Deep Evaluation
for GenAI
Large language models evaluation platform with
quality metrics to fit every model and scenario.

We know how to measure the quality of LLMs
Large language models (LLMs) offer valuable insights, aid chatbot management, generate high-quality content such as articles, product descriptions, social media posts, can analyze large volumes of unstructured data or analyze market trends. Yet, conventional evaluation metrics can't tell whether your LLM meets your objectives. Toloka's Deep Evaluation platform bridges this gap, offering an extensive range of tailored quality metrics and pipelines aligned with your specific business context.
Be confident in your LLM's performance with our reliable evaluation framework
- Don't let your model give customers false information, or harm revenue with poor fact-checking
- Evaluate your model in real-world scenarios and make enhancements to align with your goals and protect your business from risks
- Make sure you're adopting the best base LLM for your application

Comprehensive evaluation empowers your team to align language model performance with expectations, ensuring outputs are accurate, reliable, and socially responsible.
Why Toloka LLM Evaluation

Tailored performance metrics
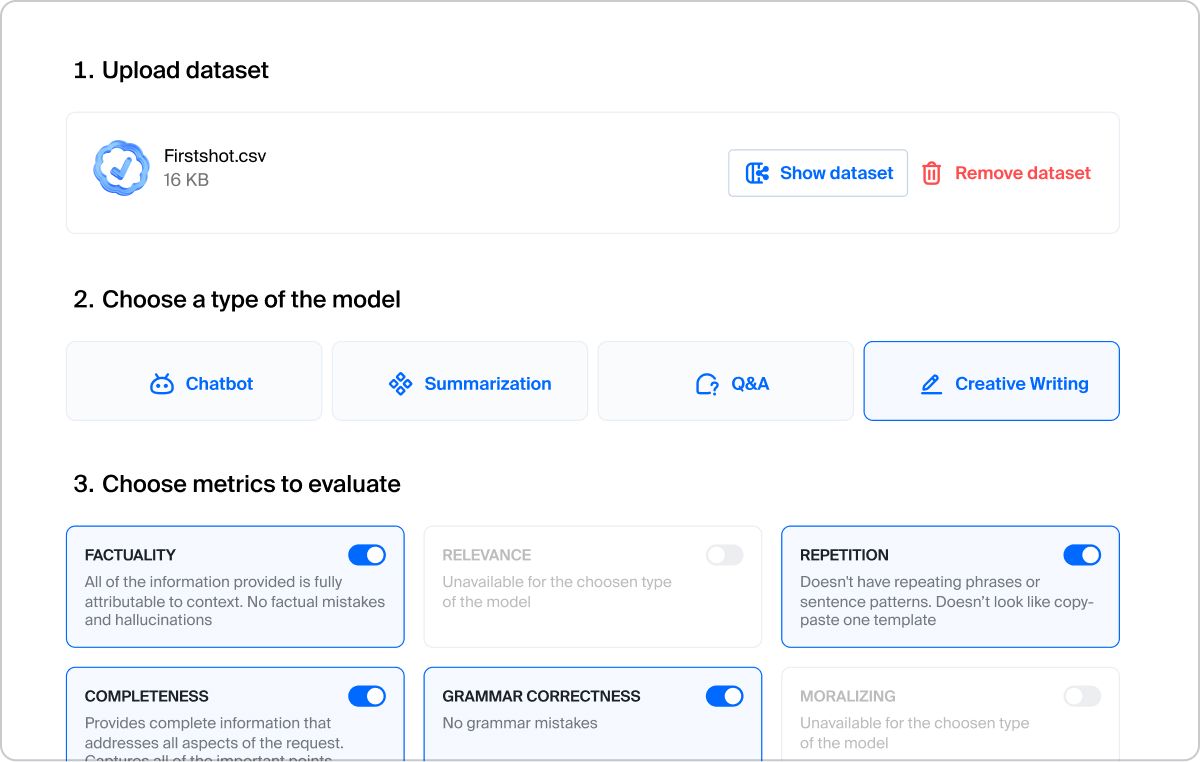
Custom evaluation plan designed for your unique business case with the most extensive range of quality metrics in the market
Scalable human insight
Reliable results from our skilled annotators and domain experts in fields like computer science, EU law, medicine, and more
In-depth evaluation
Our evaluation process harnesses large language models, automated algorithms, and human expertise for deep insights and detailed reports

We capture the right metrics for your GenAI application
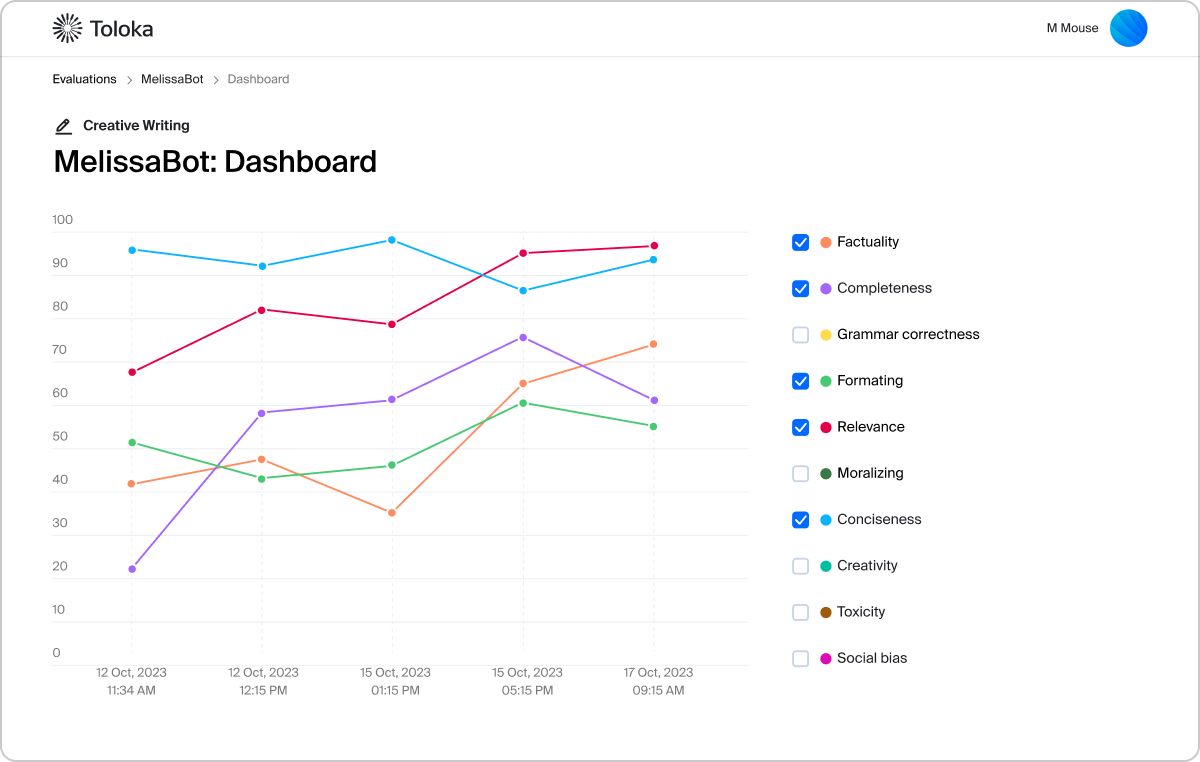
Deep Evaluation in practice
We analyze each model's unique usage scenario and capture the best metrics to measure model performance
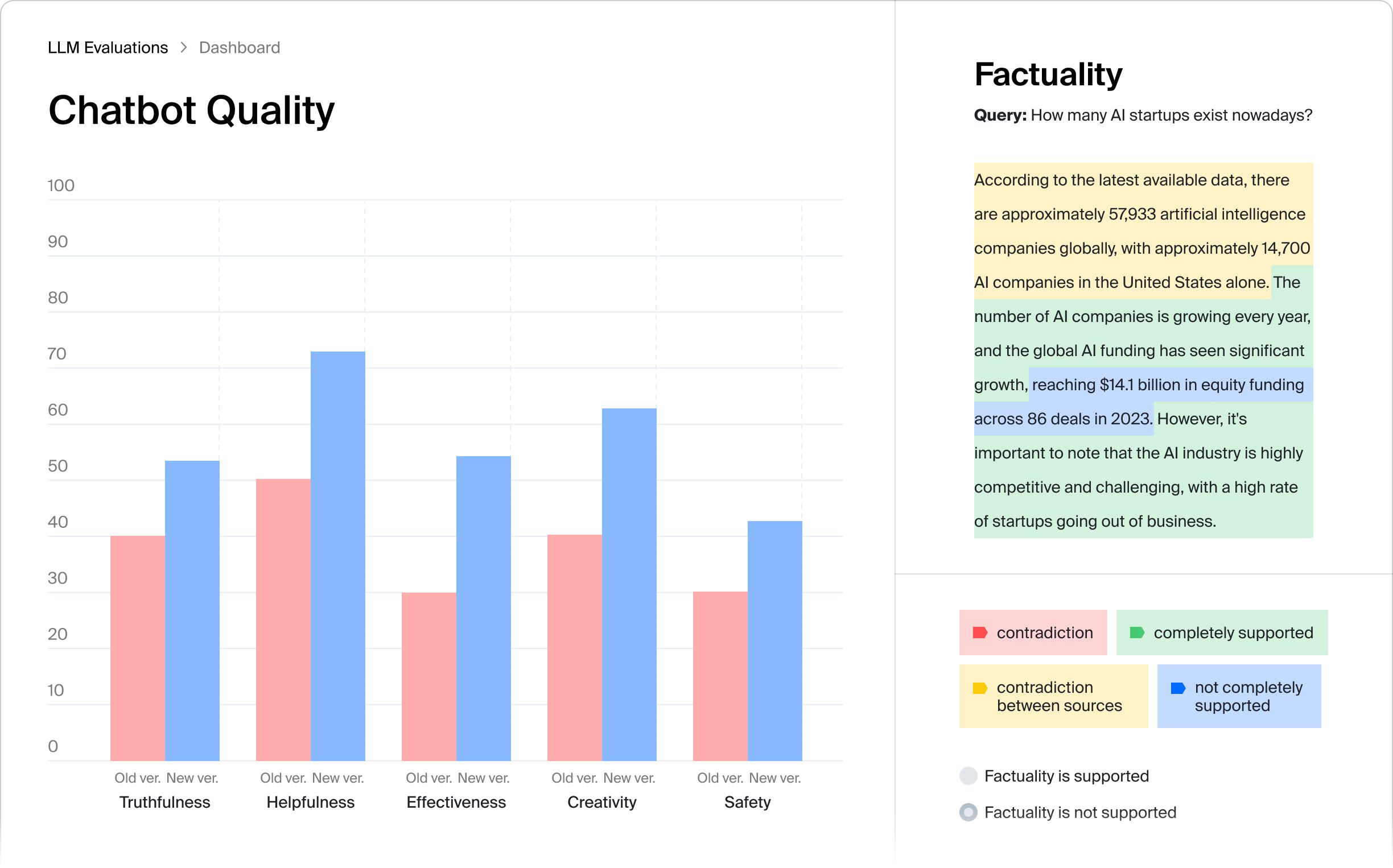
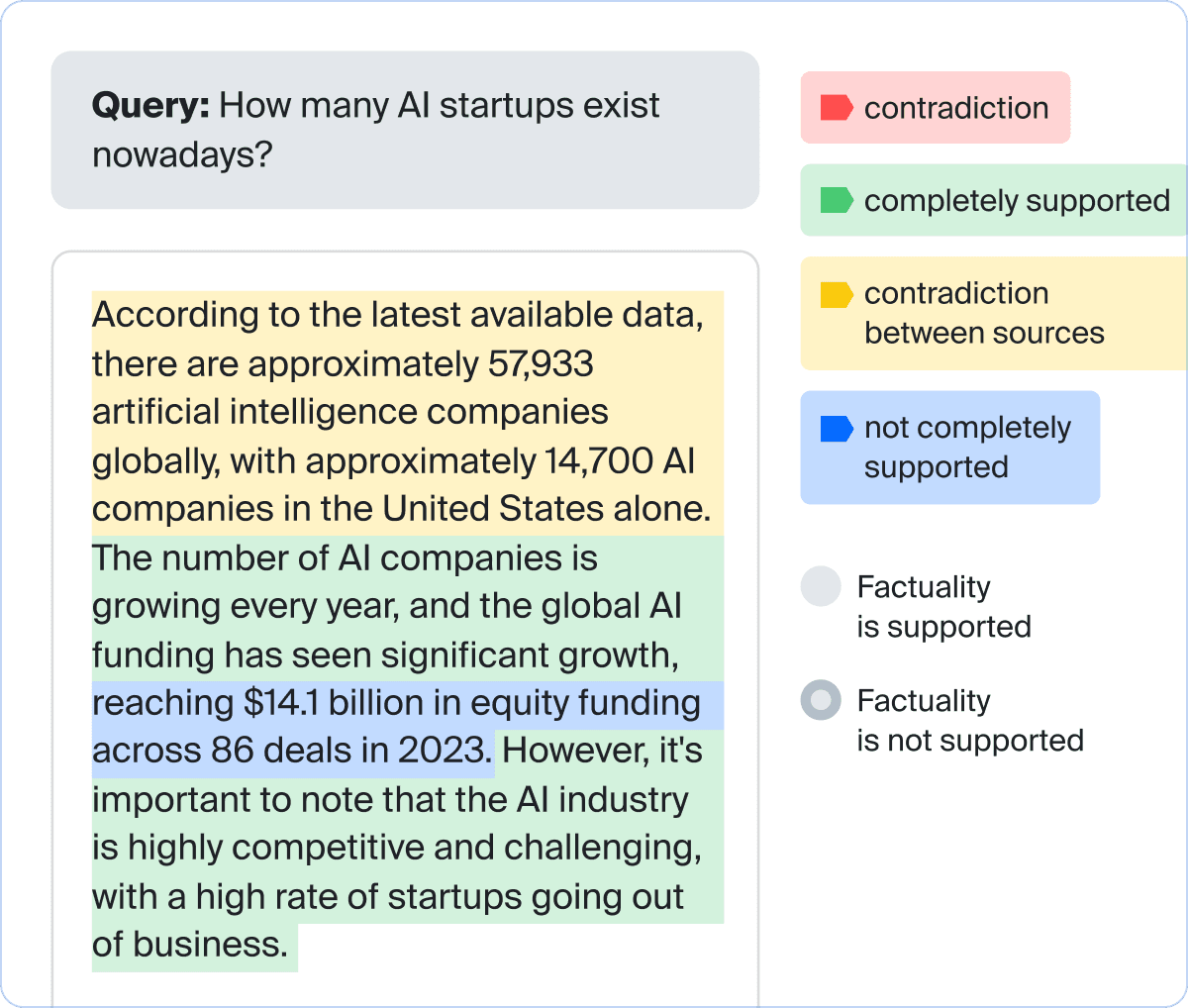
interface and get deep insights into model qualityMetrics evaluated:Helpfulness, Truthfulness, SafetyLink to the full case
Ready for your own evaluation?
Talk to usReady for your own evaluation?
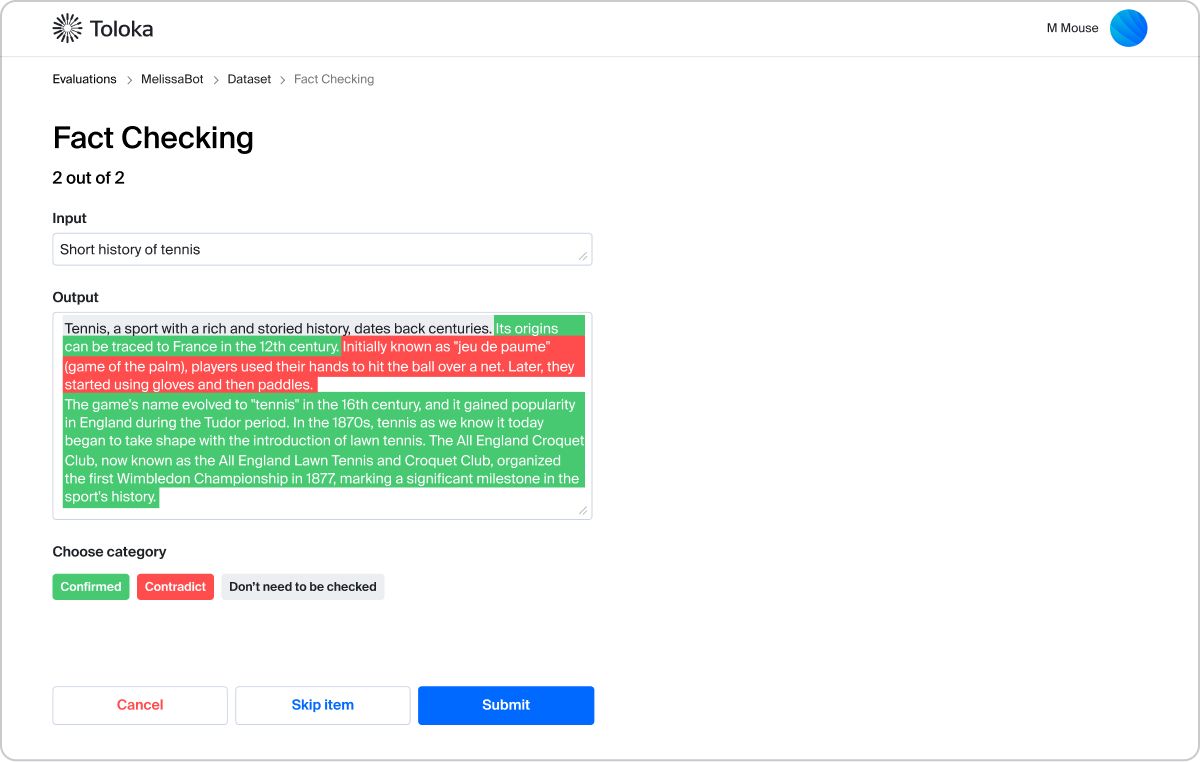
Talk to usHow we do evaluation
1
Analyze your model's performance and usage scenario.2
Propose evaluation metrics that fit the unique context and goals of your model.3
Create an evaluation pipeline that combines automation and human labeling.4
Deliver comprehensive reports with insights on how to improve your model.
Try Toloka Deep Evaluation
for your project
Talk to usFAQs about LLM Evaluation
- Adopting large language models (LLMs) is promising for businesses across multiple domains, but it requires a systematic process involving several key steps:Identification of use cases: It starts with identifying areas where a large language model can add value. They can range from generating content for marketing campaigns to automating customer support.Benchmark selection: Businesses need to set goals for adopting large language models in each case from this broad spectrum of language-related challenges, be it language modeling, sentiment analysis, machine translation, etc.Selection of LLM platform: Then, businesses must choose the right platform that aligns with their requirements regarding natural language tasks, scalability, and customization options.Data Collection and preparation: When the goals and platform are defined, the team must prepare relevant training data, ensuring it is clean, structured, and representative of the intended use cases.Model Training: The next step involves feeding the large language model with the training dataset and fine-tuning it to optimize performance for specific tasks. It usually requires expertise in machine learning.Integration and deployment: Language models trained are incorporated into the existing systems and deployed for practical use. This phase involves testing, validation, and ensuring seamless integration with workflows.Monitoring and Maintenance: Continuous monitoring is essential to ensure large language models perform effectively over time. This includes retraining the model and addressing any issues or updates when needed.
- Evaluating large language models (LLMs) is critical for understanding their applicability across various domains. These are a few real-life scenarios that underscore the importance of assessing LLMs:
- Performance assessment: Companies face the challenge of selecting a foundational enterprise generative model from among multiple options. Evaluating LLMs based on criteria such as relevance, accuracy, and fluency is crucial. This assessment ensures that the chosen language models can effectively generate text and respond to input, meeting the company's requirements.
- Model comparison: Businesses often need to fine-tune LLMs for specific industry tasks. Comparing LLMs allows organizations to identify the model that best aligns with their needs. By comparing factors like performance metrics and task-specific capabilities, companies can make informed decisions to optimize LLM performance.
- Bias detection and mitigation: An inclusive evaluation framework enables companies to detect and address LLM training data and outputs biases. A proactive approach to evaluating large language models for fairness and equity fosters trust and credibility in applying LLMs across diverse contexts.
- Establishing user trust: Evaluating user feedback and perceptions of LLM-generated content is essential for building trust and confidence. Organizations can create reliable systems that inspire trust and confidence by aligning the outputs provided by language models with user expectations and societal norms.
- Evaluating large language models is crucial for their effectiveness and suitability for real-world applications. While traditional methods like perplexity and human evaluation provide valuable insights, emerging techniques can offer more profound analysis.1. Perplexity:Perplexity remains a fundamental metric in language model evaluation, measuring how well a model predicts a given text sample. Lower perplexity scores indicate higher performance, reflecting the model's ability to predict unseen words in a sequence. While perplexity provides a quantitative measure of LLM proficiency, it may not capture language understanding or coherence nuances.2. Human Evaluation:Human evaluators can assess the overall quality of LLM outputs based on predefined criteria such as relevance, fluency, and coherence. This method offers invaluable qualitative insights into LLM performance, but it can be resource-intensive, requiring careful design and training of evaluators.3. Bilingual Evaluation Understudy (BLEU):BLEU is a widely used metric for evaluating the quality of machine-generated text, particularly in machine translation. It compares generated text with reference translations, measuring the overlap in n-grams (sequential word combinations). While BLEU provides a quantitative measure of translation quality, it has limitations, often favoring literal translations over contextually accurate ones.4. Recall-Oriented Understudy for Gisting Evaluation (ROUGE):ROUGE assesses the quality of summaries generated by a language model by comparing them to reference summaries. It measures the overlap in n-grams and evaluates aspects like recall and precision. ROUGE is particularly useful for tasks like text summarization, where generating concise and informative summaries is crucial. However, like BLEU, it may prioritize surface-level similarity over semantic understanding.5. Diversity metrics:Diversity metrics evaluate the multiplicity and individuality of responses generated by LLMs, aiming to ensure varied and comprehensive outputs. Higher diversity scores indicate a broader range of reactions, potentially enhancing the richness and relevance of LLM-generated content. These metrics complement traditional evaluation methods by promoting exploration and creativity in LLM outputs.Additional Evaluation Strategies:
- Semantic Similarity Metrics: Assessing the semantic similarity between LLM-generated text and human-generated references provides insights into the model's language understanding.
- Bias Detection Algorithms: Integrating bias detection algorithms helps identify and mitigate biases in LLM outputs, promoting fairness and inclusivity.
- User Feedback Analysis: Analyzing user feedback and engagement metrics offers real-world insights into the practical utility and user satisfaction with LLM-generated content.
- Evaluating LLMs goes beyond traditional intrinsic metrics, requiring a comprehensive approach combining quantitative analysis, qualitative assessment, and contextual understanding. Several critical factors come into play when evaluating Language Models (LLMs) for business use. Each of them influences the model's effectiveness and suitability for integration into business operations:
- Accuracy: The foremost consideration is the LLM's ability to produce precise outputs relevant to the intended task. High accuracy ensures the generated content aligns closely with the desired objectives, minimizing errors that could impact decision-making or user experience.
- Scalability: As businesses evolve and expand, the LLM's scalability becomes paramount. It should handle increasing volumes of data and requests without compromising performance or efficiency.
- Speed and Efficiency: Speed is crucial for ensuring timely interactions and maintaining productivity. A fast and efficient LLM enhances user satisfaction, supports real-time decision-making, and facilitates seamless integration into business workflows.
- Adaptability: Businesses operate in diverse environments with constantly emerging unique challenges. Therefore, the LLM should offer high customization to accommodate industry requirements and specific corporate needs. Customization capabilities enable businesses to tailor the LLM's functionality and outputs to align precisely with their objectives and preferences.
- Ethical considerations: Bias mitigation is crucial in deploying LLMs, especially in sensitive areas such as decision-making. Ensuring that the LLM operates ethically and upholds principles of fairness, transparency, and accountability is essential.