
Adaptive AutoMLAdaptive AutoMLAdaptive AutoML
Tune better models faster
Tune ML models to your data streams and automatically retrain them on the latest data in a few clicks.
Tune ML models without coding
Forget about hiring an ML engineering team.
Tune custom models from the browser or APICut time to production
Leverage enterprise-level technologies
to deploy pre-trained models in a few clicksUpdate models with new data
Automatically retrain and monitor models
when new data arrives
Online and adaptive machine learning: how it works
Skip the repetitive steps in the ML lifecycle — let our automated service handle model tuning, evaluation, deployment, and monitoring.
Our adaptive ML models are backed by Toloka expertise in crowd science and machine learning for high quality and throughput.

- Reliable accuracy
Benefit from background human-in-the-loop processes that
keep model accuracy stable over time - Continuous optimization and retraining
Model evaluation and maintenance use HITL processes
for model retraining and updates - No infrastructure needed
Easily deploy intelligent services without investing in infrastructure and tedious ML experimentation processes. Available via API with low latency for model predictions
- Ground truth datasets within easy reach
Integration with the Toloka data labeling platform lets you build ground truth datasets to use for model tuning and measuring model performance during production
Need a custom solution tailored to your needs?
Request a demo
Powerful models for relevant solutions
to real-world problems
Use our pre-trained models out of the box or adapt them to your data streams automatically.
 Try this model
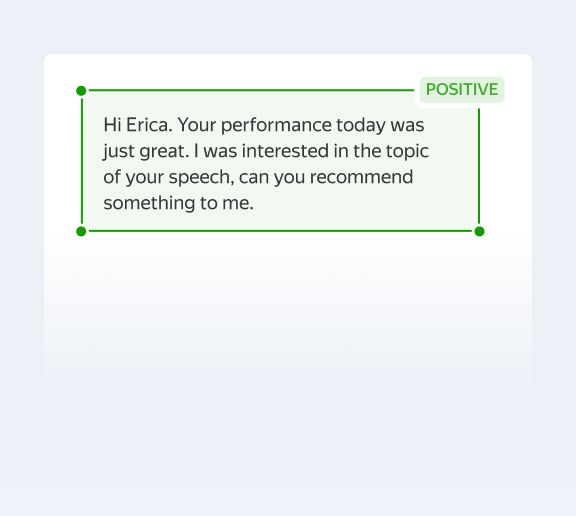
Try this modelSentiment Analysis
Classifies text content into 3 classes — positive, negative, and neutral
 Try this model
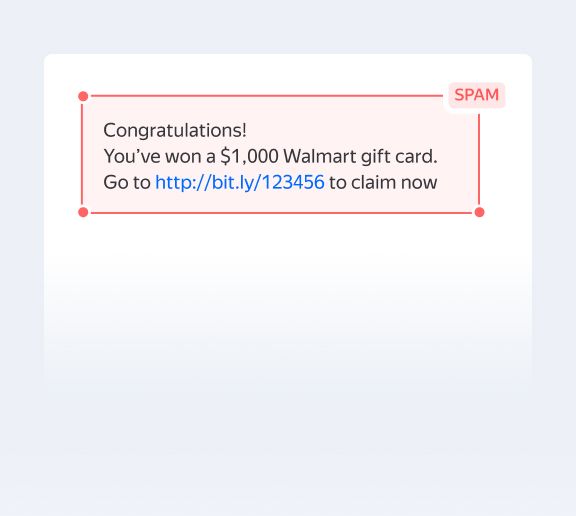
Try this modelSpam Detection
Handles classic spam content classification. Easily tuned to your data streams
 Try this model
Try this modelText Moderation
Detects problematic content like spam, clickbait, hate speech, and profanity
 Try this model
Try this modelImage Moderation
Detects adult content, illegal content, copyright infringement, and other problematic images
 Try this model
Try this modelMultilingual Large Transformer
GPT-3-like model classifies and generates short texts in 12 languages
 Try this model
Try this modelOptical Character Recognition (OCR)
Extracts text from images in more than 40 languages
 Try this model
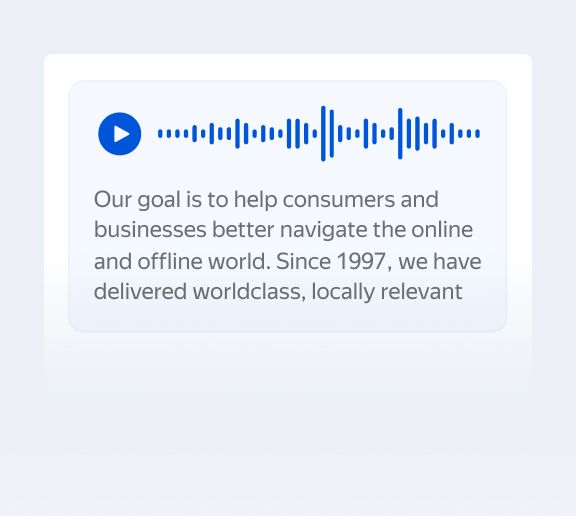
Try this modelSpeech-to-Text
Captures text from audio content in 13 different languages
 Try this model
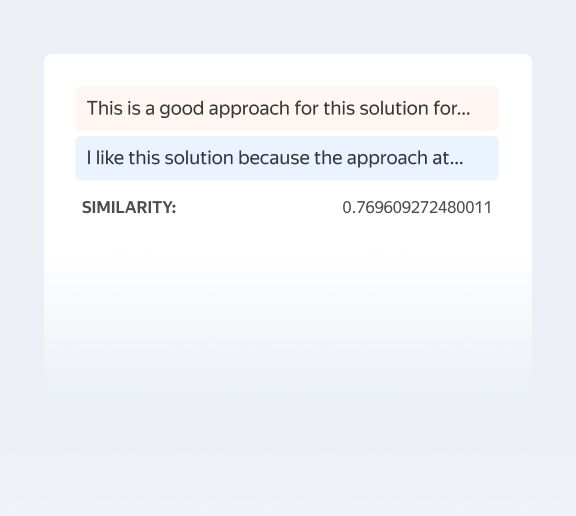
Try this modelSemantic Similarity
Compares 2 texts based on similarity in meaning
Explore other models available to you on our model podium
at Toloka ML Platform
Discover how adaptive models
can make an impact
Learn how solutions using adaptive machine learning models impact
social media monitoring (SMM) for a large IT corporation.
Want to see results like this? We can help you find the right solution!
Next-level automation: MLOps with the Toloka ML platform
Build your own ML pipeline on the Toloka ML platform with support for the full ML lifecycle:
- experiment tracking
- dataset versioning including EDA tools
- model management with versioning and tagging
- visualizations, reports and diff tools
- Python API for access from any environment
Take advantage of native integrations of tracking metrics, Toloka data labeling, and pre-trained models.
Explore the Toloka ML platform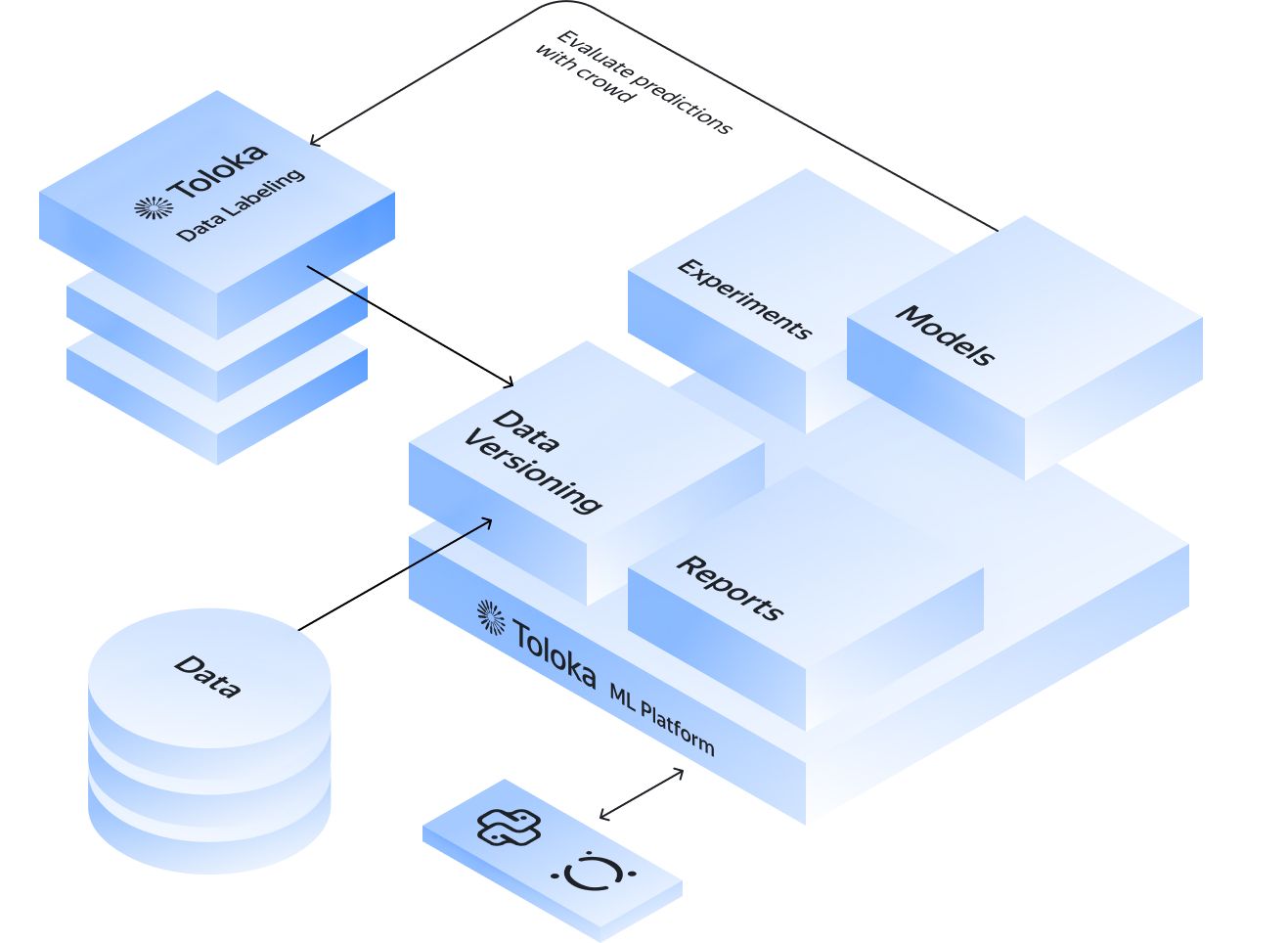
FAQ about
adaptive
auto ML
- Adaptive machine learning models are implemented in production with a process that automatically samples and re-labels data that is sent to the model for inference. This data is used for regularly evaluating model performance online in real time. When metrics start to decay on the new data, tuning is triggered automatically. This feature is continually running in the background to adapt Toloka models to your data.
- Toloka offers adaptive ML as a remote API with methods available in the model interface. Models are available with two modes of interaction: online (real-time) inference and batch inference.
- Online inference is when the model provides a synchronous response for each data item sent for inference. This mode is appropriate for use cases when the response is needed within seconds, like customer support automation or content moderation.
- Batch inference is when the model posts results after processing an entire batch of data. This mode works better for use cases that involve gathering a batch of data over time and evaluating it, like social media monitoring and analysis.
Our off-the-shelf models support only online inference mode in the closed beta, but custom models can be set up with batch inference support.
- Toloka has the capability to deploy and monitor models in any cloud environment of the customer's choice, or on the customer's premises in some cases. By default, Toloka uses Microsoft Azure infrastructure to provide resilient, compliant, and geographically distributed service hosting.
- Toloka models are trained on very large datasets with multiple sources of data. Some of these include open-source data and public data curated with the help of the Toloka crowd. Toloka also uses proprietary non-public data sources that are gathered and labeled via crowdsourcing with the expertise of our R&D team. We use state-of-the-art technologies to generate high-quality non-standard datasets for search relevance evaluation, e-commerce product categorization, evaluation of semantic similarity, and more.
- There are 3 ways to use Toloka's collection of pre-trained models:
- Use the models as-is for standard classification, recognition, or generation tasks.
- Fine-tune a model on a pre-labeled dataset that you provide.
- Deploy a model with the Adaptivity parameter, which triggers the process to collect and label the fine-tuning dataset on a regular basis.
If you are interested in fine-tuning an algorithm right before deployment, you can label your historical data first on the Toloka data labeling platform.
- Toloka adaptive models support schedule-based or event-based triggers for re-training and fine-tuning. The best approach depends on the scenario. This could include re-training once a day, when accuracy drops below a threshold for new data, or when the "adaptivity" process collects a certain amount of data. We recommend using the default settings designed for each model by our machine learning engineers to best fit the use case and domain.
- As approaches to machine learning evolve, new terms are sometimes used to describe dynamic learning processes, such as adaptive learning, continuous learning, and continuous training. While these concepts do not have standard industry definitions, they attempt to differentiate the learning process from both traditional machine learning with static data collection and online learning with streams of real-time data. We use the term adaptive ML because adaptivity ensures that model predictions remain relevant even in fast-changing environments.Our adaptive models eliminate data and model drift in machine learning models by continuously supplying them with new data points. Once set up, predictions of your model are sampled for human annotation on Toloka, so your model becomes re-trained over time on our platform. Our AutoML capabilities allow you to always select the best model based on objective human evaluation.