
Your one-stop
data labeling platform
Fast data iterations and easy scaling to support AI/ML development.
Two-sided platform engineered for scalability

Platform delivery models
- Self service
Tune your project with a wide range
of quality control tools and technologies - Managed service
Request a bespoke solution designed
for your use case by our experienced team
Crowd options
- On-demand global crowd
Access millions of Tolokers available 24/7 - In-house workforce
Invite your employees or contractors
to label your data in Toloka
Platform capabilities
ML technologies
- One platform to manage human labeling & ML
- Prebuilt scalable infrastructure for training and real-time inference
- Flexible foundation models pre-trained on large datasets
- Automatic retraining and monitoring out of the box
Diverse global crowd
- 100+ countries
- 40+ languages
- 200k+ monthly active Tolokers
- 800+ daily active projects
- 24/7 continuous data labeling
Crowdsourcing technologies
- Advanced quality control and adaptive crowd selection
- Smart matching mechanisms
- 10 years of industry experience and proven methodology
- Open-source Python library for aggregation methods
Robust secure infrastructure
- Privacy-first, GDPR-compliant focus on data protection test
- ISO 27001-certified
- Multiple data storage options, Microsoft Azure cloud
- Automatic scaling to handle any volumes
- API and open-source libraries for seamless integration
Data types
Collect, classify and annotate text, images, audio and video with our purpose-built data labeling and collection platform.
How our platform works
- Data labeling and collection
- 1
Pick a project preset that matches your task and the type of data you want to collect or label. Or start from scratch and design your own template.
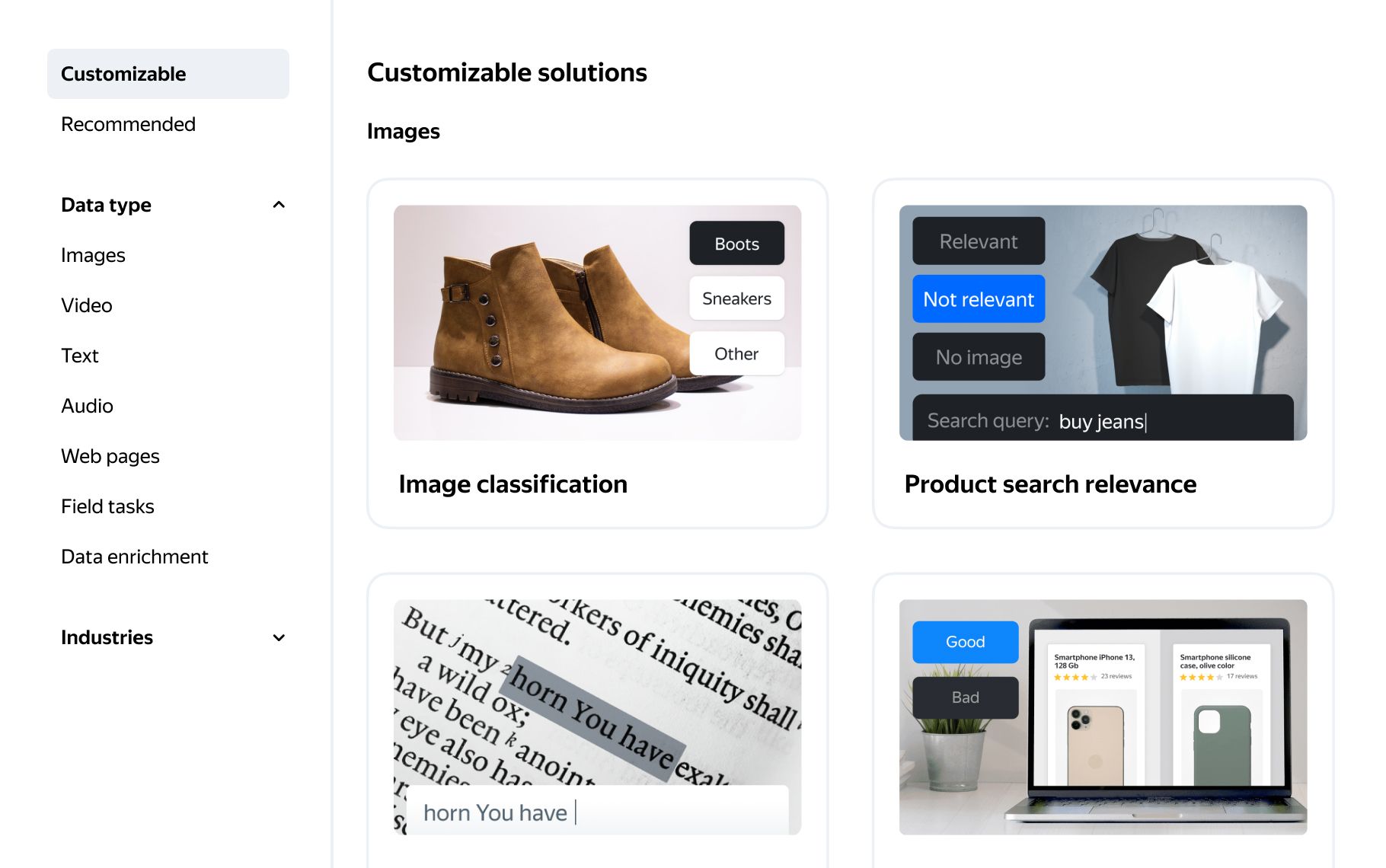
- 1
Customize settings to choose the audience, quality control methods, and other options.
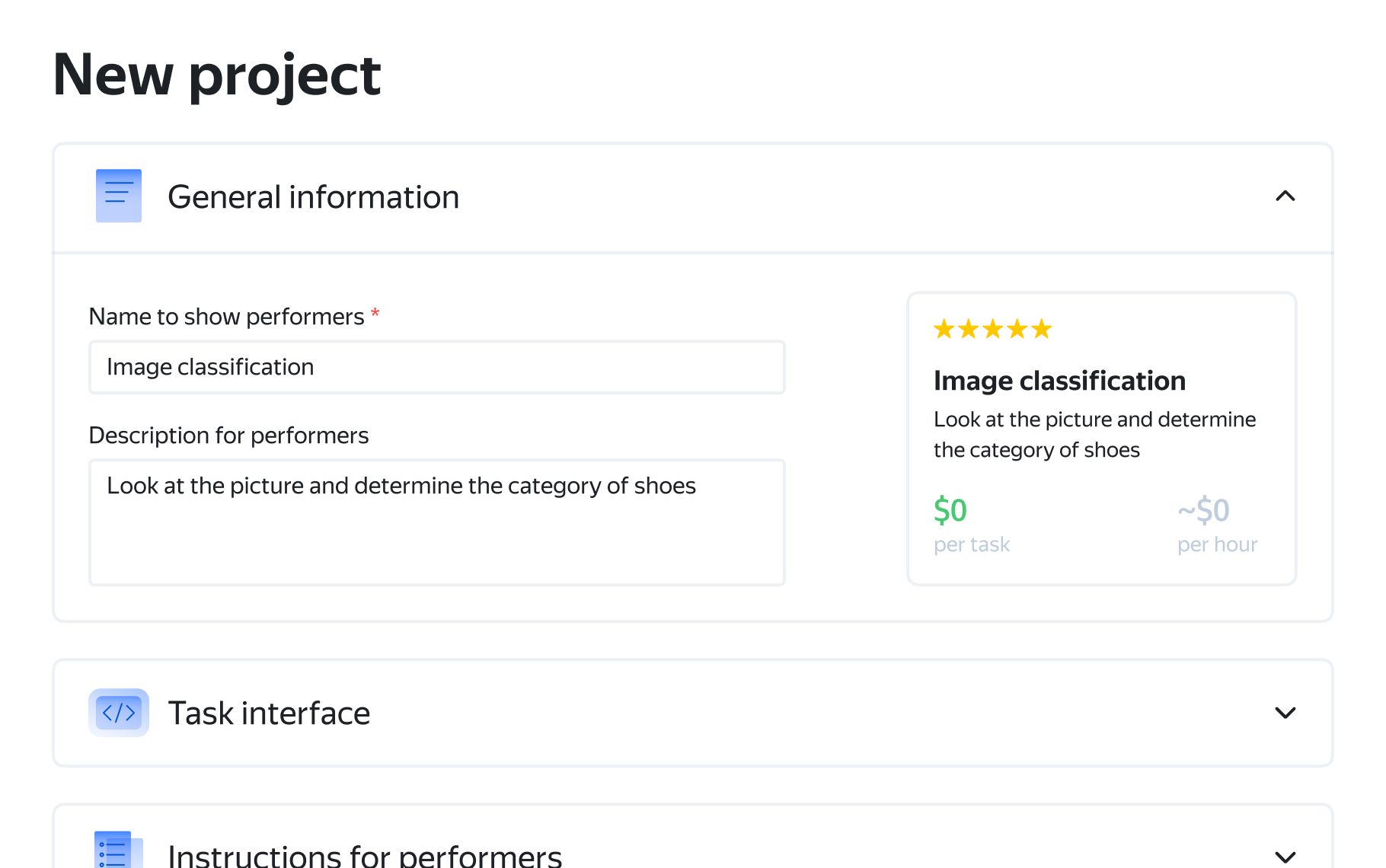
- 1
Upload the first batch of raw data for labeling. Launch your pool of tasks and monitor progress as tasks are completed.
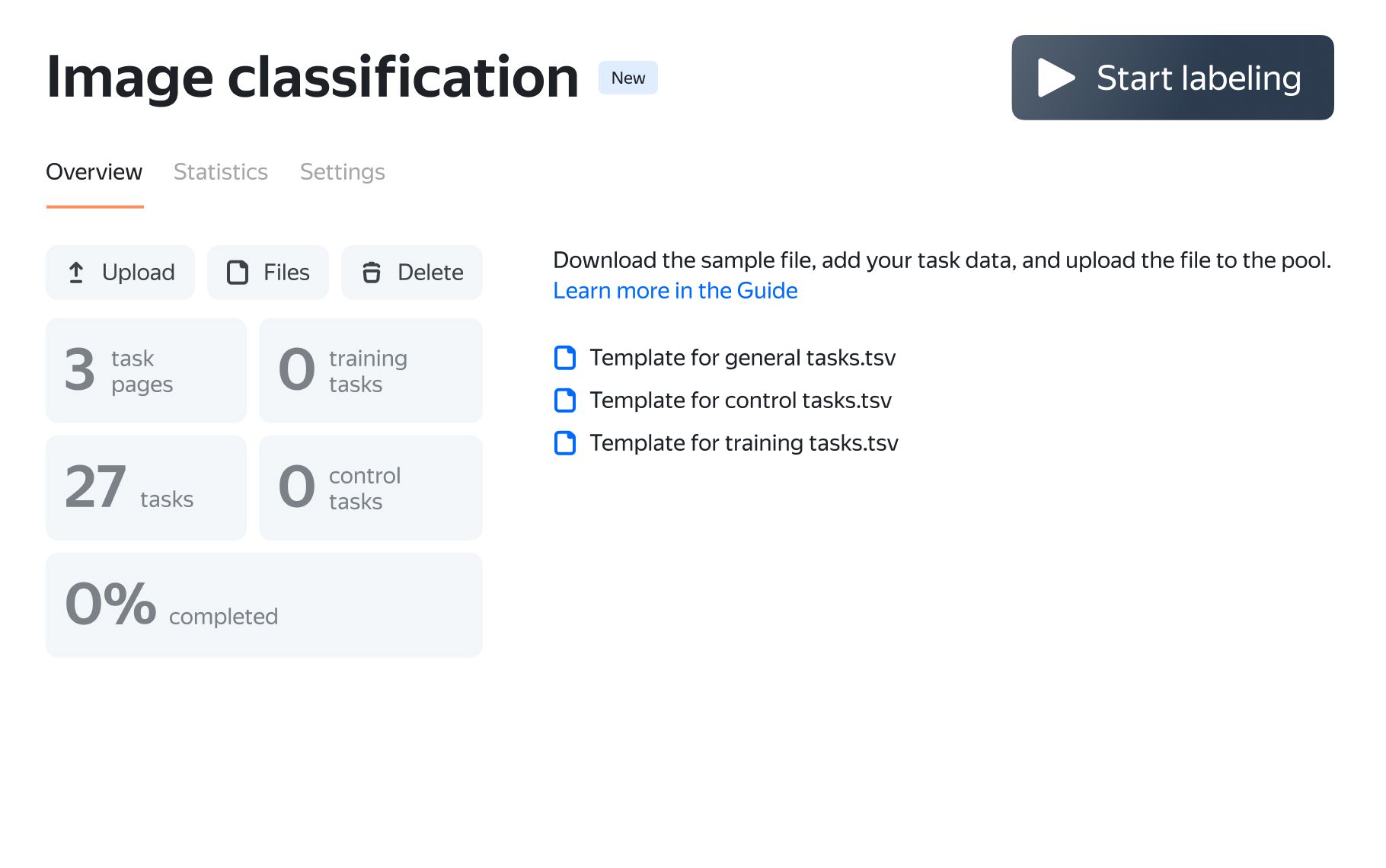
- 1
Download the file with results and use our aggregation tools to get ground truth data.
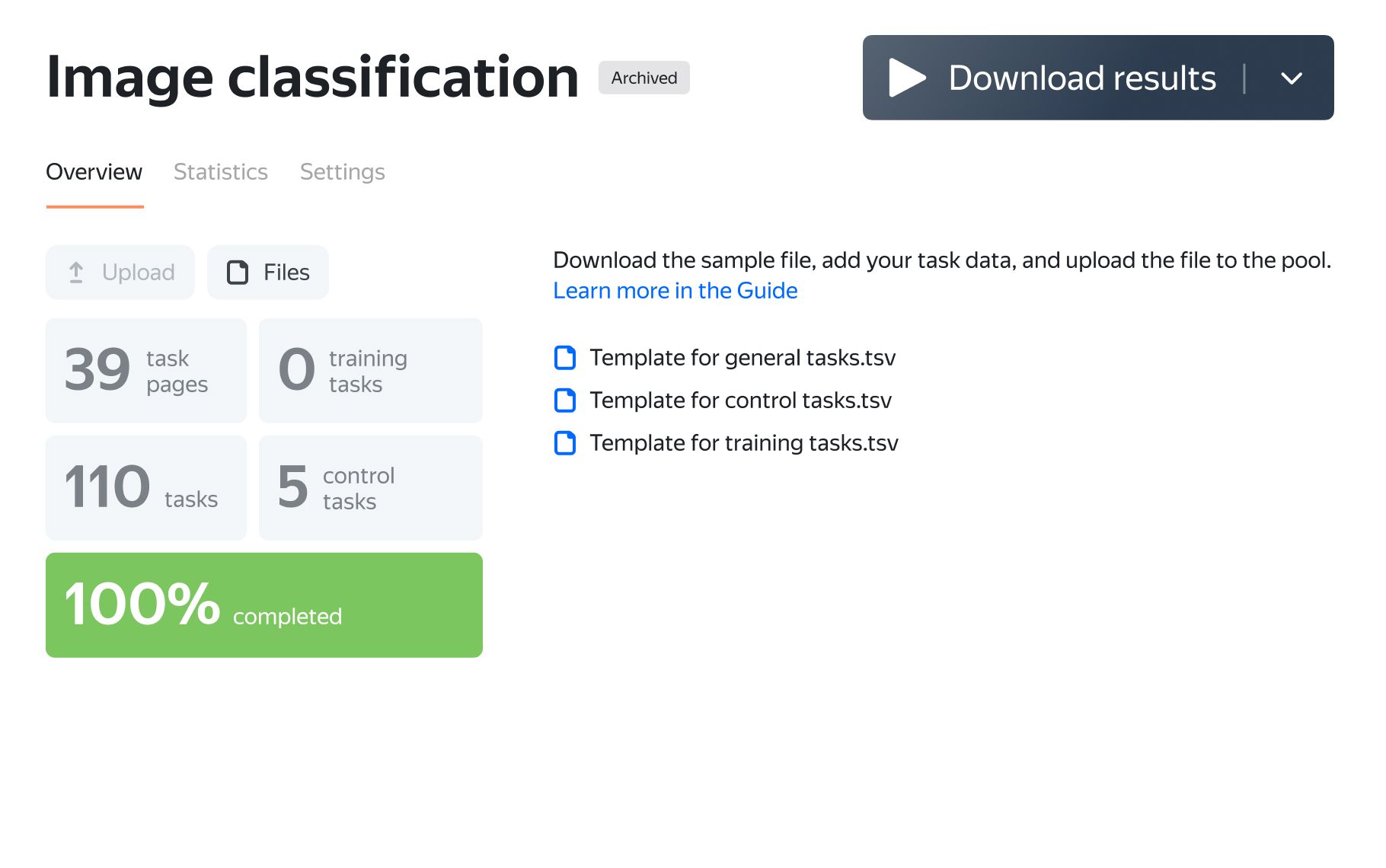
- 1
Tweak settings to improve results for the next batch of data.
How to ensure
quality
- Build flexible quality control pipelines with crowd filters,
golden sets, state-of-the-art aggregation methods, and more - Real-time anti-fraud checks are built into the platform
to detect bots and prevent problematic behavior
Why engineers love Toloka
Our platform is purpose-built to meet the most challenging data demands.
- Fast scalability
- Short turnaround time
- Wide range of quality
control tools - Real-time data labeling
- API and Python SDK
for easy integrations - Clear pricing
Flexible task interface
Template Builder for quick adjustments
Tweak the task interface in our no-code visual editor, or use
the JSON-like code editor with snippets and real-time previewHTML/CSS/JavaScript for full customization
Design your own task interface from scratch or start with
our flexible templates — create a custom task of any complexity
For developers
Python SDK
Our Python toolkit covers all API
functionality to give you the full
power of TolokaJava SDK
Our Java client library provides a lightweight
interface to the Toloka API that works
in any Java environment
FAQ on
data labeling
- Toloka's self-service data labeling platform offers the unique opportunity to access our global crowd of millions and advanced technologies for managing data quality, giving you complete control over the process and the price. Toloka is a great choice if you are looking for:
- Instant scalability and multiple languages for labeling data
- Advanced technologies for managing data quality
- Training data for machine learning models involving computer vision, object detection with bounding boxes, natural language processing, semantic segmentation, image and text classification, video data, and flexibility for any use case
- Raw data collection in almost any format (audio data, video data, text and photos, surveys, and field tasks for checking on-location data)
- A unified environment for data labeling and MLOps that integrates data quality and monitoring, model training, model deployment, and human-in-the-loop flows
- Our crowd of Tolokers is made up of regular people in over 100 countries who want to earn extra money in their spare time by doing micro tasks. Our two-sided platform lets you filter the crowd for your tasks, while Tolokers can choose the tasks they want to do. With people in every time zone who speak over 40 languages, there is always a diverse crowd ready to do tasks 24/7.Toloka's data labeling platform was designed for responsible crowd management with a positive social impact, as recognized in VentureBeat and Tech Times. Learn more about global crowd here.
- Absolutely! If you have employees or contractors who can label your data, you can invite them to access your projects in Toloka. Use this option if you want to combine your in-house expertise with the scalability of our crowd, or if you need to keep your data completely private while benefiting from Toloka's quality control tools and technologies.Toloka's in-house data labeling solution offers transparent workforce management and the option to store data on your premises. Learn more about Toloka In-house labeling here.
- We've spent over 10 years developing practical ways to automate crowd management and quality control for data labeling. The Toloka platform can help you attain high quality training data with scalable data labeling — without devoting resources to people management.These technologies can be combined to fit your scenario: advanced aggregation algorithms, real-time anti-fraud, autolabeling with human verification, a wide range of quality control methods, and intelligent matching to select the best Tolokers for your tasks. Learn more about Toloka technologies here.
- We offer pay-as-you-go pricing with no minimums. Pricing is flexible — you set the price you want to pay Tolokers per task plus a platform fee collected by Toloka. We suggest a fair price based on the task complexity, language, and other factors, but ultimately the choice is yours. See examples of prices in real use cases on our pricing page.
- In addition to our self-service platform, Toloka offers enterprise data labeling solutions: automated pre-labeling, custom datasets, partner solutions for managed data labeling, and other services on request.We can also build a bespoke solution to handle the data labeling workflow for your specific scenario.
- Go to our demos page and pick the use cases that you are interested in for e-commerce, computer vision, content moderation, speech recognition, or surveys.For e-commerce you'll find a wide range of demos: product search relevance, product category classification, generating product descriptions, product recognition in images, accessory recommendations, searching for products online, consumer surveys, and cataloging product names (named entity recognition). Other use cases include image annotation, image classification, video classification, sentiment analysis, voice assistant training, social science research, and more.All you need to do is create a Toloka account and run a free demo to see live data labeling in action.
Where to learn more
Get started now
and expansive industry experience.