← Blog
/

History of LLMs: Complete Timeline & Evolution (1950-2026)
Toloka Arena is live. See how your model ranks.
Toloka delivers expert-annotated datasets for reasoning, tool use, and multi-step decision-making – purpose-built for frontier AI teams.
Updated: February 2026
A comprehensive guide to the evolution of Large Language Models – from early neural networks to today's reasoning-capable AI systems and agentic workflows.
Introduction
The landscape of artificial intelligence has transformed dramatically since ChatGPT first captured public attention in November 2022. What began as impressive conversational AI has evolved into sophisticated reasoning systems, autonomous agents, and specialized models that are reshaping how we work, research, and innovate. With over 200 million active users worldwide and AI-generated code now accounting for nearly 46% of new software according to GitHub's 2024 report, large language models have become an integral part of modern technology infrastructure.
This comprehensive guide explores the complete history of LLMs, from their theoretical foundations in the 1950s through the transformer revolution, and into the current era of reasoning models, multimodal capabilities, and agentic AI. We'll examine key milestones, analyze current capabilities and limitations, and look ahead to what the future holds for this rapidly evolving technology.
What is a Large Language Model?
At its core, a large language model is a type of deep learning system trained on massive datasets of text to understand and generate human language. The fundamental task is deceptively simple: given a sequence of words, predict what comes next. From this basic mechanism emerges the ability to write coherent essays, translate languages, answer complex questions, and even reason through multi-step problems.
What makes a language model "large" is its parameter count – the adjustable weights that the model learns during training. Modern LLMs contain billions to trillions of parameters. GPT-4, for example, is estimated at approximately 1.8 trillion parameters, while Claude 3 reportedly contains around 2 trillion. These parameters are trained on enormous corpora of text data through self-supervised or semi-supervised learning, allowing models to capture linguistic patterns, factual knowledge, and reasoning capabilities without explicit human labeling for every example.
The transformer architecture, introduced in 2017, forms the backbone of virtually all modern LLMs. Transformers use attention mechanisms to weigh the importance of different words in a sequence, enabling models to understand context and relationships across long passages of text. This architecture has proven remarkably scalable – larger models trained on more data consistently demonstrate improved capabilities.
Key terms to know
Understanding the LLM landscape requires familiarity with essential terminology:
Prompt – the input a user provides to an LLM to illicit a response or carry out a task.
Transformer – the neural network architecture underpinning all major LLMs, using self-attention mechanisms to process sequences.
Attention mechanism – a technique that allows models to focus on relevant parts of input when generating output.
Embeddings – numerical representations of words or tokens that capture semantic meaning and relationships.
Fine-tuning – adapting a pre-trained model to specific tasks or domains using additional training data.
RLHF (Reinforcement Learning from Human Feedback) – a training technique that uses human preferences to align model outputs with desired behaviors.
Chain-of-thought (CoT) – a prompting and training approach where models generate step-by-step reasoning before arriving at answers.
Multimodal – models capable of processing and generating multiple types of data – text, images, audio, and video.
Agentic AI – AI systems that can autonomously plan, use tools, and execute multi-step tasks with minimal human intervention.
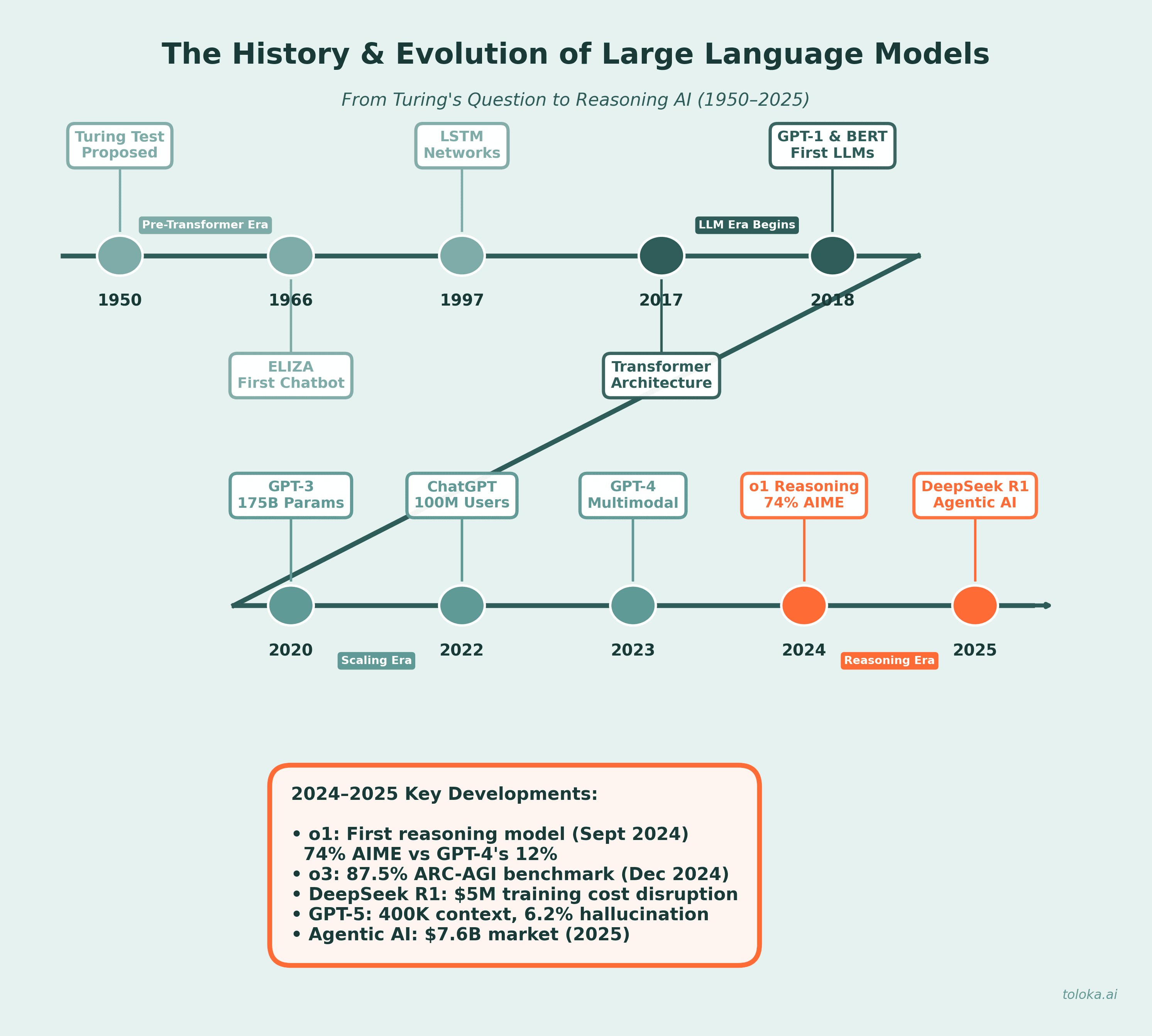
A brief history of LLMs: From ELIZA to GPT
The journey toward modern LLMs began in the 1950s and 1960s with early experiments in natural language processing. In 1954, researchers at IBM and Georgetown University demonstrated one of the first machine translation systems, automatically converting Russian phrases to English. This sparked decades of research into computational linguistics.
ELIZA, created by MIT researcher Joseph Weizenbaum in 1966, became the world's first chatbot. Using simple pattern matching, ELIZA could simulate conversation by reflecting users' statements back as questions. While primitive by today's standards, ELIZA demonstrated that computers could engage in human-like dialogue and laid the groundwork for conversational AI.
The field advanced significantly in 1997 with the introduction of Long Short-Term Memory (LSTM) networks, which could process sequential data while retaining information over longer periods. This enabled more sophisticated language understanding. Stanford's CoreNLP suite (2010) further expanded capabilities with sentiment analysis and named entity recognition.
The transformer architecture, introduced in Google's seminal 2017 paper "Attention Is All You Need," revolutionized the field. Unlike previous architectures that processed sequences one element at a time, transformers could process entire sequences in parallel while using attention mechanisms to capture relationships between any elements, regardless of distance.
The rise of modern LLMs: 2018-2023
The transformer architecture enabled rapid scaling of language models. BERT (Bidirectional Encoder Representations from Transformers), introduced by Google in 2018 with 340 million parameters, could understand context from both directions in text. BERT quickly became the foundation for Google Search queries and set new benchmarks across NLP tasks.
OpenAI's GPT series demonstrated the power of scaling. GPT-1 (2018) showed that language models could perform various tasks after pre-training on diverse text. GPT-2 (2019), with 1.5 billion parameters, generated such coherent text that OpenAI initially delayed its full release due to concerns about misuse. GPT-3 (2020), at 175 billion parameters, represented a quantum leap – it could write essays, code programs, and engage in sophisticated conversations with minimal task-specific training.
The release of ChatGPT in November 2022 marked a watershed moment. Built on GPT-3.5 and refined with RLHF, ChatGPT made advanced AI accessible to the general public through an intuitive chat interface. It reached 100 million users within two months – the fastest-growing consumer application in history at the time. GPT-4 followed in March 2023, introducing multimodal capabilities (accepting both text and images as input) and significantly improved reasoning.
The reasoning revolution: 2024-2025
The period from 2024 to 2025 witnessed perhaps the most significant architectural shift since the original transformer: the emergence of reasoning models. These systems don't just generate fluent text – they think through problems methodically, showing their work and self-correcting along the way.
OpenAI's o1 and o3: A new paradigm
In September 2024, OpenAI released o1-preview, the first in a new series of "reasoning models" trained specifically for chain-of-thought problem solving. Unlike GPT-4, which generates immediate responses, o1 spends additional time "thinking" – generating internal reasoning chains before producing final answers. This approach proved transformative for complex tasks: on the 2024 AIME math competition, GPT-4o solved only 12% of problems while o1 achieved 74% with single attempts and 93% with advanced sampling techniques.
The o3 family, announced in December 2024, pushed reasoning capabilities further. Using "simulated reasoning" (SR) and test-time search – generating multiple candidate reasoning paths and selecting the best – o3 achieved 87.5% on the ARC-AGI benchmark, approaching human-level performance (85%). OpenAI introduced "deliberative alignment," training models to internally reference safety policies during their reasoning process, representing a new approach to AI safety.
GPT-4o and multimodal integration
May 2024 saw the release of GPT-4o ("omni"), designed to seamlessly integrate text, audio, and visual capabilities. GPT-4o could engage in real-time voice conversations, analyze images, and generate outputs across modalities – all with significantly reduced latency compared to previous models. This marked a shift toward more natural human-computer interaction.
GPT-5: The convergence model
OpenAI's GPT-5, released in 2025, represents the convergence of multimodal and reasoning capabilities into a single flagship model. With a 400K token context window (up from 128K in GPT-4) and improved reliability – hallucination rates reduced to approximately 6.2% – GPT-5 achieved perfect scores on the AIME 2025 math benchmark. OpenAI also entered the open-source arena with gpt-oss-120b and gpt-oss-20b, released under Apache 2.0 license.
The DeepSeek revolution: Democratizing reasoning
January 2025 brought one of the most significant disruptions in AI history: the release of DeepSeek R1 by Chinese AI lab DeepSeek. This open-source reasoning model achieved performance comparable to OpenAI's o1 across math, code, and reasoning tasks – but at a fraction of the cost.
DeepSeek's approach was revolutionary. The R1-Zero model demonstrated that reasoning capabilities could emerge purely through reinforcement learning, without any supervised fine-tuning or human-labeled reasoning examples. The model spontaneously developed self-verification, reflection, and extended chain-of-thought behaviors – capabilities previously thought to require explicit training.
Perhaps most disruptive was the cost: DeepSeek reported training V3 (the base model) for approximately $5 million and R1 for an additional $294,000 – orders of magnitude less than the hundreds of millions previously assumed necessary for frontier models. The release triggered nearly $1 trillion in stock market losses as investors reassessed AI economics.
DeepSeek also demonstrated effective knowledge distillation: their 14B parameter distilled model outperformed the much larger QwQ-32B, showing that smaller models could inherit sophisticated reasoning from larger ones. This opened new possibilities for deploying capable AI on consumer hardware.
The current model landscape: A multi-polar AI world
By early 2026, the AI landscape has evolved from OpenAI dominance into a competitive multi-polar environment:
OpenAI
GPT-5.2 leads the flagship lineup with 400K context and reduced hallucinations. The o-series (o1, o3, o4-mini) provides specialized reasoning. OpenAI maintains the largest consumer mindshare – ChatGPT has over 200 million users – but faces increasing pressure from competitors.
Anthropic
Claude 4 (Opus and Sonnet variants) emphasizes safety through "Constitutional AI" principles and extended thinking modes for deliberate reasoning. Claude Opus 4 achieved 72.5% on SWE-Bench coding tests versus GPT-4's 54.6%, establishing leadership in software engineering tasks. Claude 4.5 now competes directly with GPT-5 across benchmarks.
Google DeepMind
The Gemini family progressed rapidly through versions 2.0, 2.5, and 3.0 during 2025. Gemini models support 1 million+ token context windows, native multimodal processing, and competitive pricing. Google's Deep Think reasoning variant competes directly with o3 on mathematical competitions. In December 2025, OpenAI reportedly declared a "Code Red" in response to Gemini 3.
Meta
Llama 4, released in April 2025, includes "Scout" and "Maverick" variants with multimodal capabilities and extended context. However, Llama has lost ground to Chinese open-source models – Qwen from Alibaba now leads in downloads and community derivatives, according to the ATOM project's tracking.
Emerging Players
Mistral AI's Mistral 3 (675B parameters, mixture-of-experts) delivers 92% of GPT-5.2's performance at roughly 15% of the cost. Alibaba's Qwen 3 leads open-source adoption. Other Chinese labs including MiniMax, GLM, and Yi continue advancing, while xAI's Grok 3 competes in the premium tier.
The rise of agentic AI: From assistants to autonomous systems
Perhaps the most transformative development of 2024-2025 was the emergence of agentic AI – systems that don't just respond to prompts but autonomously plan, execute, and adapt to accomplish complex goals. The AI agents market exploded from $5.4 billion in 2024 to $7.6 billion in 2025, with projections reaching $50 billion by 2030.
Agentic LLMs differ fundamentally from traditional chatbots. Where a standard LLM generates answers, an agent generates outcomes. These systems can reason through multi-step plans, invoke external tools and APIs, maintain memory across interactions, verify results, and recover from errors – all with minimal human oversight. Gartner predicts that by 2029, 80% of customer support issues will be handled by AI agents.
Key agent capabilities now include: tool use (calling APIs, accessing databases, browsing the web), persistent memory (retaining context across sessions), autonomous planning (breaking complex goals into executable steps), and self-correction (detecting and recovering from errors). Frameworks like LangChain, LangGraph, CrewAI, and Microsoft's AutoGen have emerged to support agent development.
Major platforms have launched dedicated agent products: OpenAI's Operator handles web tasks autonomously, Google's Project Mariner automates browser-based workflows, and Anthropic's Claude 4 supports extended "computer use" capabilities. According to LangChain's State of AI Agents report, 23% of organizations are already scaling agentic AI systems, with another 39% actively experimenting.
Build better AI agents with high-quality training data
Developing capable AI agents requires high-quality human feedback for training and evaluation. Toloka's platform provides access to domain experts across 90+ fields for RLHF data collection, model evaluation, and agent testing. Start your first project today with AI-assisted setup and pay-as-you-go pricing – no minimums required.
Training Large Language Models in 2026
Modern LLM training has evolved into a sophisticated multi-stage pipeline combining pre-training, supervised fine-tuning (SFT), reinforcement learning, and specialized post-training techniques.
Pre-training: The Foundation
Pre-training remains the computational core of LLM development. Models learn from massive text corpora – books, articles, websites, code repositories – to predict the next token in sequences. The Chinchilla scaling laws (2022) established that optimal training requires roughly equal scaling of model parameters and training tokens, leading to more data-efficient approaches.
Supervised Fine-Tuning (SFT)
After pre-training, models undergo supervised fine-tuning on curated examples of desired behavior – question-answer pairs, instruction-following examples, and task demonstrations. This shapes the model's output style and teaches it to follow instructions reliably.
RLHF and Preference learning
Reinforcement Learning from Human Feedback has become standard for aligning models with human preferences. Human annotators compare model outputs, ranking responses by quality, helpfulness, and safety. These preferences train a reward model that guides further model optimization. Variations include DPO (Direct Preference Optimization), which simplifies the pipeline by eliminating the separate reward model.
Reasoning-specific training
The o1 and DeepSeek R1 models introduced specialized training for reasoning. Key innovations include: using reinforcement learning to encourage extended chain-of-thought generation, training models to verify and correct their own reasoning, and developing process reward models that evaluate intermediate reasoning steps rather than just final answers. DeepSeek's R1-Zero demonstrated that basic reasoning behaviors can emerge purely from RL without supervised examples.
Applications of Large Language Models
LLMs have found applications across virtually every industry:
Software development
AI-assisted coding has become mainstream. GitHub's 2024 report found that 46% of new code is AI-generated. Tools like GitHub Copilot, Claude Code, and OpenAI's Codex automate everything from code completion to full project scaffolding. Asynchronous coding agents can now complete tasks that take humans multiple hours working independently.
Healthcare
Specialized models like MedPaLM are reducing clinical documentation time by 40% in US hospitals. LLMs assist with medical record summarization, diagnostic support, and patient communication. Domain-specific fine-tuning ensures accuracy in high-stakes medical contexts.
Research and analysis
LLMs accelerate research by summarizing literature, generating hypotheses, analyzing data, and drafting papers. Extended context windows (now reaching 1 million+ tokens) enable processing of entire research corpora in single prompts.
Customer service
AI-powered chatbots and virtual assistants handle customer inquiries with increasing sophistication. Agentic systems can now complete complex multi-step support tasks – processing returns, modifying orders, troubleshooting issues – without human intervention.
Content creation
From marketing copy to technical documentation, LLMs support content creation at scale. Multimodal models generate images, edit video, and produce audio alongside text.
Current limitations and challenges
Despite remarkable progress, significant challenges remain:
Hallucination and reliability
LLMs can generate confident but incorrect information – "hallucinations." While GPT-5.2's hallucination rate of 6.2% represents a 40% improvement over earlier models, factual reliability remains imperfect. This is particularly concerning in high-stakes domains like medicine, law, and finance.
Bias and fairness
Models can reflect and amplify biases present in training data, including cultural, racial, and gender biases. These biases have real-world consequences in applications like hiring, lending, and content moderation. Ongoing research focuses on detection and mitigation techniques.
Reasoning limitations
Despite improvements, LLMs still struggle with certain reasoning tasks. Apple researchers found that adding irrelevant information to math problems caused significant performance drops (17.5% for o1-preview, up to 65.7% for less advanced models). Models may be pattern-matching from training data rather than developing genuine reasoning capabilities.
Safety and alignment
As models become more capable, ensuring they remain aligned with human values becomes increasingly critical. OpenAI's assessment found o1 crossed into "medium risk" territory for CBRN (chemical, biological, radiological, nuclear) concerns. Deliberative alignment and Constitutional AI represent ongoing efforts to address these challenges.
Environmental and computational costs
Training frontier models requires enormous computational resources with associated energy consumption and carbon emissions. While DeepSeek's cost-efficient approaches suggest optimization is possible, the largest models still require substantial infrastructure.
Ensure AI quality with human expert evaluation
High-quality human evaluation is essential for detecting hallucinations, measuring bias, and ensuring AI safety. Toloka provides access to domain experts for comprehensive model evaluation – from RLHF preference data collection to red-teaming and safety testing. Our LLM-based quality assurance automatically validates annotations against your standards.
The future of LLMs: 2026 and beyond
Several trends point toward the next phase of LLM evolution:
Test-time compute scaling
Rather than simply training larger models, the industry is shifting toward spending more compute at inference time. Reasoning models like o3 generate multiple candidate solutions, evaluate them, and refine their approaches – trading speed for accuracy. This represents a new scaling paradigm beyond traditional pre-training.
Autonomous agents at scale
The "agentic" paradigm will continue expanding. Models that can maintain long-running tasks, use tools effectively, and recover from errors will transform knowledge work. Multi-agent systems – teams of specialized AI agents collaborating on complex problems – are already emerging in production environments.
Efficient small language models
Not all progress requires massive scale. Small language models (SLMs) with 1-12 billion parameters are proving sufficient for many agentic workloads, especially with constrained outputs and tool use. Models like DeepSeek R1 distilled variants, Phi-4-Mini, and Gemini Nano bring sophisticated capabilities to edge devices and cost-sensitive applications.
Self-improving systems
DeepSeek R1's demonstration that reasoning can emerge purely from RL suggests models may increasingly generate their own training data. Google's experiments with LLMs generating self-training examples for fine-tuning point toward more autonomous improvement cycles.
Sparse expert models
Mixture-of-experts (MoE) architectures, used in DeepSeek V3 and Mistral 3, activate only relevant subsets of parameters for each task. This enables much larger total parameter counts with manageable computational costs, potentially continuing capability improvements without proportional increases in inference expense.
Toward AGI?
While frontier models now match human performance on many benchmarks, true artificial general intelligence remains elusive. Models excel at pattern matching within their training distribution but can fail surprisingly on novel problems. The path from current capabilities to genuine general intelligence – if achievable – remains unclear. What is certain is that AI capabilities will continue advancing rapidly, demanding ongoing attention to safety, alignment, and beneficial deployment.
Key takeaways
From chatbots to reasoning systems: LLMs have evolved from simple text generators to sophisticated reasoning engines capable of multi-step problem solving, self-verification, and autonomous task execution.
The democratization continues: DeepSeek's cost-efficient training and open-source releases have challenged assumptions about the resources needed for frontier AI, accelerating competition and access.
Agents are the new interface: Agentic AI represents a paradigm shift from tools you query to systems you delegate to – transforming how humans interact with AI.
Size isn't everything: Smaller, optimally trained models can match or exceed larger ones through better training techniques, knowledge distillation, and efficient architectures.
Human feedback remains essential: Despite advances in self-improvement, human judgment continues to be critical for alignment, evaluation, and handling edge cases that automated systems miss.
Challenges persist: Hallucination, bias, safety, and genuine reasoning remain active research areas requiring continued attention as capabilities advance.
Start building with expert training data
Whether you're developing LLMs, training AI agents, or evaluating model performance, high-quality human data is essential. Toloka provides the complete infrastructure for AI training data – from RLHF preference collection to synthetic data validation to comprehensive model evaluation.
Key capabilities: Domain experts across 90+ fields, AI-assisted project setup, LLM-based quality assurance, and pay-as-you-go pricing with no minimums.
Related resources
Continue learning about LLM development and training:
What is RLHF? A Complete Guide to Reinforcement Learning from Human Feedback
Direct Preference Optimization: The Next Evolution in LLM Alignment
Base LLM vs Instruction-Tuned LLM: Understanding the Difference
Check also our Platform - Toloka Platform: Self-Service Data Annotation
About Toloka
Toloka is a European company based in Amsterdam, the Netherlands that provides data for Generative AI development. Toloka empowers businesses to build high-quality, safe, and responsible AI. We are the trusted data partner for all stages of AI development from training to evaluation. Toloka has over a decade of experience supporting clients with its unique methodology and optimal combination of machine learning technology and human expertise, offering the highest quality and scalability in the market.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.