← Blog
/

The Production Gap: Why Enterprise AI Agents Keep Failing After Launch
Toloka Arena is live. See how your model ranks.
There's a moment most enterprise AI teams recognize. The benchmark numbers looked strong, and the demo convinced stakeholders. Then, three months into production, the same classes of mistake keep happening — subtly, consistently, in ways that previously didn’t show up during development.
You might initially think it’s a model problem, but the reality is it’s an infrastructure issue. One that has a predictable cost.
The failures that matter most don't appear in testing
The problem with standard benchmarks is that they only evaluate final outputs in a tightly controlled environment. In production, AI agents fail differently. For example, they might choose the correct tool but provide invalid data, or complete a task while ignoring real-world constraints the test didn't account for. They also tend to veer off-track during multi-step processes, which you can only catch by reviewing their entire workflow. Only looking at the final output isn’t enough.
An AI prepping client meetings might look flawless in testing, but it can quickly lose a relationship manager's trust by missing the nuances a human banker would catch. Its mistakes aren't massive or obvious. They are small blind spots that slowly accumulate and ruin confidence.
The failure is systematic, which means an annotator who understands the domain can classify it. And a corrected output becomes training data that points somewhere specific.
Why the benchmark keeps improving while production doesn't
Every week a team goes without evaluating the full process is another week spent training against a signal that completely misses how the agent fails in the real world. The model improves on the benchmark, but the disconnect in production grows. When the team finally builds the infrastructure to see what's happening, the accumulated debt is larger than it needed to be — and harder to unwind.
Upgrading to a smarter model won't magically fix the issue. A more advanced agent just finds more complex ways to fail over longer stretches of time, making its mistakes much harder to spot without the right tools. Being capable isn't the same as being reliable.
How the flywheel works, and where most teams cut corners
The mechanism is a loop: run the agent in a real environment, capture where it fails, have domain experts evaluate and correct those failures, feed the signal back into training, repeat.
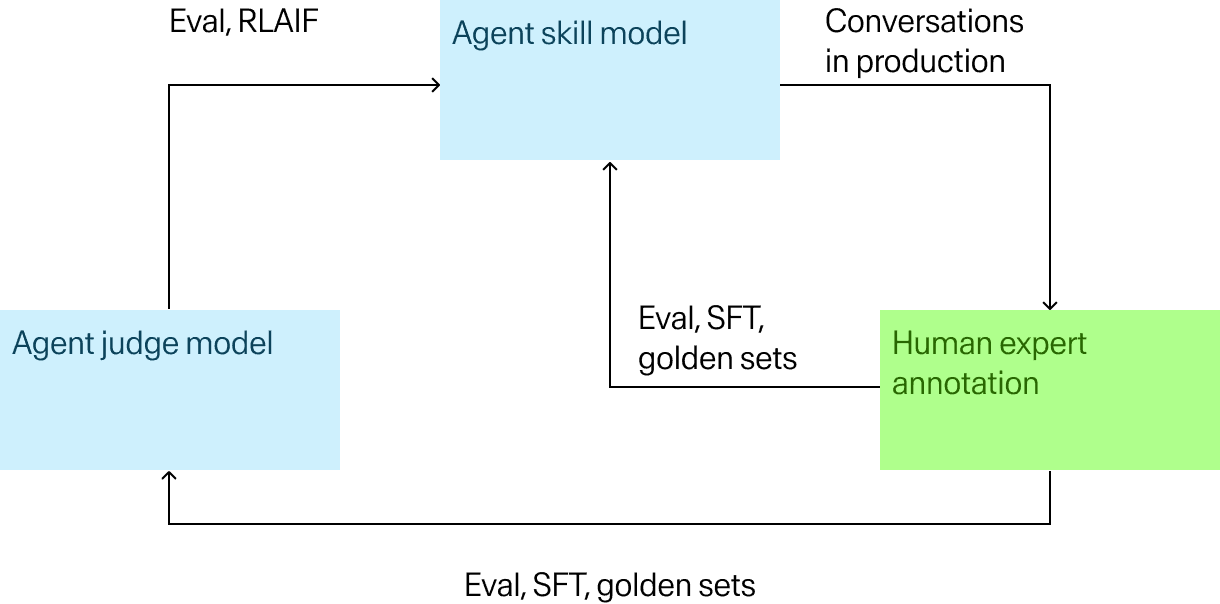
The compounding comes from the judge model, an LLM trained specifically to evaluate the skill model's outputs. The process starts with PII scrubbing and intelligent sampling of production conversations, filtering out highest-impact failures. Human experts then annotate at the skill level. For each agent capability, they assess whether the output is right or wrong and produce corrected outputs where needed. Those corrections flow directly into golden sets for skill model SFT as well as golden sets for training and evaluating the judge itself.
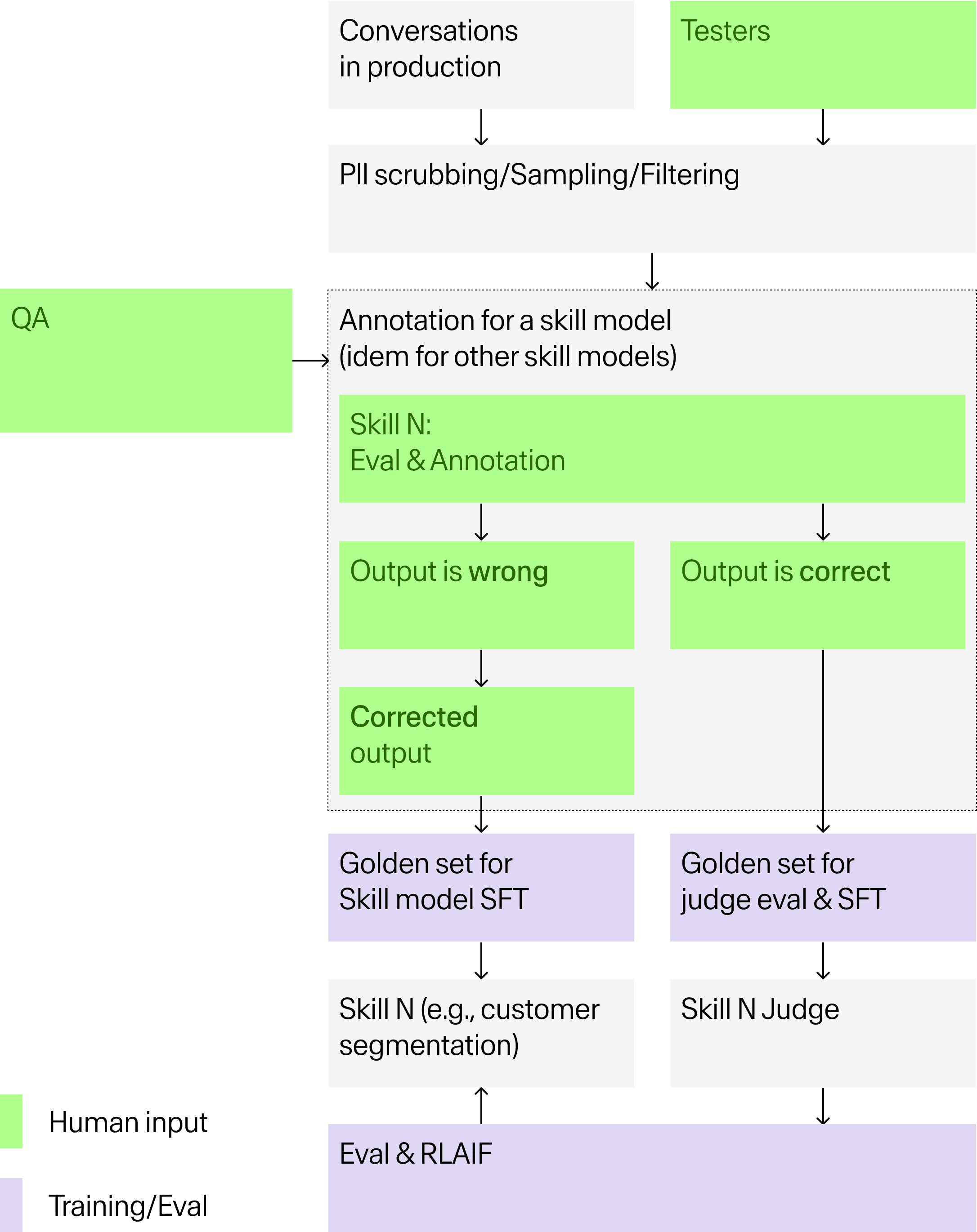
Once the judge reaches 90% classification accuracy, it can automate large portions of evaluation and generate preference data for RL, which accelerates everything downstream. Rather than the human layer disappearing at that point, it moves to where automated evaluation still can't be trusted: validating the judge's ground truth, catching edge cases outside the established quality framework, and resolving ambiguous outputs the judge hasn't yet earned accuracy on.
This is exactly where most teams cut corners. A judge trained on weak ground truth produces misleading signals. Synthetic data is valuable for volume and covering rare edge cases, but generating and evaluating it with the same underlying model creates a closed loop that reinforces existing blind spots rather than correcting them. Getting to statistical reliability requires 300 to 500 annotated data points per evaluation sprint — the minimum needed to draw reliable conclusions about where and how an agent is failing.
The expert question enterprise teams should be asking
The network behind this is 200,000+ domain experts across 90 specializations, but the more relevant question for enterprise teams is whether the people evaluating your agent's outputs grasp the nuances of the domain.
For a financial services agent, that means annotators with wealth management backgrounds reviewing client briefing outputs as opposed to generalist crowdworkers.
It’s practicing lawyers across practice areas for a legal agent,
A strategy or consulting use case means having people who've worked at MBB firms and know what constitutes rigorous analysis in practice.
The quality of the training signal depends entirely on the quality of that judgment, which is why the source of the feedback is just as important as the headcount.
This is also the argument against relying entirely on synthetic data. Yes, it can generate volume. But it can't replicate the judgment of someone with firsthand experience who knows what a wrong output looks like in practice.
Where this shows up across enterprise use cases
E-commerce
One global platform building a three-level multi-agent system for merchant support found that incorrect tool selection and unnecessary opt-out calls were the primary production failure modes — neither visible in testing. Failure-mode annotation identified what was going wrong and why. Toloka built eval and SFT datasets across the agent's full skill set. Skill-judge scores on real production traffic improved by 28.9%.
What that number represents is the evaluation infrastructure getting dramatically better at seeing how the agent was failing in practice, which is the prerequisite for fixing it. The platform expanded the engagement from there.
Coding agents
Coding agents working in production codebases fail differently from agents building greenfield projects. Hallucinated APIs, plausible but incorrect logic, code that introduces vulnerabilities that pass review. These require engineers who can evaluate output the way a senior reviewer would, across multi-step tasks, at volumes that produce statistically reliable conclusions.
Document and content generation
For agents generating slides, reports, or client-facing documents, correctness is only one dimension. Factual grounding, narrative coherence, and whether the agent introduces figures not present in source documents are all separate failure modes that a single aggregate score obscures entirely. The training signal is only helpful if it points to something specific, which requires an evaluation taxonomy granular enough to distinguish between them.
The infrastructure question
The distance between an impressive demo and a production-ready agent was never a model problem. The issues lie in the infrastructure, and teams that build reliable trajectory-level evaluation early are compounding an advantage that becomes harder to replicate over time. The data they're generating is proprietary, domain-specific, and tied to their actual production environment.
The process begins with a scoping phase to define the quality framework, establish what a successful output looks like, and determine how disagreements are handled. This is followed by pilot batches typically involving two to four weeks of iterative annotation calibrated against your ground truth before scaling to full production volume.
If you're seeing production performance diverge from benchmark scores, that disconnect is usually diagnosable. An evaluation sprint typically takes two to four weeks. It’s enough time to identify your agent's primary failure modes on real production traffic, calibrate against your ground truth, and give your team a clear picture of where the training signal is breaking down.
Schedule an evaluation sprint.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.