Aggregation Methods
Subscribe to Toloka News
Subscribe to Toloka News
In recent years crowdsourcing has become a standard tool for labeling massive datasets. It offers an appealing alternative to expensive expert labelers and distributes the task across a large crowd of low-cost non-expert workers. The power of crowdsourcing rests on the wisdom of the crowd — it has been observed in many contexts that judiciously aggregated independent opinions of unskilled individuals can outperform judgments of domain experts. Thus, methods for aggregating and drawing meaningful inferences from the noisy labels obtained from crowd workers are the cornerstone of crowdsourcing. In this article, we will discuss the foundations of aggregation techniques.
Example
Before we delve into details, let us introduce a running example that we will use throughout the article. Suppose we have a dataset of images and our goal is to classify each image as a cat or a dog. The crowdsourcing paradigm prescribes to distribute the task across multiple workers, each of whom labels a subset of the images. As a result, for each image we have several labels and the goal of the aggregation method is to combine multiple noisy labels into a single high-quality answer to the task. For brevity, in this article we will consider the binary classification task and give references to the literature where the multiclass case is described.
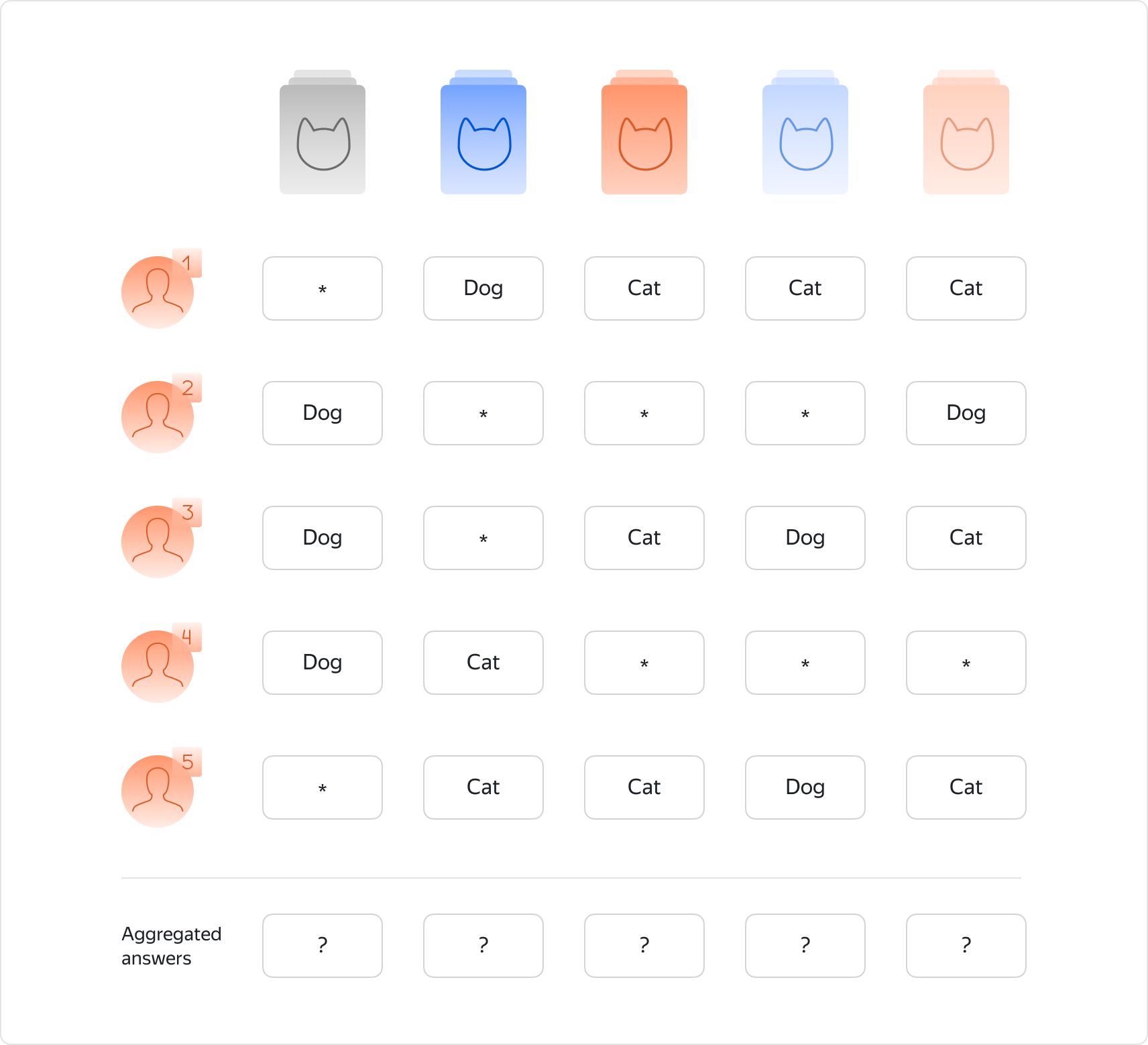
Methods
Method
Let's begin by introducing a simple and intuitive tool that is often used in practice: the majority vote aggregation algorithm. The idea of majority vote is to follow the most popular opinion among the workers. Majority Vote: the most popular label is set as the aggregated answer. Majority vote is a simple yet practical tool — it rests on the assumption that most of the workers are more likely to select the correct answer, and it compensates for noise by using the redundancy of the obtained labels.
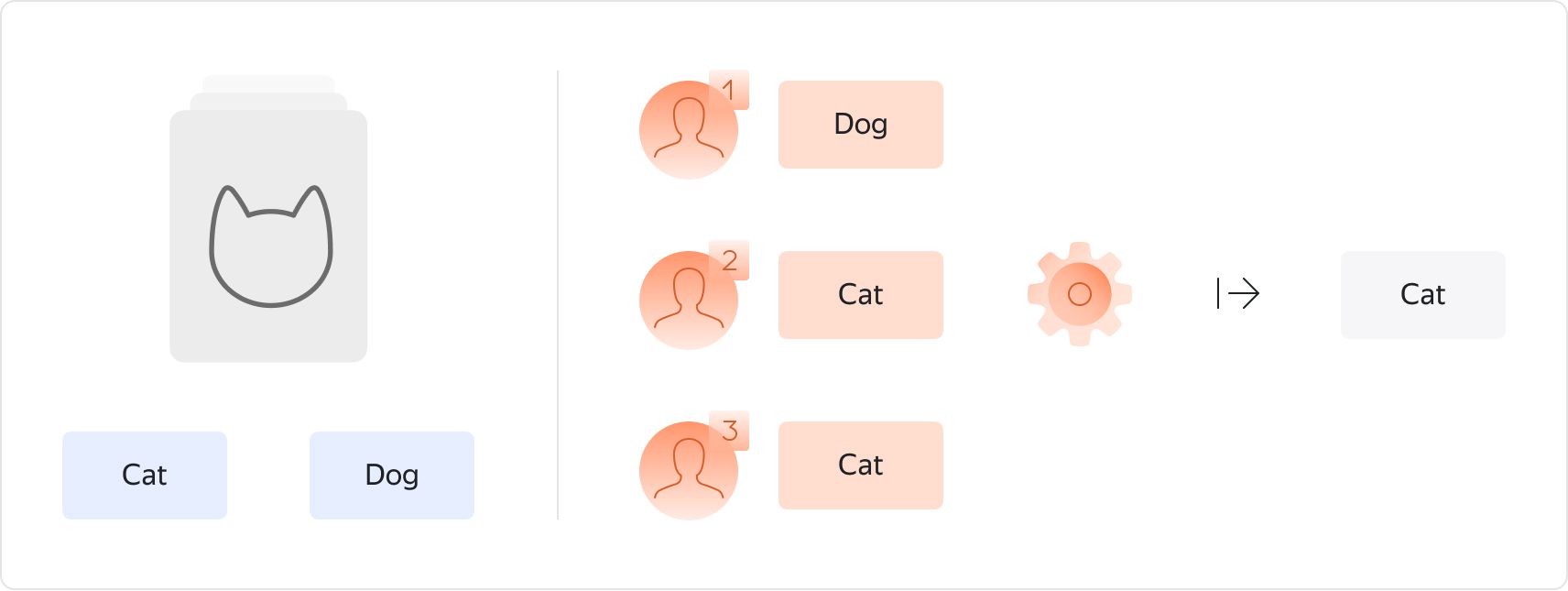
In fact, majority vote often achieves decent results and is used in many real-life projects. It also has the benefit of being very intuitive and practitioners can easily understand the reasoning behind the method. However, in crowdsourcing we operate under time and budget constraints. Hence, our goal is to collect as little data as possible to achieve the desired accuracy. From this perspective, majority vote may not always be the optimal choice. To understand the weaknesses of the method, let's look at the model behind majority vote.
Model
The model behind the method is simple. There are images and workers. Each image has an unknown answer (a cat or a dog in our case). Majority vote assumes that if worker labels image , then the worker gives the correct answer with some probability :
Note that the probability of correctness is assumed to be the same for each worker and for each question. The assumption of ensures that each worker is more likely to give the correct answer than the incorrect answer. Hence, if the number of labels for each image is large enough, majority vote will uncover the true answers with high probability.
Limitations
The limitations of majority vote lie in its simplicity:
- Homogeneity of workers. First, majority vote assumes that workers all have the same ability. In other words, for a given question, the probability that a worker answers the question correctly is the same for all workers. However, performers on crowdsourcing platforms are very diverse — some of them are very careful while others can make careless mistakes. Thus, one direction for improvement over majority vote is to accommodate the variation in performer ability in the model.
- Homogeneity of questions. Second, majority vote assumes that questions are of the same difficulty. In other words, for a given worker, the probability that the worker answers a question correctly is the same for all questions. However, some questions within a project may be more difficult than others. Thus, another direction for improvement over majority vote is to accommodate the variation in question difficulty in the model.