what each of its two models shares with the field on average, and keep only the excess. What survives is how alike two models fail beyond their individual baseline. After residualizing, the result is clean: every same-lab model pair stays positive, eleven of eleven. The four OpenAI configurations match each other +24 to +33 points above baseline (two of those pairs are one model run at two reasoning settings and should match; the genuinely cross-version OpenAI pairs stay clearly positive too); the Opus 4.6 and Sonnet 4.6 pair +17; the two Gemini models +14. The method recovers the known lab families with no labels given. That is the validation: a model’s lab is legible in the shape of its mistakes.
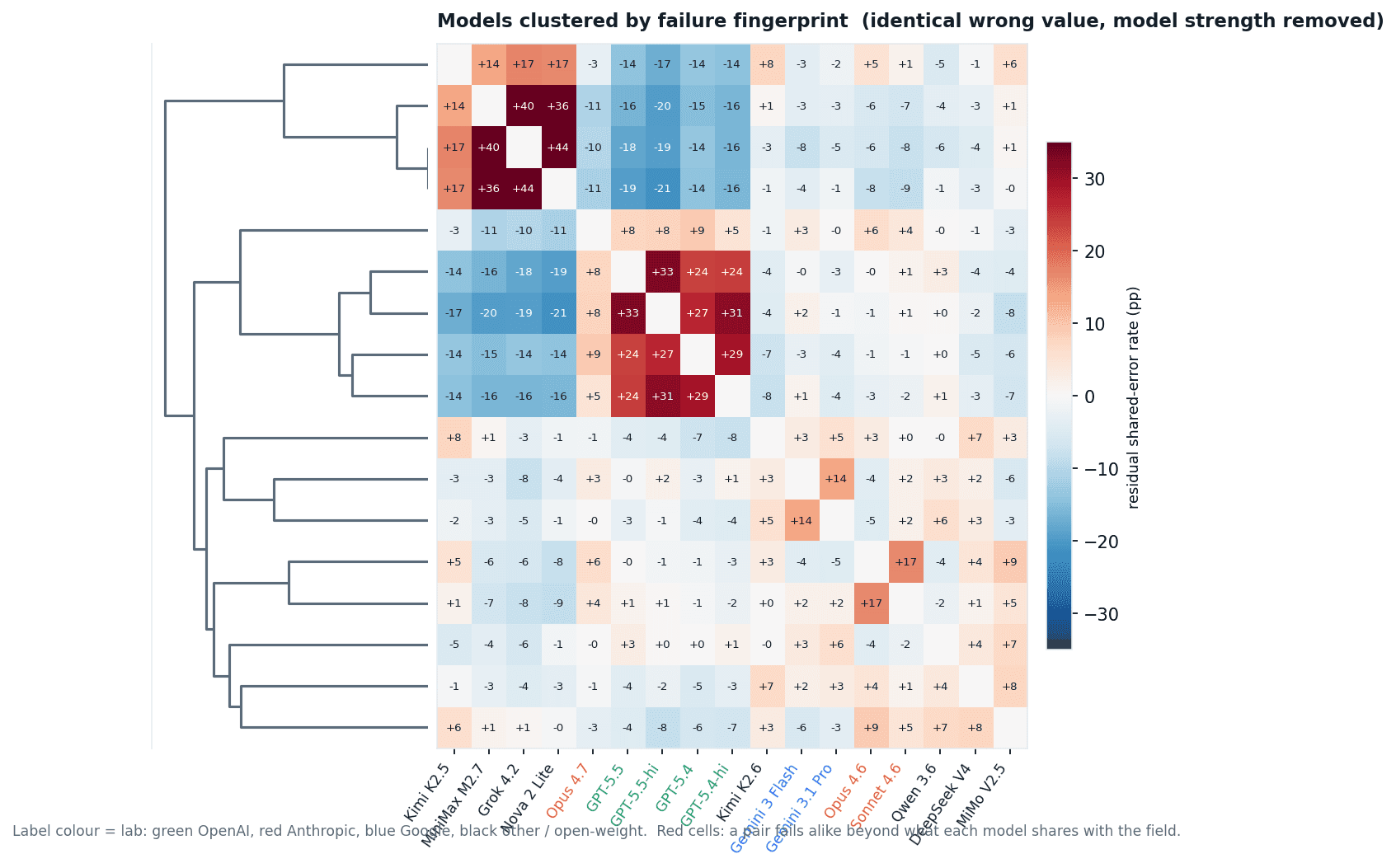
Fig 10. The 18 models clustered by failure fingerprint: how often a pair produces the identical wrong field value, with model strength residualized out. Label colour is the lab. Red cells are pairs that fail alike beyond their baseline; the same-lab blocks light up on the diagonal. residual_fingerprint.py.
You can read a model's lab off the shape of its mistakes. And the fingerprint does not split the field by capability. It splits the Claude line in two.
The first surprise is internal to one lab. After residualizing, Opus 4.7 does not sit with Opus 4.6 and Sonnet 4.6. It sits with the GPT cohort: among cross-lab pairs, GPT-5.5's strongest failure affinity is Opus 4.7, and Opus 4.7's own strongest cross-lab affinities are all GPT models. The newest Claude fails enterprise judgment more the way GPT does than the way the Claude generation before it did.
The second surprise is where Opus 4.6 and Sonnet 4.6 sit instead. Condition on the task directly: score a pair by how often they produce the identical wrong value, minus how common that value is among every other model that failed the same task (distill_cohort.py). On that test, four open-weight models from Chinese labs, DeepSeek V4 (DeepSeek), MiMo V2.5 Pro (Xiaomi) and Kimi K2.5 and K2.6 (Moonshot), have their highest cross-lab agreement with the Claude 4.6 generation: +7.8 points on average, against -4.4 with the GPT cohort and roughly zero with Opus 4.7. The GPT models, run as a control, do the opposite: their home is GPT, and the Claude 4.6 generation is their weakest tie.
That score carries a bias that has to be cleared before it means anything. Models of similar capability fail more alike for reasons that have nothing to do with lineage, and across all 136 model pairs the score does track the capability gap (correlation -0.61). The Claude 4.6 generation sits at a middling pass^5, close to the four Chinese models; the GPT cohort sits well above them. So the honest question is whether the Claude affinity is larger than the capability match alone would produce. It is. Regress excess agreement on the capability gap across every pair that includes one of the four models, and a Claude-4.6 partner still adds about ten points on top of the capability-gap line (cohort_control.py). That estimate rests on only two Claude-4.6 anchor models, so we read it as a point estimate, not a precise significance claim. Matched the other way, each of the four agrees with the Claude 4.6 generation nine to nineteen points more than with non-Claude models of the same capability. The strength confound is real. It does not explain the result.
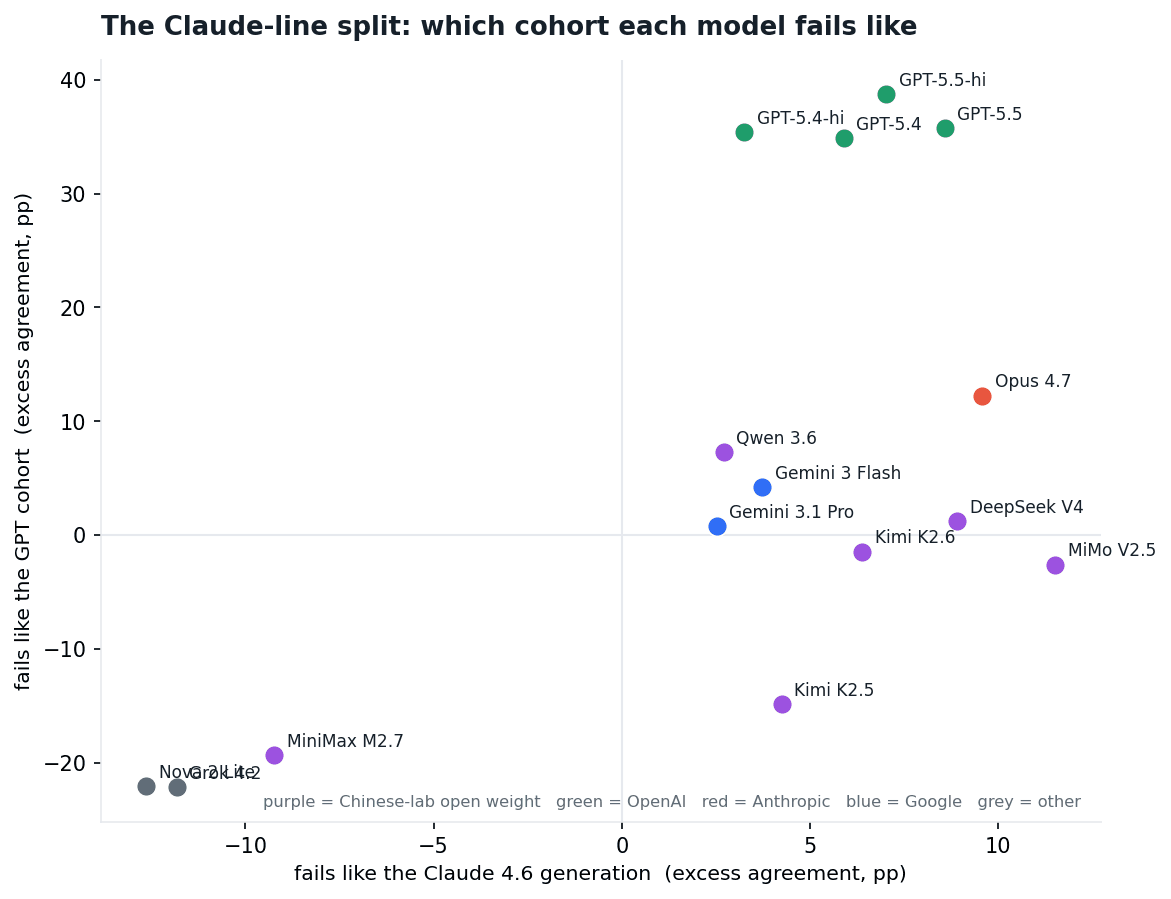
Fig 11. Each model placed by task-conditioned excess agreement with the Claude 4.6 generation (horizontal) and with the GPT cohort (vertical). The GPT models sit high; Opus 4.7 sits with them. Four Chinese-lab open-weight models sit far to the right and low. Qwen 3.6 does not. The Claude 4.6 anchor models are omitted by construction. distill_cohort.py, cohort_control.py.
What the result is, and is not. It is not universal: Qwen 3.6 does not follow the pattern and sits nearer GPT. The effect is moderate, about ten points after the control, not a smoking gun. And the test cannot name a cause. Training on Claude-generation outputs would produce this pattern; so could training data that substantially overlaps with Claude's. A field-level benchmark can show the structure, four Chinese open-weight models that fail enterprise judgment more like one particular Claude generation than like the GPT frontier, and it can show the structure is not explained by the capability gap. It cannot, on its own, say how the structure got there, and we do not.
Takeaway
For deployment: multi-model fallback is not a safety net., A different-lab backup fails the same task the same way, and the fingerprint says some of those "different" labs are closer than their logos suggest.
For the field: a residualized, field-level failure fingerprint is an audit instrument, it recovers lab families unsupervised and then shows structure, a Claude generation split, a cross-lab cluster, that capability scores cannot.
08. Finding 3
The two kinds of failure, and why upgrades fix only one
The myth
Whatever is broken today, the next model version will fix. Reliability rides the release cycle.
A new model version arrives as a single better number. GPT-5.4 to GPT-5.5, Opus 4.6 to Opus 4.7: the leaderboard moves up and the release notes say it is smarter. At the task level it is not one number going up. It is two different things happening, and only one of them is progress.
Start with what an upgrade quietly costs. Take every task the old version passed reliably, and check the new version on the same task. Across the four clean version pairs in the run, every single upgrade reliably broke tasks its predecessor reliably passed, between 0.6% and 2.0% of the shared task set, with GPT-5.4-hi to GPT-5.5-hi the one case that broke exactly as many as it fixed, fourteen each way. A version bump is never a strict improvement. It is a trade, and the regressions are invisible to anyone reading the headline score.
Now the more important half: what an upgrade fixes. Sort the old version's failures into two kinds. A flaky cell is a coin-flip, a task it passed on some runs and failed on others. A hard failure is a task it failed on all five runs. These are not two points on one difficulty scale. The next version treats them as different things.
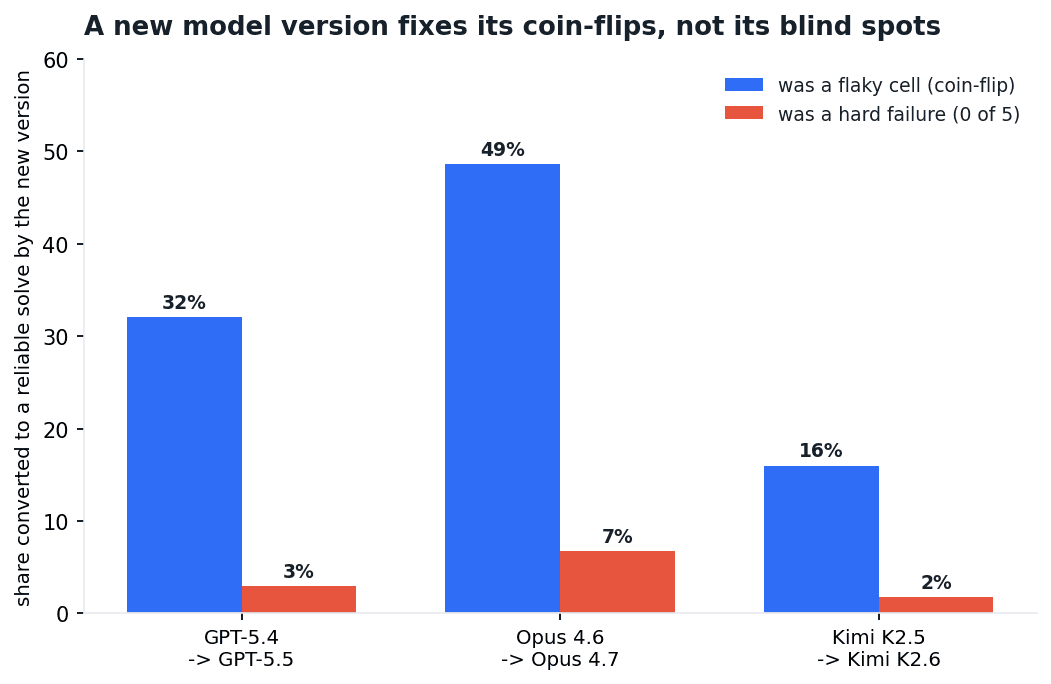
Fig 12. For three of the four version upgrades (the GPT-5.4-hi to 5.5-hi pair is omitted from the chart): of the old version's flaky cells (coin-flips) and its hard failures (0 of 5), the share the new version converts to a reliable solve. The new version fixes coin-flips. It almost never fixes a hard failure. version_delta.py.
The new version converts the old version's coin-flips into reliable solves 16% to 49% of the time. It converts the hard failures into reliable solves between 1% and 7% of the time. A model generation closes the gap on tasks the previous generation already half-knew. The tasks it had no grip on at all, it still has no grip on. The wall does not move.
A new model version fixes its coin-flips. Its blind spots survive the upgrade almost untouched.
The reasoning dial does the same thing, and it is faster to see because it holds the model fixed. Compare GPT-5.5 against GPT-5.5 at high reasoning effort, the same weights, more thinking. More effort rescues 71 tasks and breaks 50, a near wash on which tasks pass. And on the tasks both settings still fail, the dominant field error is identical 83% of the time, 74% for the GPT-5.4 pair. More reasoning is not a different mind arriving at the problem. It is the same mind given another go at the same coin-flips. It changes which way they land. It does not change the misconception underneath.
This is Finding 1 seen from a second angle. A failing run, a retry, a reasoning setting, a version upgrade: each is another sample, and a model's stable misconceptions are invariant to all of them. The frontier has been getting better at the coin-flips. It has not been getting better at the blind spots, and nothing in the normal toolkit, more retries, more reasoning, the next checkpoint, reaches them.
Takeaway
You cannot blind-swap a model version: every upgrade silently regresses a specific, enumerable set of tasks, and only a private repeated-run benchmark will tell you which.
A task your current model hard-fails is not a bug the next release is likely to fix. If a workflow matters, its genuinely unsolved part needs a real fix, not the next checkpoint.
09. Finding 4
RAG is not enough: the failure is policy-to-state translation
The myth
The agent just needs the governing policy retrieved into its context. Wire up RAG and the judgment follows.
We graded every field of every failed trial and split fields into two kinds. Core functional fields are IDs, amounts, quantities, references: the mechanics of the action. Business-rule fields are status, priority, escalation path, disposition: the judgment a policy dictates.
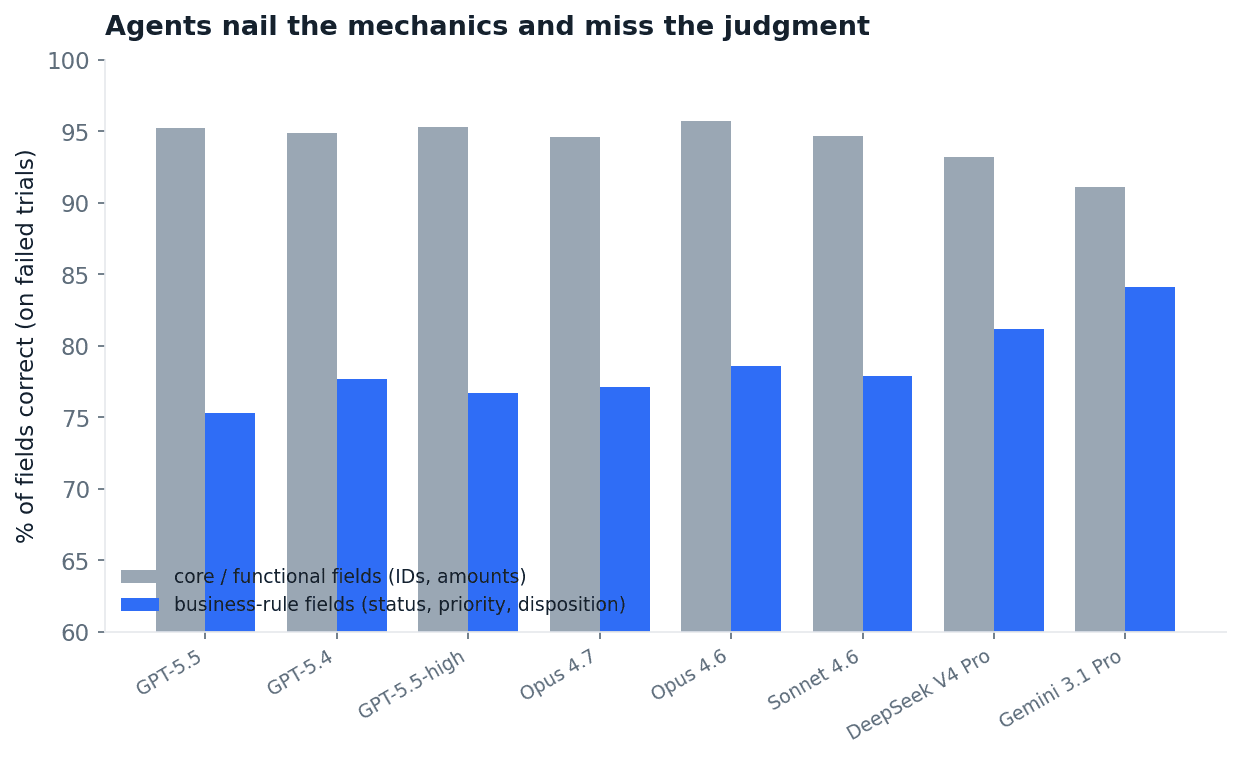
Fig 13. On failed trials, accuracy on the records the agent built correctly. ~93% of functional fields right, ~77% of business-rule fields. Computed by field_accuracy.py.
Even on tasks they fail, frontier models get the mechanics almost right. They call the correct tools, create the correct records, move the correct money. They fail on the judgment layer, three times more often. The mechanics even hold up under stress: comparing runs within the same task, a run that hit a failed tool call passes at almost the same rate as a clean run, the gap never exceeding about six points for any model (tool_errors.py). A tool error is a symptom of a hard task, not the cause of the failure. Figure 14 shows it from the field side: the most-missed field in the study is status, followed by exception code, priority, type and tags.
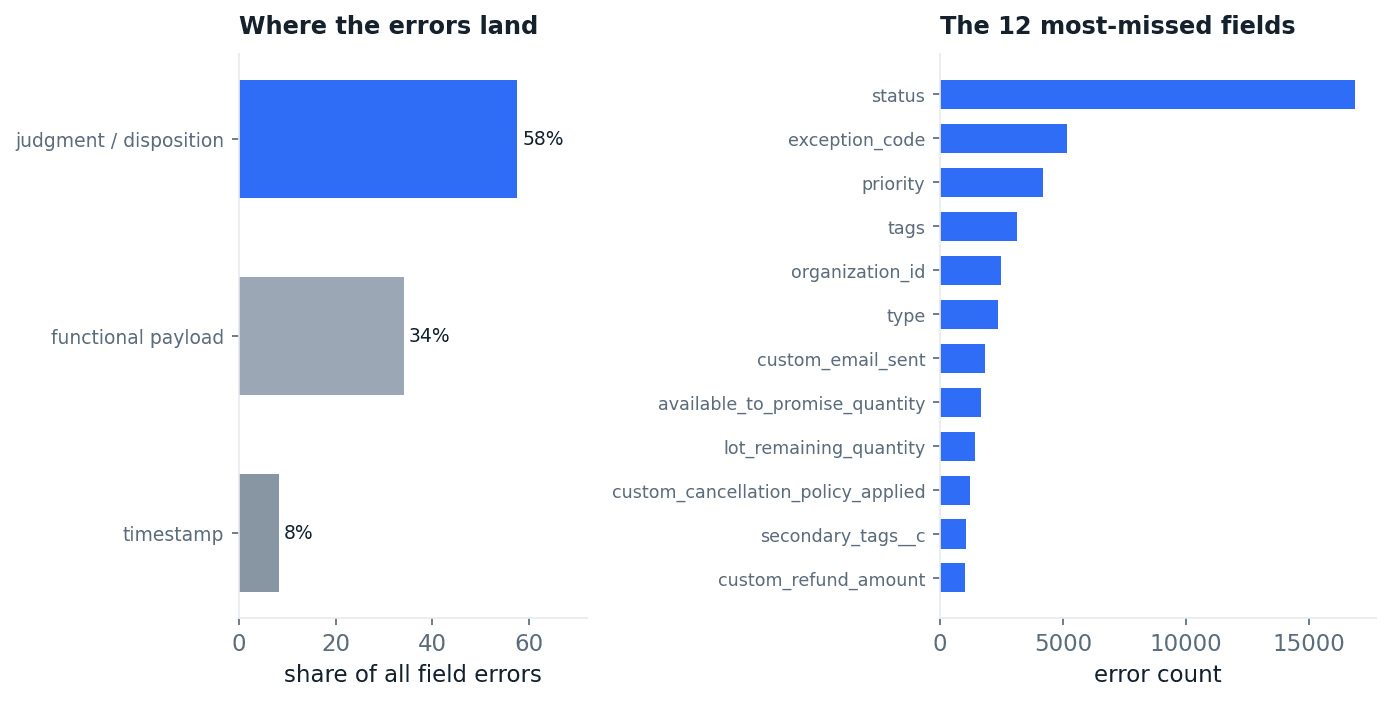
Fig 14. Left: where field errors land. Right: the 12 single most-missed fields. The judgment layer dominates.
And the policy is not missing. The agent can query the governing policy on demand, and it helps: within the same task and the same model, runs that queried the policy passed about 9 points more often than runs that did not (policy_lift.py). Retrieval is real signal. But it is not the bottleneck. Among runs that queried the policy and still failed, 62% of the field errors are business-rule fields, status, exception code, priority, refund type, email-required flags (policy_lift.py). The model retrieved the rule and still wrote the wrong system state. RAG gets the rule into context. It does not turn the rule into the right API writes, and that translation is where enterprise agents break.
Takeaway
RAG is necessary, not sufficient, and the data says by how much: retrieving the policy lifts pass rate about 9 points, but on the runs that retrieved it and failed anyway, 62% of the errors are business-rule state, not mechanics. The bottleneck is not getting the rule into context, it is turning the rule into the right database write. A production agent needs a policy-to-action layer on top of retrieval: enumerate the required state changes before writing, constrain each field to its legal values, and validate the final workflow state externally. "The agent searched the policy" is not a control.
10. Finding 5
The hardest tasks are not the most complex
The myth
The tasks no model can do are the long, many-step, complicated ones. Hard means big.
If that were true it would at least be a tractable kind of hard: buy more context, more steps, more compute, and grind the long tasks down. We binned every task by how many models solve it and measured the work each tier takes.
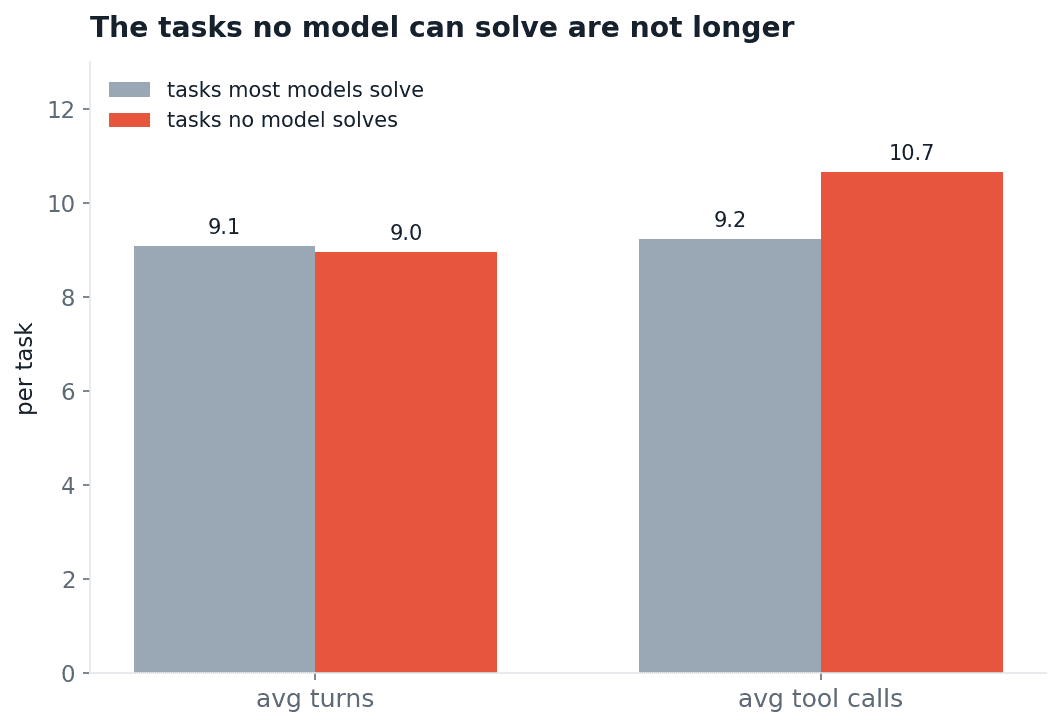
Fig 15. Tasks most models solve versus tasks no model solves, by the work one run takes. The unsolvable tier runs the same length, about 9 turns either way.
A task no frontier model can do reliably takes about 9 turns, the same as a task most models solve. The wall is not length and not step count. The hardest tasks are not bigger, they ask for a harder judgment.
Takeaway
You cannot triage risk by task length or step count. The dangerous tasks look exactly like the easy ones from the outside. Triage has to be by policy complexity, not workflow length.
11. Finding 6
The agent cannot tell that it failed
The myth
If the agent is unsure or in trouble, it will tell you, or at least slow down and work harder.
If the error is stable, can the model at least detect it? We measured, for every model, how often its final message to the user claims the task is done, split by whether the trial actually passed or failed.
A frontier agent claims success at almost the same rate whether it succeeded or not. Sixteen of the eighteen models differ by under five points between passed and failed runs, and the direction is inconsistent.
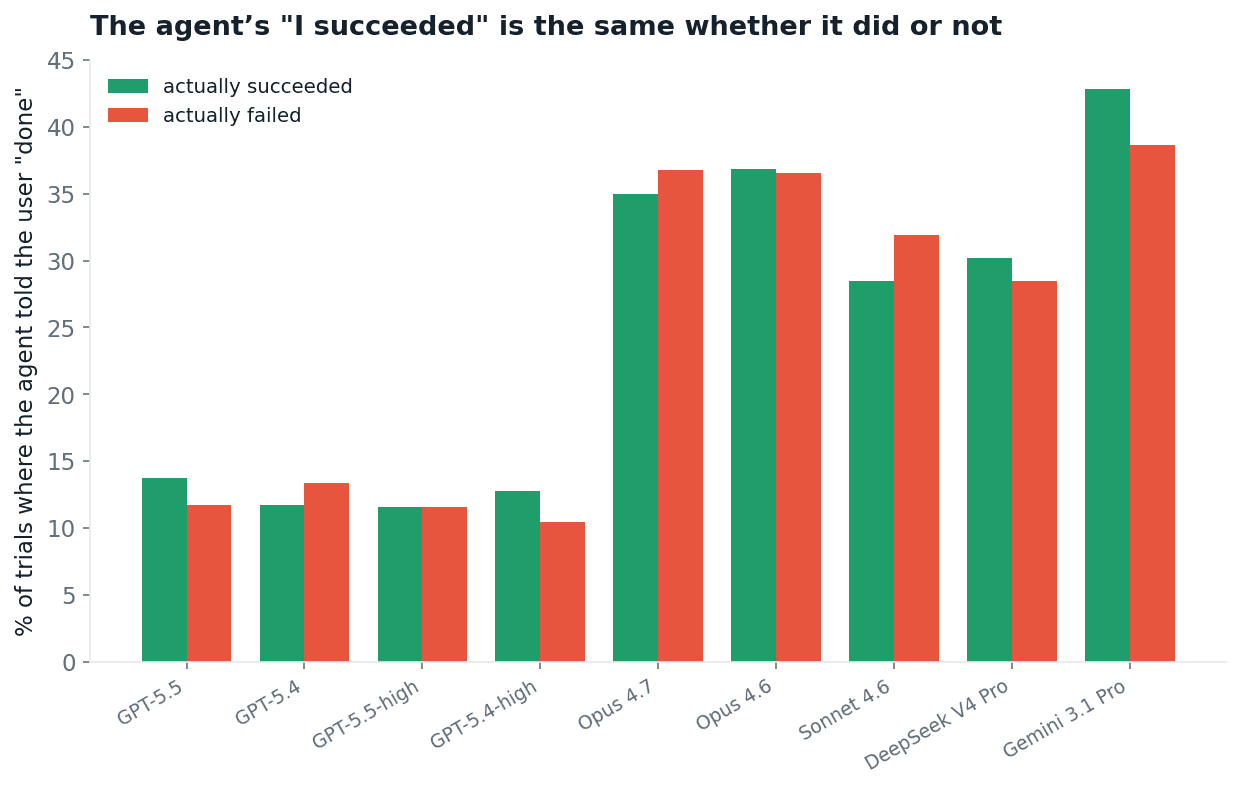
Fig 16. How often each model tells the user the task is done, on trials it passed (green) versus trials it failed (red). The bars are the same height.
The gap between passed and failed runs is uninformative. The absolute level varies fourfold, but it has to be read carefully. When a GPT model fails a task, its final message still claims success about 12% of the time; when any other lab's model fails, it claims success roughly three times as often, 28% to 45%, Qwen 3.6 highest. GPT looks better by this measure, but for the wrong reason. It does not claim success more accurately — it simply claims success less often in general, on passed and failed runs alike. Every other lab's models narrate 'done' freely on 28% to 45% of runs regardless of outcome. GPT does the same thing, just quietly. MiniMax M2.7 is the lone low outlier among them, and it solves almost nothing. Figure 17 ranks the failed-run rate for all eighteen.
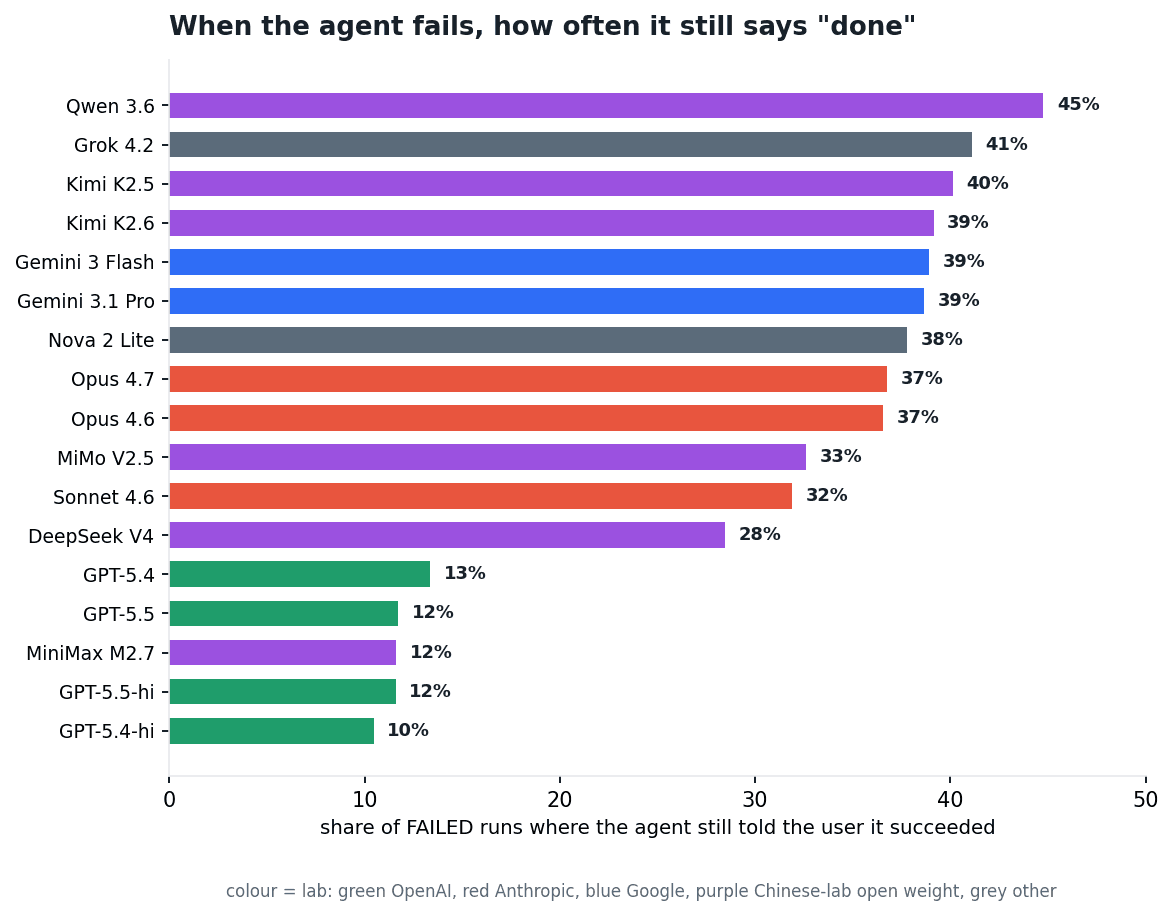
Fig 17. Share of failed runs where the agent's final message still told the user it had succeeded. Bar colour is the lab. The OpenAI models sit near 12%; every other lab sits roughly twice to four times higher. false_success.py.
A non-GPT frontier agent hands back a wrong answer wrapped in "done" on more than a third of its failures. Either way the wrapper is decoration: within every model it barely moves between a pass and a fail, so no model's "done" tracks the result in front of you.
It is not only what the agent says. It is what it does. A model that sensed it was in trouble would slow down, take more steps, search more. It does not. Across the frontier, a model spends the same number of turns on tasks it fails as on tasks it passes, within a turn either way.
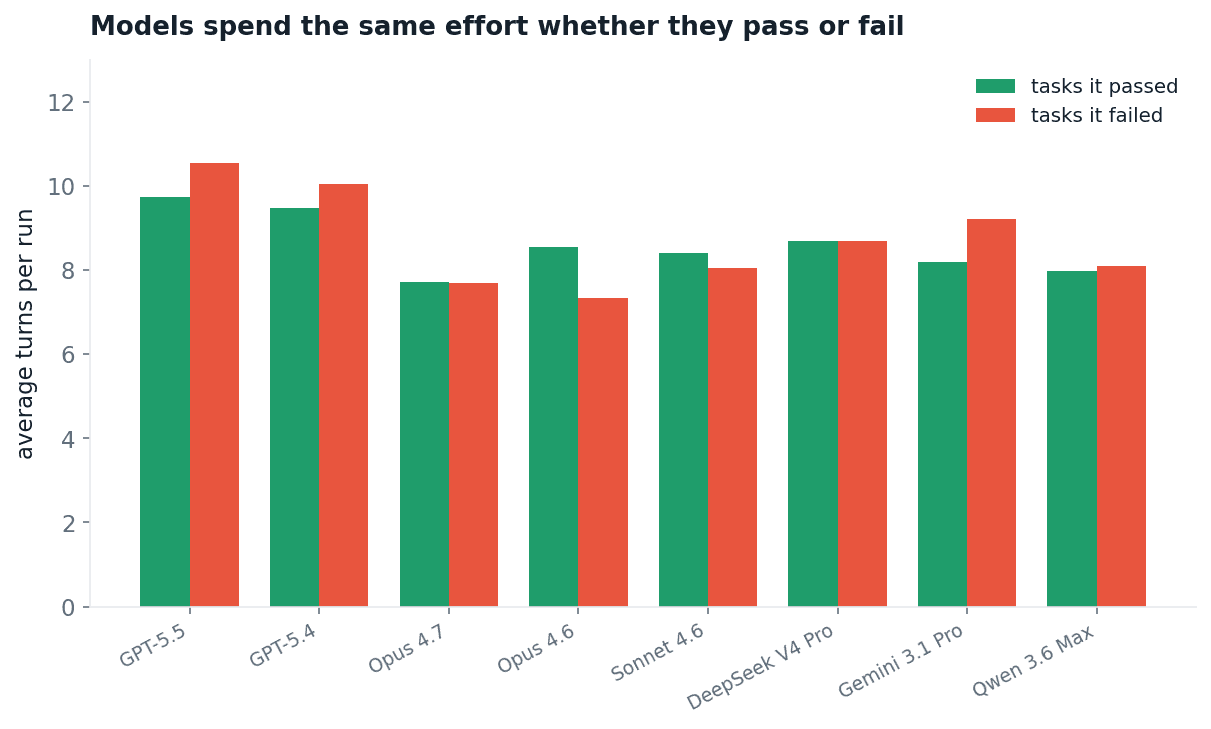
Fig 18. Average turns per run, on tasks the model passed versus tasks it failed. No effort signal: the agent does not work harder on the tasks it is getting wrong.
The agent is not lying. It has no working model of what "done" means for the task, so it cannot evaluate itself, cannot tell a hard task from an easy one, and defaults to confident.
Takeaway
Never route on an agent's own "done." It is uncorrelated with truth and the agent shows no behavioural tell. Every task needs an external, deterministic check before its result is trusted.
12. Finding 7
When the frontier is wrong, it is wrong in one direction
The Myth
Wrong answers are random. They scatter both ways — too much caution sometimes, not enough other times — , so in aggregate they wash out.
The errors so far are stable, shared and invisible. They have one more property, and it is the one with the sharpest operational edge: a direction. We took every judgment field a model set to the wrong value and asked which way it missed. Toward more alarm, a higher priority, an exception flag raised, an escalation logged, or toward less, the calmer and more routine value.
It is not symmetric. Across every directional judgment field, 65% of the errors move toward the calmer state; with the 187 consensus-suspect tasks removed, 62%. Narrow it to the fields that exist specifically to surface a problem to a human, exception codes, exception statuses, escalation tags, required notifications, and the skew sharpens to 74%. When a task required the agent to send a customer notification and it got that field wrong, 86% of the time the error was simply not sending it.
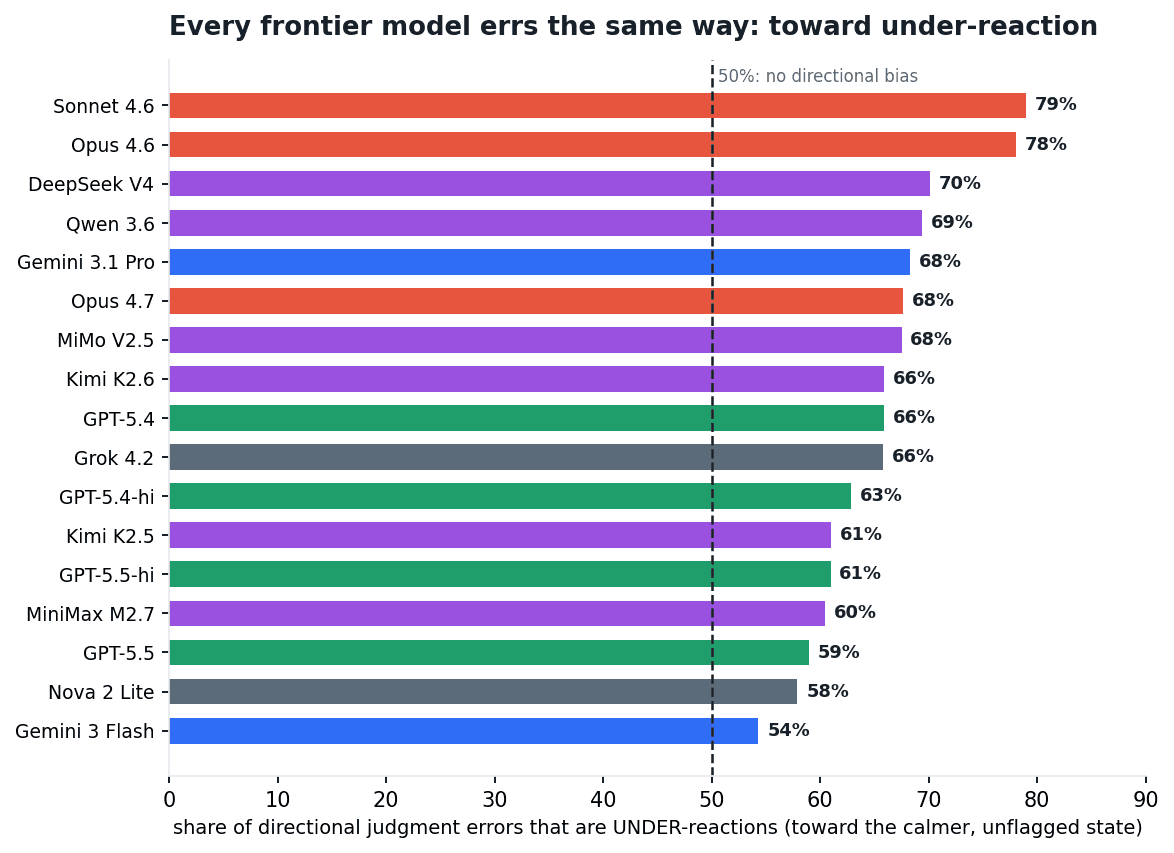
Fig 19. For each model, the share of its directional judgment errors that are under-reactions, moving toward the calmer, unflagged state. Every one of the 18 models sits above the 50% line. under_reaction.py.
" When a frontier agent gets a judgment call wrong, it does not raise a false alarm. It goes quiet: it downgrades the priority, drops the escalation tag, leaves the exception unflagged. "
And every model does it. All eighteen lean the same way, from 54% to 79% under-reaction; not one errs toward over-reaction on balance. A bias this universal is not one lab's quirk. The most plausible reading is uncomfortable, and it is the assistant objective. Models are post-trained to be helpful, to resolve, to reassure, to make the user's problem go away. In a chat that is a virtue. In an enterprise workflow, "flag an exception," "escalate to a human," "send the compliance notice" all read as friction, as not resolving. The same training that makes a model pleasant to talk to appears to make it under-react when it is running operations.
Takeaway
An agent that errs toward false alarms is annoying and self-correcting, a human notices the noise. An agent that errs toward silence is not: the unraised exception, the unsent notification, the un-escalated case produce no signal at all until the consequence arrives. Monitor for what the agent did not do, not only for what it did wrong.
13. Finding 8
Some models know when to quit. Most do not.
The Myth
Models differ in capability and nothing else. Pick the one with the highest score and you are done.
One behaviour separates the model families cleanly. When a task goes badly, an agent can either keep going and produce a confident wrong answer, or stop and escalate to a human. The Claude models escalate on 6 to 8% of their failures. The GPT models escalate on 1% or less. GPT-5.5 explicitly gave up just eight times in the entire study.
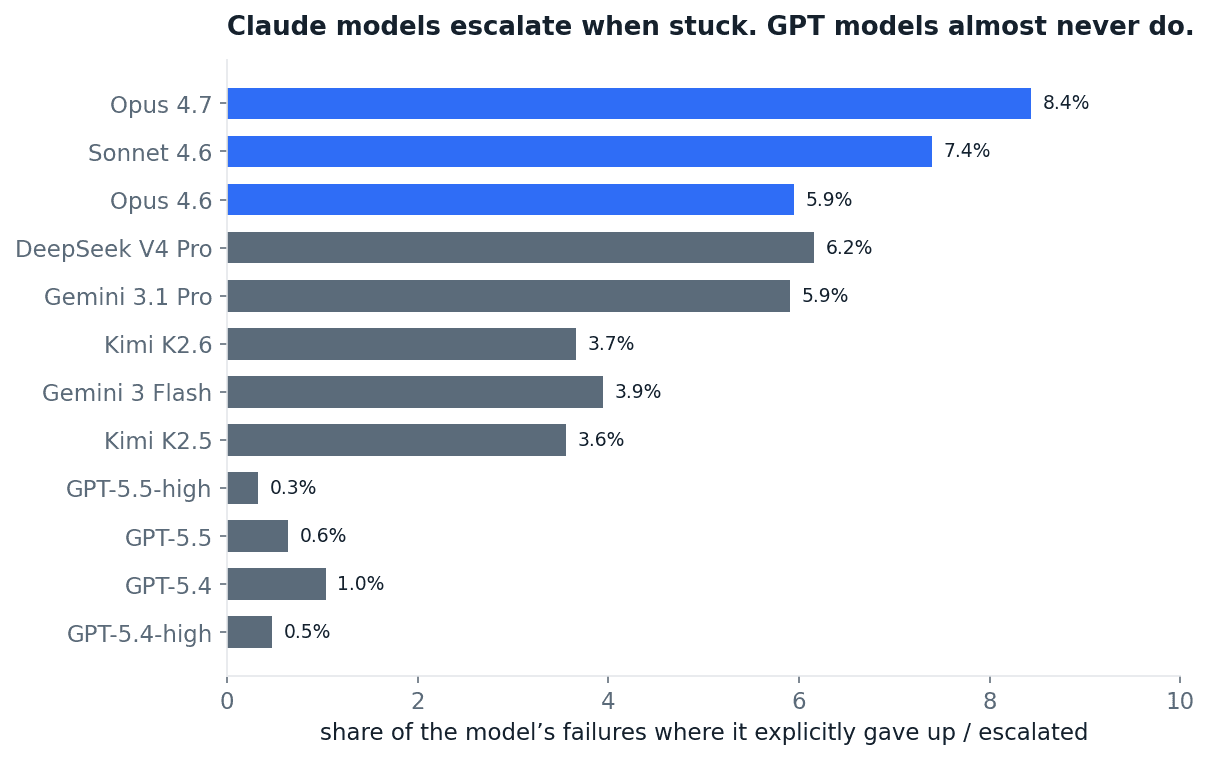
Fig 20. Share of each model's failures where it explicitly gave up or escalated rather than pushing through.
Escalating could just be a weaker model bailing on tasks it should win. It is not. When a Claude model gives up, the task is genuinely hard: on average only about 8% of the other models solve it five-for-five (escalation.py). It is walking away from near-impossible work, not winnable work. GPT, on the rare occasion it gives up, picks slightly easier tasks, around 13%, but the gap that matters is the rate, not the aim: GPT almost never escalates at all. The Claude families have a crude but real sense of their own limits. GPT has almost none, and in an enterprise setting "escalate to a human" is frequently the correct action, not a loss.
Takeaway
An agent that escalates near-impossible tasks is more deployable than one that attempts everything. If your workflow has a human fallback, weigh a model's willingness to use it, not just its raw score.
14. Failure modes
Strong models fail silently
The weak tail fails loudly: MiniMax M2.7 spends 64% of its failures stuck in a loop; Grok 4.2 fumbles tool-call schemas. You can see those failures happen. The frontier does not fail loudly. For GPT and Opus, more than 90% of failures are silent: a clean run, a confident sign-off, and a wrong end state.
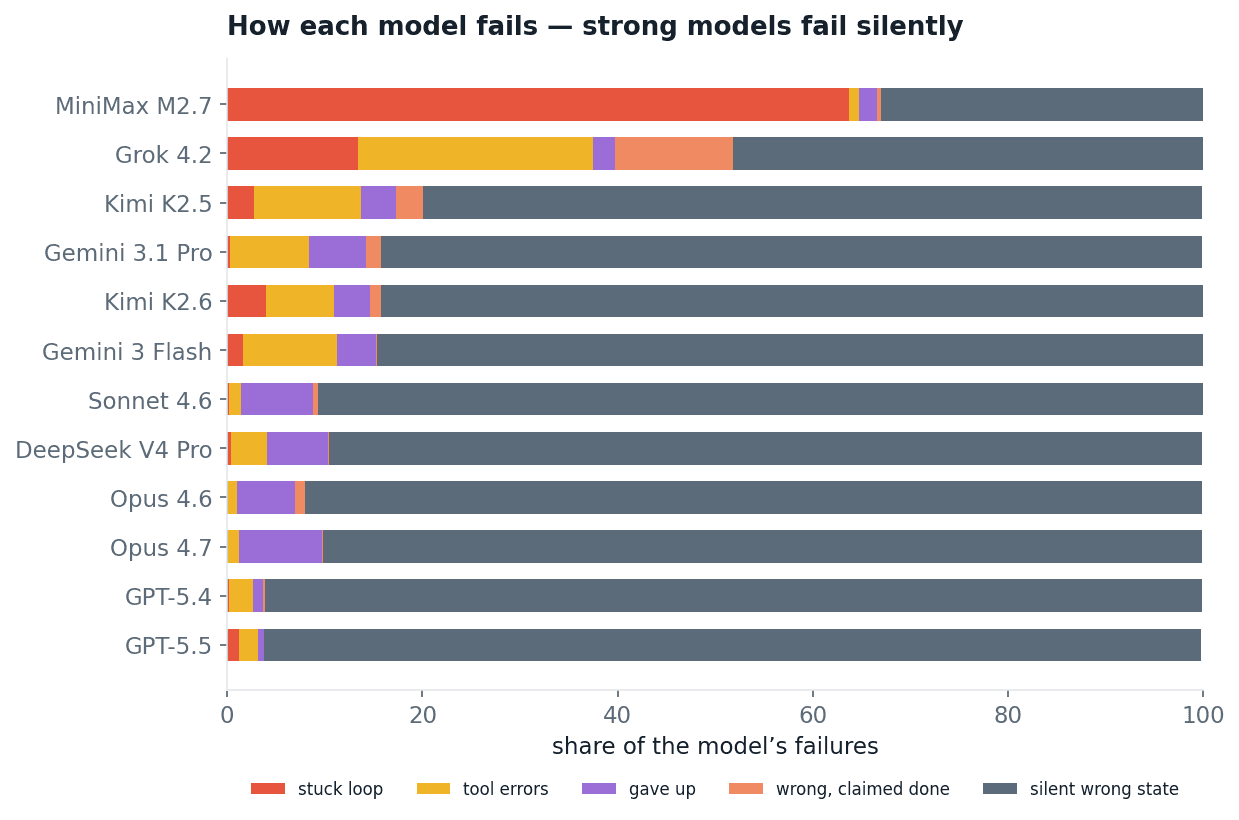
Figure 21. The mix of failure modes per model. The grey band, silent wrong state, dominates every strong model.
Takeaway
Monitoring that watches for errors, crashes and loops will catch how the weak models fail and miss how the strong ones do. The failure that matters produces no signal except a wrong database row.
15. Economics
Reliability per dollar, and one outlier
Total spend across the study was about $42,000. Plot each model's cost per task against its reliability and 10 of the 18 models are Pareto-dominated: another model is both cheaper and more reliable. Only eight sit on the frontier, and three of those are the only rational picks: DeepSeek V4 Pro is the cheap frontier ($0.49 per task, 33% pass^5), GPT-5.4 is the pragmatic paid choice ($2.94, 46%), and GPT-5.5 at maximum reasoning is the reliability ceiling ($7.05, 52%). Everything else is someone else's worse deal.
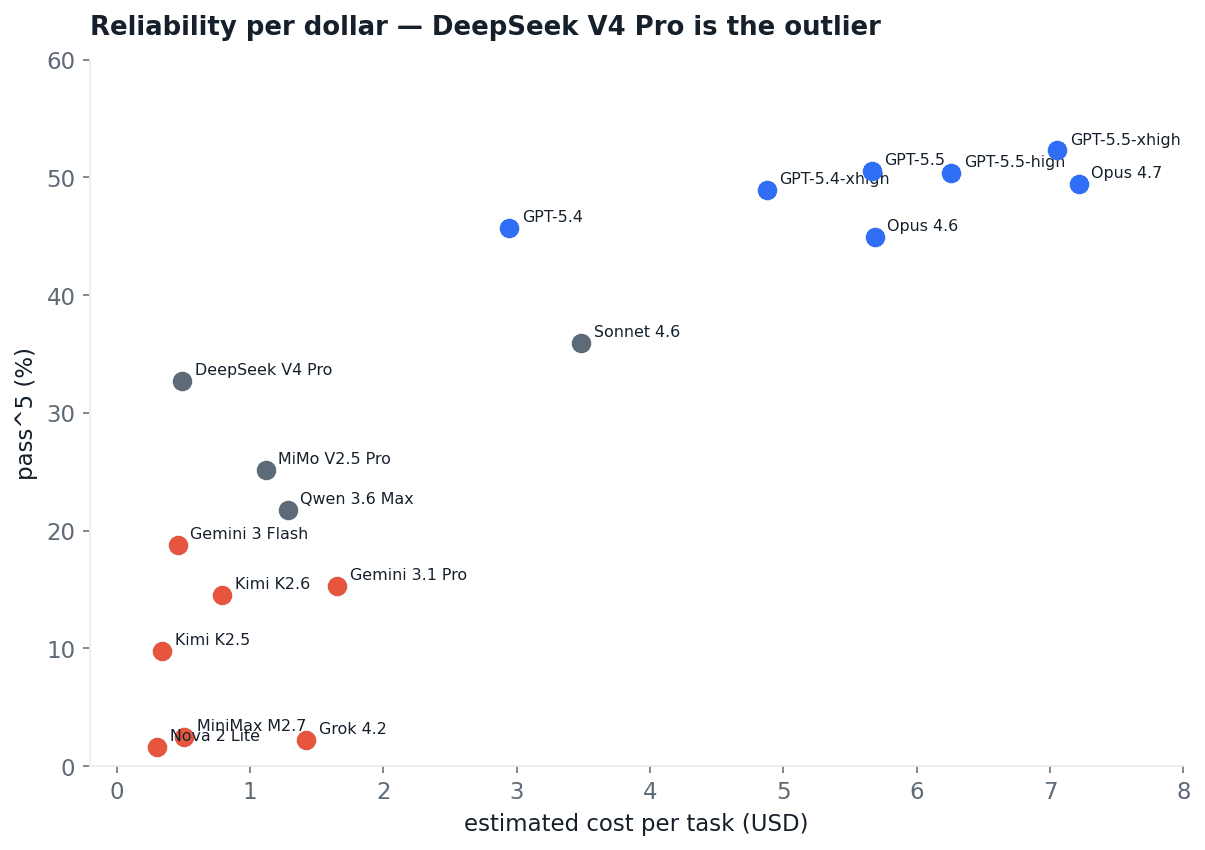
Fig 22. Estimated cost per task against pass^5. DeepSeek V4 Pro breaks the cost-quality line.
Reasoning effort is the other lever, and a small one. Run GPT-5.5 at medium, high and maximum reasoning and pass^5 moves from 50.5% to 50.4% to 52.3%. GPT-5.4 gains about three points from default to maximum. More thinking buys a couple of points. It does not buy a generation, and it does not buy judgment.
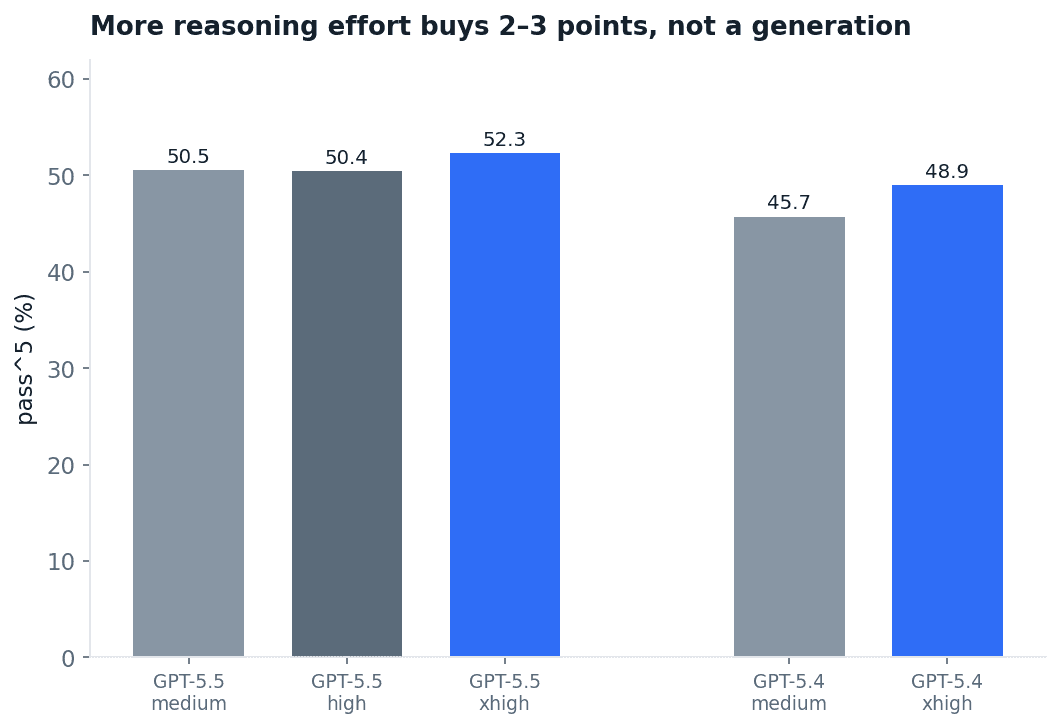
Fig 23. pass^5 by reasoning effort, within the GPT-5.5 and GPT-5.4 families.
Takeaway
If cost matters, DeepSeek V4 Pro delivers two-thirds of frontier reliability at a tenth of the price. And do not expect a reasoning-effort dial to rescue a deployment: it is worth two or three points, not a tier.
16. The other reader
Every failure above is a post-training target
Read this far and the post is a warning for anyone deploying an agent. Turn it over. For anyone training one, the same data is an asset, and a rare one. A public benchmark tells a lab "your model scored 47%." It does not say what to fix. Because Arena grades the final database state field by field, and because the failures are stable and shared (Findings 1 and 2), it produces something a post-training run can consume directly: the specific field, the specific wrong value, repeated across the frontier.
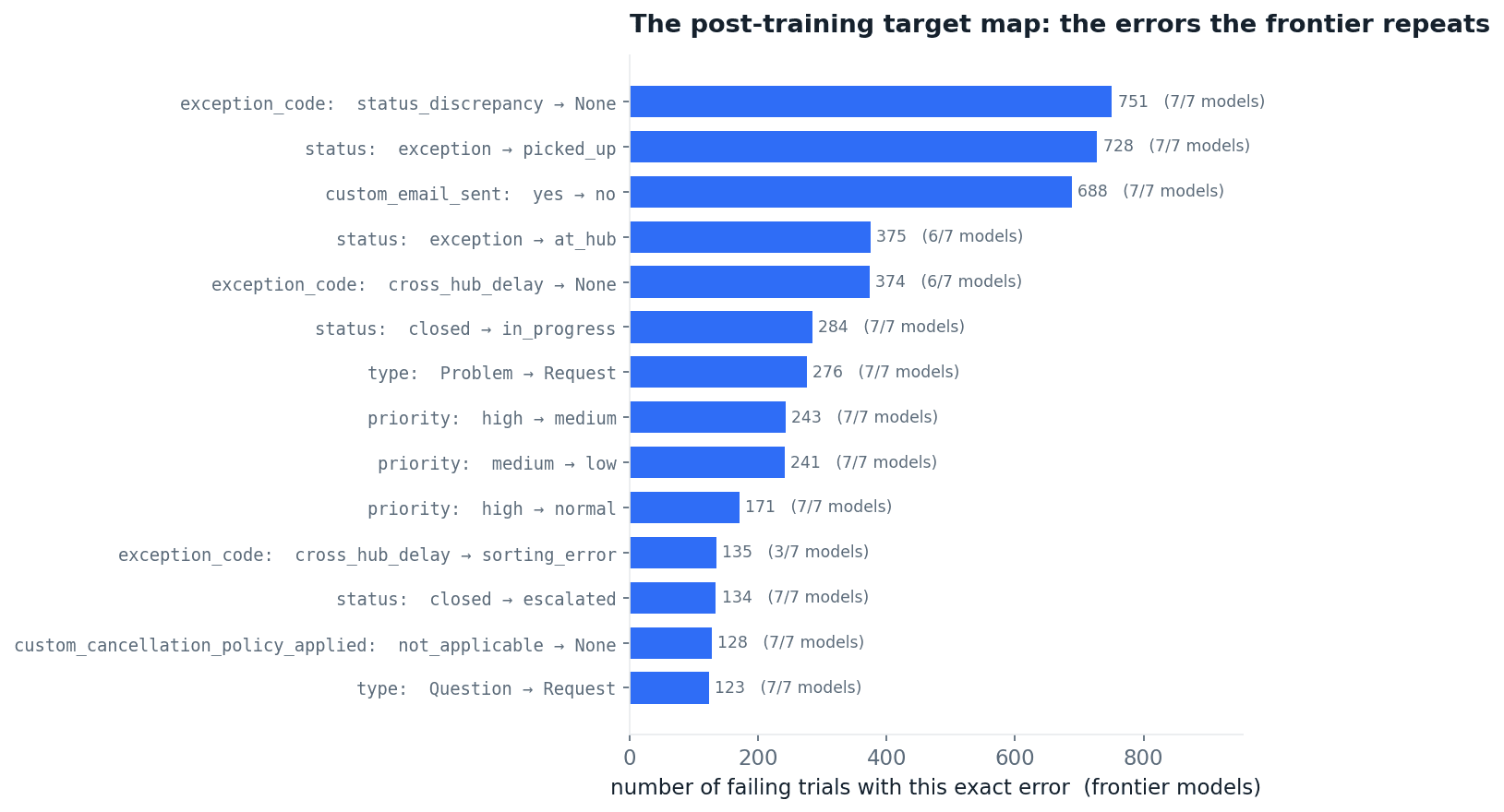
Fig 24. The errors the frontier repeats: each bar is one exact field-level mistake (field, expected value, the value models wrote instead) and how many of 7 frontier models make it. Built from the per-trial diffs; the disputed bank-HR closed/resolved diff is excluded.
These are not anecdotes. "Set exception_code to status_discrepancy, not None." "A blocked shipment is status: exception, not picked_up." "This refund required an email; the model recorded none." Every one is made by all seven frontier models, hundreds of times, the same way. That is a labelled training signal: a curriculum of exactly where enterprise judgment is missing.
Takeaway
For an enterprise, this catalog is a risk register. For a frontier lab, it is a post-training target set: stable, field-level, reproducible, and impossible to get from a public leaderboard. Measuring the failure precisely is the first step to training it out.
17. What this means
Reliability is a comprehension problem
The standard playbook for agent reliability, sample more, vote, raise the retry count, wait for the next model version, assumes failures are independent noise. They are not.
A flaky frontier agent has a stable, specific, wrong understanding of the task. Because the misunderstanding is stable, it survives retries, more reasoning and the next checkpoint alike. Because it is shared, swapping in another lab's model fails the same way too. Because the agent cannot see that its understanding is wrong, it reports success anyway, and spends no extra effort on the tasks it is failing. It is consistently wrong, confidently wrong, about the same thing as every other model. The only random variable is whether you happen to catch it.
None of this is visible through any other lens. pass@1 hides the stable error behind a lucky run. An LLM-as-judge reads the confident transcript and scores a pass. A public benchmark is contaminated before the test begins. The findings exist only because the test is private, run five times, and graded on ground-truth state across many models at once.
Enterprise agents do not fail at clicking the button. They fail at knowing what the button should mean under policy.
The frontier's enterprise problem in 2026 is not that agents cannot operate the tools. They can. It is that they do not understand what correct looks like under a specific, real policy, they cannot tell that they do not, and they are all wrong in the same place. That is the gap between the demo and the job. For the enterprise, closing it means building the policy-to-state layer the model lacks. For the lab, it means training against the targets a private, ground-truth benchmark can finally name. Either way, the work starts with measuring the failure precisely enough to act on it.
Renaud de la Gueronniere
Creator and technical architect of Toloka Arena and TolokaForge. I designed and wrote the evaluation harness behind this study, and have shipped 60+ agentic evaluation environments for several frontier AI labs. Previously Expert Engagement Manager and Principal Data Scientist at McKinsey QuantumBlack. The Forge harness is open source; the analysis code and figures for this post are available on request.
Method and data
Two data layers, kept distinct throughout. The leaderboard, decay, domain, cost and reasoning figures are the official run: 18 models, 75,172 graded trial records. The trial-level mechanistic analysis (flakiness, correlation, calibration, effort, field accuracy, escalation, failure modes) is computed from the per-trial transcript export, on a fixed 18-model panel across the 6 cleanly-graded domains: 60,435 trials. (The latest export also contains GPT-5.5-high, a third GPT-5.5 reasoning setting; it is held out so the panel is not weighted toward one model.) Each figure caption is tagged with which layer it draws on. pass^k is computed only on task/model cells with at least k completed repeats. Grading is a deterministic field-level diff of the final database state against an expert-authored golden state. The official report also contains 7 sampled validation slices that do not drive the leaderboard.
Definitions. A flaky task is a (model, task) pair passing 1 to 4 of 5 runs. The flakiness result is reported on the GPT and Claude models (the pattern weakens for the weaker open-weight models, as Figure 8 shows): 83% of their flaky cells have a repeated stable field-diff, and 74% still do when the cell is restricted to at least two failing runs (so "same way" is a real test, not a one-run tautology). Pooled across all 18 models the two-failing-run figure is 57%. Every number in the post is reproducible from a checked-in script via run_all.sh: field accuracy (field_accuracy.py), the shared-error null (shared_error.py), the residualized failure fingerprint (residual_fingerprint.py) and the task-conditioned cohort test (distill_cohort.py), the version deltas (version_delta.py), the reasoning-effort reshuffle (reasoning_reshuffle.py), the false-success ranking (false_success.py), the cohort strength control (cohort_control.py), policy lift (policy_lift.py), escalation temperament (escalation.py), the under-reaction bias (under_reaction.py), routing and cost (routing_cost.py), and the robustness table (robustness.py).
Test-case quality, and how much it moves the score. Two layers of flagging. Before this run, the generation pipeline's own filter dropped 111 of 796 candidate tasks (14%) as low-value. Separately, an in-analysis audit flags 187 "consensus-suspect" tasks where 12 or more models converge on the same answer against the golden (retained, since model consensus is not proof the models are right; listed in flagged_testcases.md). These flags are not spread evenly: 67 of the 185 in the clean domains, 36%, land in bank-HR, the same domain as the grading issue described next, which suggests a large share of them trace to one grading ambiguity rather than to model error. A third issue: in bank-HR the policy requires status closed, reachable only after a user acknowledgment the simulator does not always deliver. These are not cosmetic. The table below (18-model transcript export, per-task pass^5 on the 6 clean domains; robustness.py) shows how far the score moves:
model | baseline | excl. suspect | bank-HR normalized |
|---|---|---|---|
GPT-5.5-xhigh | 49.2 | 62.7 (+13.5) | 59.7 (+10.6) |
GPT-5.5 | 46.3 | 60.5 (+14.2) | 56.3 (+10.0) |
Opus 4.7 | 45.8 | 59.2 (+13.3) | 47.5 (+1.7) |
GPT-5.4 | 39.5 | 51.7 (+12.2) | 46.8 (+7.3) |
So the absolute pass^5 numbers are sensitive: removing the suspect tasks raises frontier scores 12 to 14 points, and the bank-HR normalization adds another 7 to 11 for the GPT models. We do not minimize this. What does not move: the broad leaderboard ordering (the GPT and Claude cluster stays on top under every variant), and the within-trial failure mechanisms, flakiness stability, shared-error overlap, calibration and silent failure, which are computed inside each trial and do not depend on which tasks are scored. The headline 52% should be read as a soft number with a real upward correction pending; the failure mechanisms are the durable result.
Feasibility. 97% of tasks were passed by at least one of ~85 attempts, so the difficulty is real, not broken tasks. 60% of items have discrimination above 0.3.
Toloka Arena is a private-holdout evaluation for enterprise agentic tool use. Live leaderboard and methodology at toloka.ai/arena.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.