Empower AI Development and
LLM Fine-Tuning






20+
knowledge domains
20+
coding languages
47%
40+
natural languages
Math
Coding
Linguistics
ESG
Legal
Civil engineering
Compliance
Automotive
Finance
...





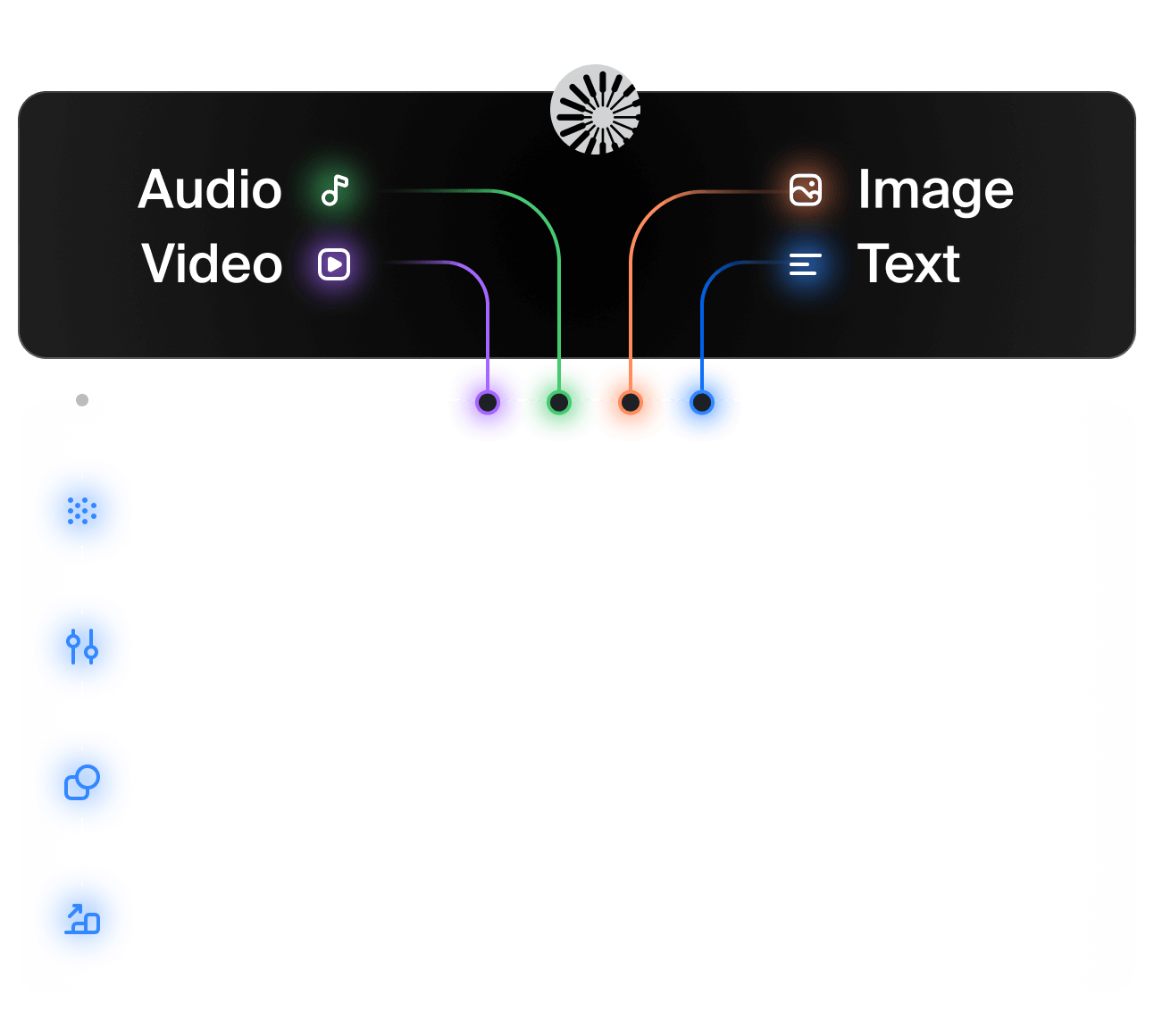
Multi-turn and single-turn
Agent-based dataset
Step-by-step explanation of answers

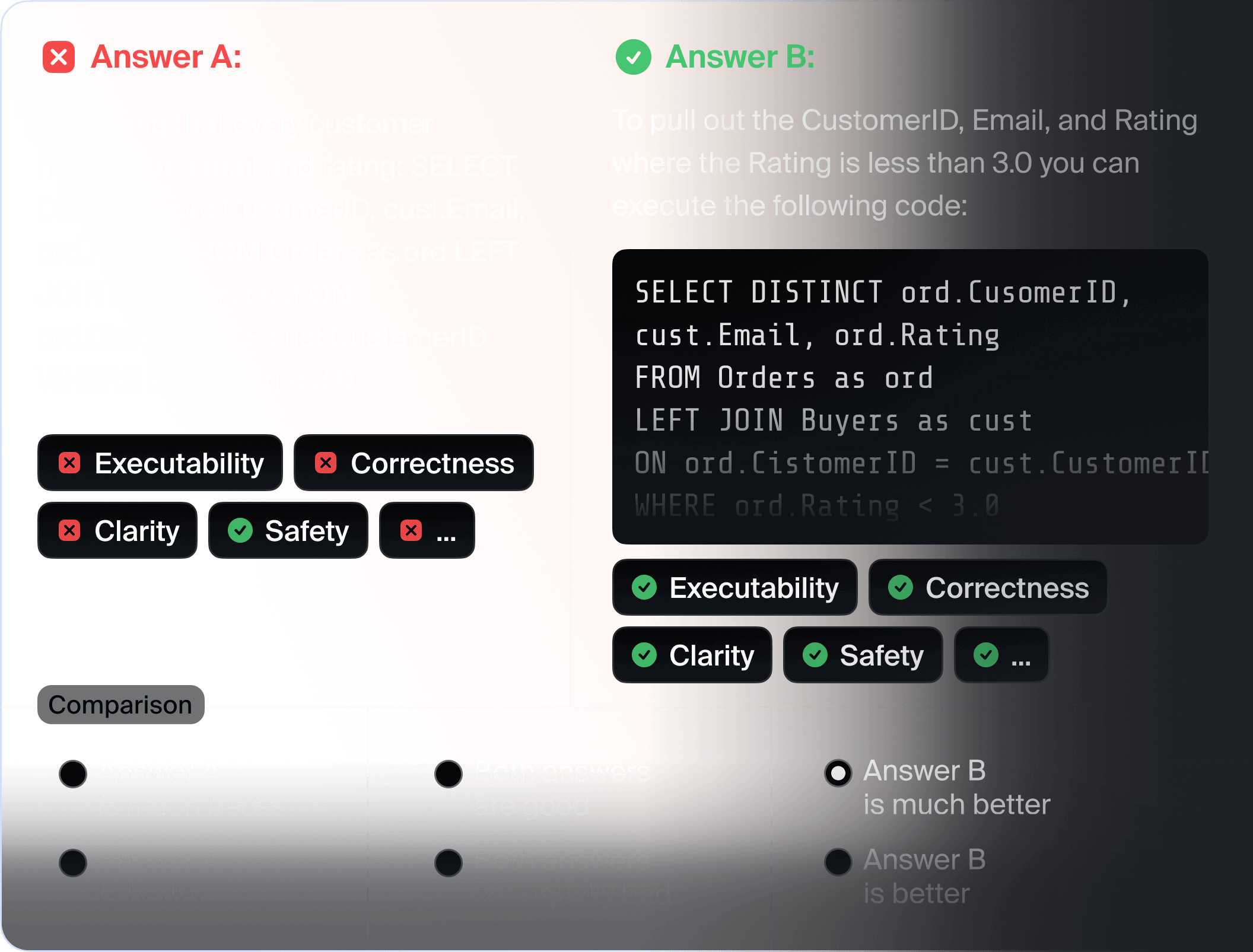
Human-in-the-loop:
Evaluation with trained global crowd
or experts via a simple API
Golden benchmarks:
Pre-defined or custom evaluation datasets
designed by ML engineers and domain experts
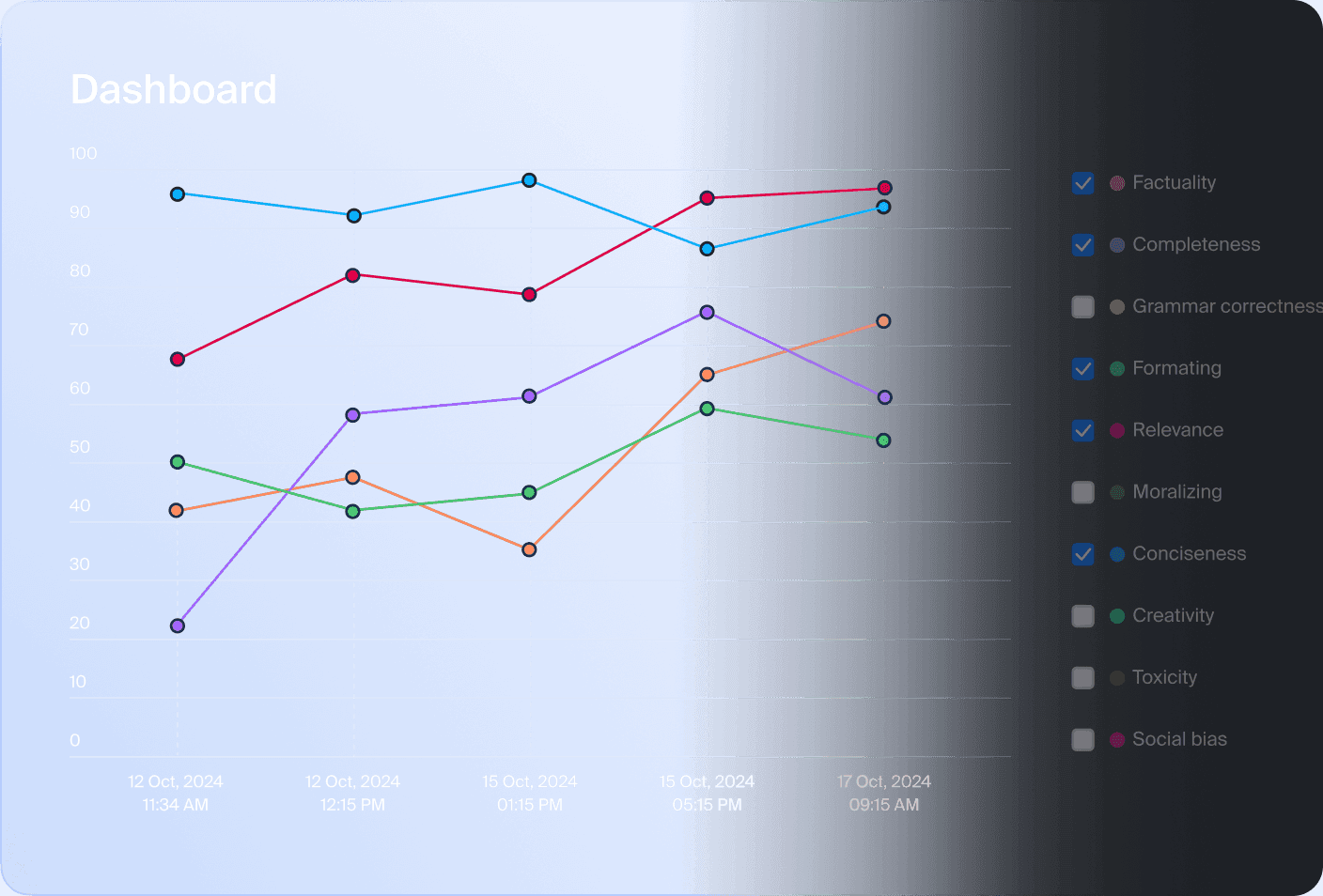

















50+ methods
of automated Quality Control
61 methods
of platform-level
Antifraud
Co-pilots automate experts' routines to increase efficiency by 45%
Advanced tech platform and 10+ years of expertise ensure operational excellence
Skilled experts in 20+ knowledge domains and 120+ subdomains
Largest global crowd – workers from 100+ countries speaking 40+ languages
MS Azure as base infrastructure, private and on-premises data storage options
ISO 27001 & ISO 27701 certified
SOC 2, GDPR, CCPA
and HIPAA compliant
