← Blog
/

Essential AI agent guardrails for safe and ethical implementation
High-quality human expert data. Now accessible for all on Toloka Platform.
Stress-test models with real-world edge cases to surface hidden risks
AI agents aren't just chatbots anymore — and that changes everything. Today, they can book flights, write and execute code, manage databases, and make decisions that affect real operations. Unlike traditional generative AI systems that simply generate content, these automated systems can plan complex tasks and take actions with real consequences.
Here's what keeps security teams up at night: When large language models get something wrong, you get a bad answer. When AI agents get something wrong, you might get unauthorized transactions, leaked sensitive data, or deleted production databases. That's not a typo in a report — that's a disaster.
This shift in capability means we can no longer focus solely on output quality. We need robust guardrails to manage the new security risks posed by autonomous AI systems.
What are AI guardrails?
Think of AI guardrails as the control systems that keep autonomous vehicles from driving off cliffs. They're not suggestions built into the model's training data through fine-tuning — they're external protective measures that actively monitor and control what AI systems can do.
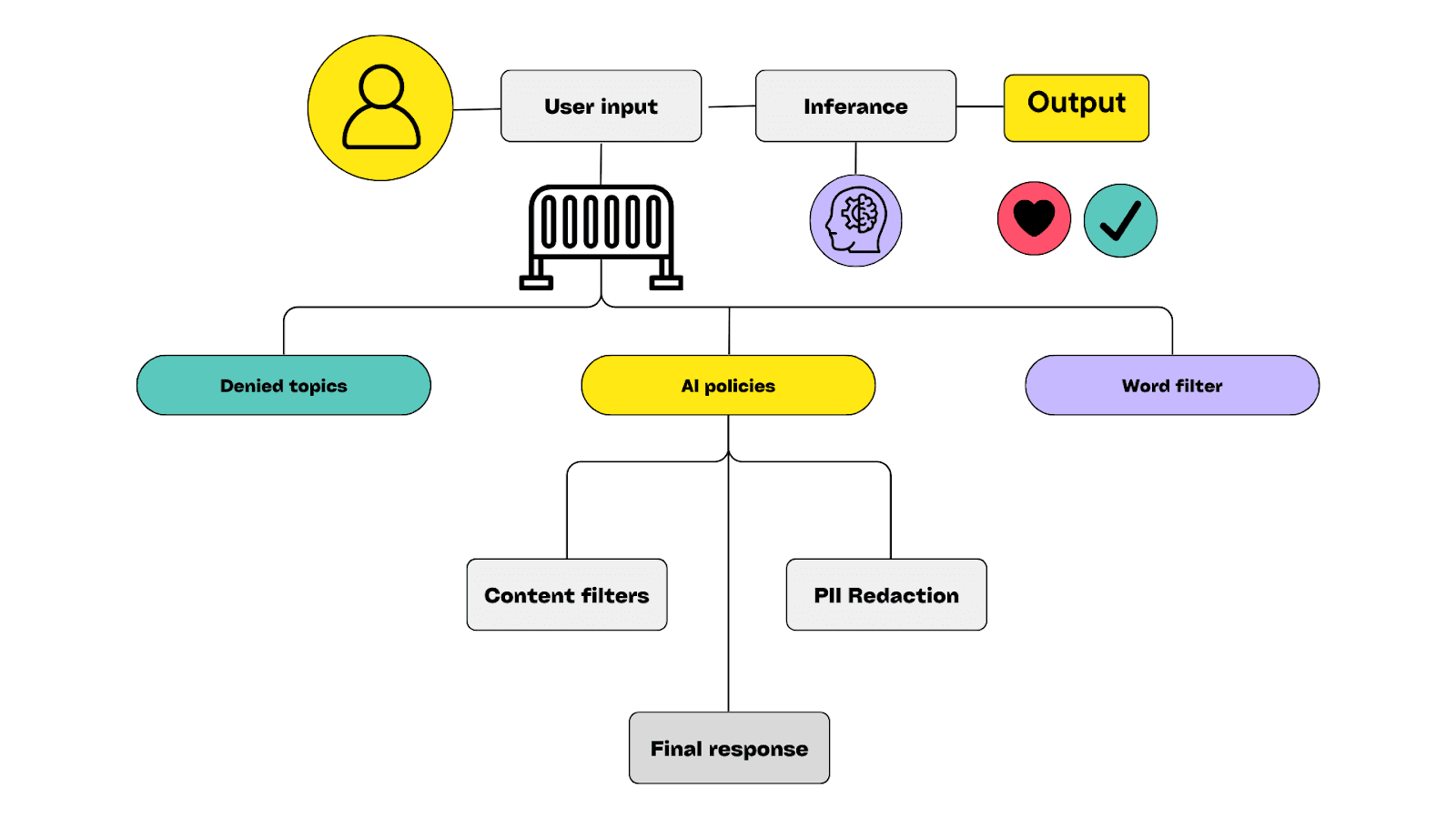
Effective artificial intelligence guardrails must accomplish three critical things:
Block bad inputs before they reach the agent's reasoning engine. This means catching prompt injection attempts, malicious attacks, and other manipulations designed to override system instructions and compromise user safety.
Filter dangerous outputs before they leave the system. Scan for personally identifiable information (PII), social security numbers, and other personal details. Content moderation systems check for unsafe content, offensive language, and inappropriate content that violates ethical boundaries.
Restrict risky actions at the execution level. AI agents shouldn't execute high-risk operations without explicit authorization, regardless of what their reasoning suggests.
This isn't theoretical. OWASP identifies prompt injection as the number one security risk for large language model applications in 2025. If you're not protecting against it, you're playing with fire.
The security risks keeping AI teams up at night
The complexity of agentic AI systems creates security challenges that didn't exist with purely generative AI. Understanding these risks is essential for building effective guardrails.
Prompt injection
Prompt injection exploits the core of natural language systems. With autonomous agents, a malicious natural language instruction doesn't just create bad text — it can trigger unauthorized actions. Attackers can force AI systems to violate guidelines, generate harmful content, enable unauthorized access, or influence critical decisions affecting business goals.
Real-world wake-up call: Even top AI models are vulnerable to jailbreak attacks in over 80% of tested cases.
Data exposure
Data exposure happens when AI systems operate with excessive permissions. Agents often inherit whatever access they're given to exposure-critical information. If your customer service agent, for example, has write access to billing databases, a single compromised agent can become a backdoor into your entire infrastructure.
The numbers don't lie: In 2025, 39% of companies reported AI agents accessing unintended systems, and 32% saw agents allowing inappropriate data downloads.
The autonomy paradox...
Action cascades occur because the autonomy that makes these AI tools useful also makes them unpredictable. A small reasoning error can trigger expensive loops or catastrophic actions that are difficult to reverse. The non-deterministic nature of large language models means you can't predict every possible behavior path.
How to build guardrails for AI models that actually work
Making sure that AI systems operate safely requires defense in depth. You wouldn't protect a bank vault with just one lock — the same principle applies to AI agents. Thankfully, you don't have to build everything from scratch; a growing ecosystem of open-source frameworks provides a critical head start. Key guardrails must work across multiple layers to mitigate risks effectively.
Input validation guardrails
Input checks catch threats before they reach the core language model. Advanced filters detect patterns typical of prompt injection attempts and other malicious user queries. This is your cheapest and fastest line of defense — block the attack before the generative AI processes it.
Reasoning and behavioral guardrails
These systems validate what AI agents plan to do before they act. Does this sequence make sense? Is the agent trying to access tools outside its mandate? Does the plan violate corporate policies or societal norms?
Role-based access control (RBAC) verifies that tool usage aligns with the agent's designated permissions. This prevents privilege escalation and ensures agents can't exceed their authorized scope — essential safeguards for any production deployment.
Output content guardrails
Output filtering is the final check before anything leaves the system. Real-time PII detection prevents accidental exposure of high-risk data. Content moderation, a key protective measure, catches policy violations, unsafe content, and compliance risks before delivery to users.
Action controls and tool safeguards
Action controls define what AI agents physically can and cannot do. Whitelist approved APIs. Enforce least-privilege access. Human oversight is required for significant risk operations like financial transactions or database modifications.
Open-source frameworks like Nemo Guardrails provide open-source resources for implementing these restrictions systematically, making it easier to enforce security measures across complex tasks.
Monitoring and operational guardrails
Comprehensive data collection and logging ensure visibility into every agent decision. These audit trails are essential for regulatory compliance and understanding what happened during security incidents. Regular audits verify that security measures remain effective as threats evolve.
Six principles for implementing effective AI guardrails
Match security to risk level
Not all AI agents are created equal. AI systems handling complex tasks with sensitive data need far more stringent security measures than agents summarizing meeting notes. Allocate protective guardrails proportionally to potential impact and align with business goals.
Test relentlessly by prompt-hacking your own AI
You can't set up guardrails and forget about them. Continuous red-teaming uncovers vulnerabilities that training data and fine-tuning alone cannot address. The threats evolve constantly — your defenses must too.
Balance safety with utility
Overly restrictive guardrails generate false positives that frustrate users and train them to work around your security. Guardrails minimize friction while maximizing safety. If your AI tools are unusable, users will find workarounds, and that's when a whole new realm of risks emerges.
Implement human oversight for critical actions
Operations involving proprietary information, financial transactions, or system modifications should require human confirmation. The AI agent prepares everything, but a person makes the final call. This ensures compliance while maintaining operational efficiency.
Update continuously through feedback loops
Use reinforcement learning from human feedback (RLHF) to continuously refine your guardrails. By monitoring failed attacks and near-misses, you can proactively strengthen your defenses — ensuring your AI stays ahead of emerging threats and maintains robust, adaptive protection.
Design for auditability from day one
If you can't explain why your AI made a decision, you don't fully control it. Build comprehensive logging and audit trails into your architecture right from the start.
How to measure guardrail effectiveness in AI systems
You can't improve what you don't measure. Quantifiable metrics prove your AI guardrails actually work.
Attack block rate: Track how many prompt injection attempts and other malicious inputs get stopped versus those that slip through. Near-zero successful attacks should be your target.
False positives/negatives: If legitimate user queries constantly hit guardrails, you've made your AI system unusable. Effective guardrails maintain utility while ensuring compliance and user safety.
Performance impact: Additional validation steps add latency. If security checks slow AI agents to the point where users abandon them, you've failed. Nemo Guardrails and similar frameworks demonstrate that high compliance doesn't require sacrificing performance.
Audit trails: Detailed data collection enables regulatory adherence and post-incident analysis. If you can't trace an agent's decision path through your model output logs, you can't improve your essential safeguards.
Periodic audits: Independent security reviews verify that your protective measures remain effective against current threats to artificial intelligence systems. What worked yesterday might not work tomorrow.
Meeting compliance and ethical standards with AI guardrails
AI guardrails aren't just security measures — they're how you meet compliance requirements and ethical controls in an increasingly regulated landscape.
Data privacy: Regulations require strict controls over how AI handles sensitive information. Guardrails enforce these rules programmatically, ensuring AI agents can't inappropriately access or process protected data.
Auditability: Regulatory requirements increasingly mandate human oversight and clear accountability. Your guardrails must create transparent chains showing why an AI agent made each decision.
Fairness and bias prevention: Ethical demands fairness and transparency. Effective guardrails prevent AI models from perpetuating bias or making discriminatory decisions that violate societal norms.
Conclusion
Trust takes years to build and seconds to destroy. A single security incident involving an AI agent — a data breach, unauthorized transaction, or compliance violation — can irreversibly damage your entire AI initiative. The cost of one failure often dwarfs the investment in prevention.
Guardrails aren't constraints on innovation; they're what make ambitious AI applications possible. They create the foundation for pushing boundaries while managing risk through adaptable, layered controls.
The challenge of responsible AI is a moving target, for now. It's a continuous evolution as capabilities expand and risks shift. Organizations that will thrive aren't those racing ahead recklessly or holding back fearfully. They're the ones treating guardrails as essential infrastructure: safeguards that mature alongside their AI, enabling them to build not just powerful technology, but technology worthy of trust.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.