Quality Control
Carefully plan and configure a quality control system to ensure high-quality results.
Subscribe to Toloka News
Subscribe to Toloka News
Quality control is essential. You have a large crowd of people completing your tasks, and you want to make sure that they understand the instructions, they're paying attention, and they aren't trying to use bots. Use a combination of strategies to manage the crowd and achieve the best quality.
Designing quality control is a multi-stage process. It starts with decomposing a task, writing instructions and designing a clear interface. All these things help to eliminate misunderstandings and guide the Toloker through the task. The next steps are:
- Pre-filtering Tolokers to match project goals
- Using an entrance test to check if the guidelines were understood
- Creating a training project that explains all necessary rules
- Checking the quality of responses
- Tracking behavior in the project
- Using smart response aggregation
The results of all these checks can be converted into specific Toloker attributes that reflect their quality and behavior.
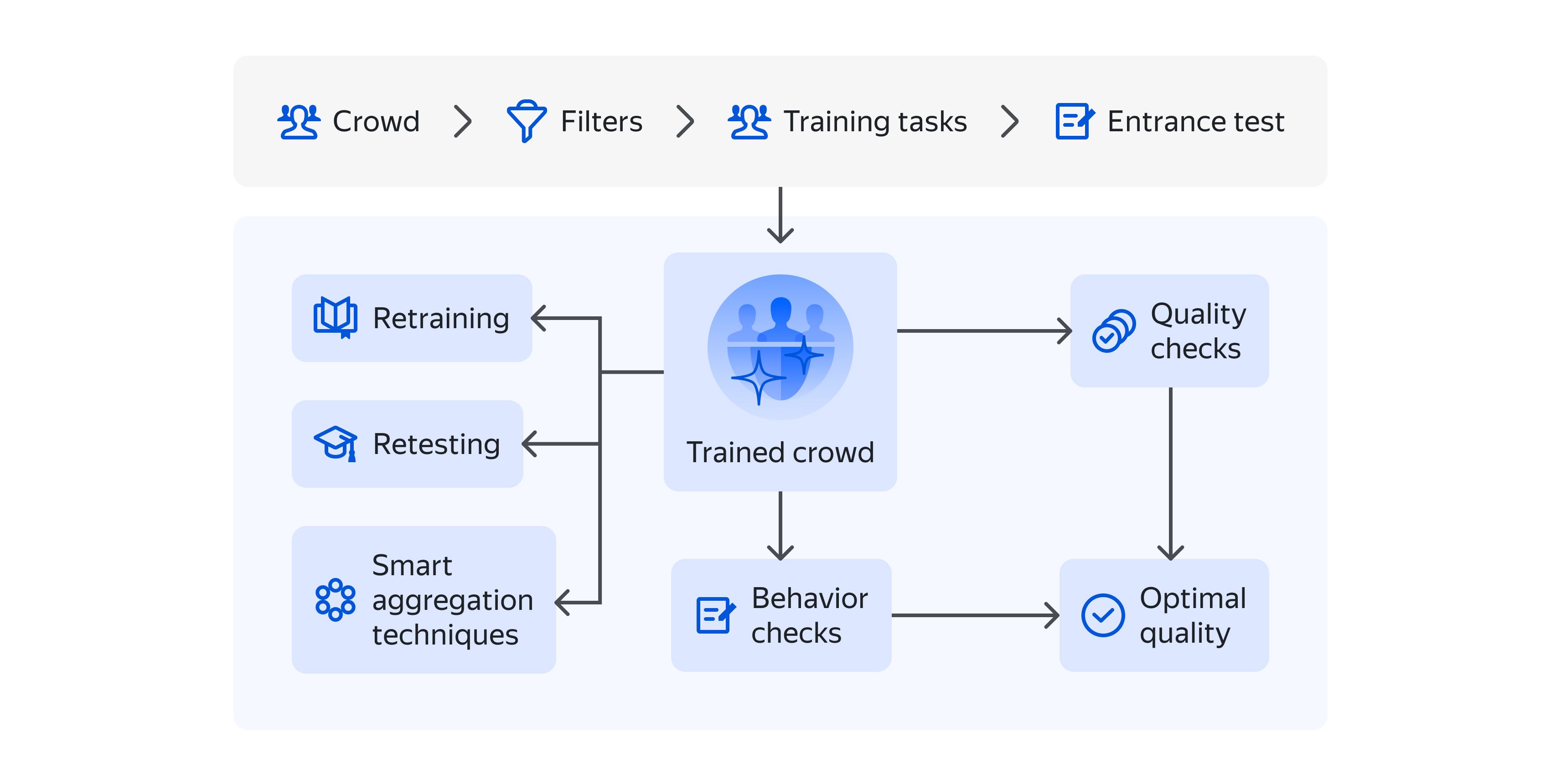
Selecting Tolokers
Though it is not a quality control mechanism in a literal sense, this is a very important step and the best investment in terms of both data quality and requester's time spent. You can create a foundation for stable data quality by explaining the guidelines and testing Tolokers before they get access to the project. Create a comprehensive and clear training set and a corresponding test so that you can recruit new Tolokers whenever necessary, without wasting your time on manual selection.
Pre-filtering Tolokers means offering the task only to people who have certain attributes necessary for the task. Different crowdsourcing platforms may offer different filters, but most popular are location, age, gender, known languages and devices. If you have good reason to believe that some of these properties will affect task performance, try using these filters. Here are some examples when filters might be useful:
- If your project involves working with content in a certain language, give access only to users with corresponding language skills.
- Using an entrance test to check if the guidelines were understood
- If your project involves UX testing for a product that has an age-based target audience, send tasks to Tolokers in the same age group.
For more information on filters available on Toloka, see the docs.
Synchronous quality control
Most quality control methods are designed to control crowd behavior and assessments with the smallest delay possible. It is important to detect low-quality annotators quickly enough before they produce too much useless data and too much money is spent. The following sections describe some of the popular control mechanisms available on crowdsourcing platforms.
Checks like these are designed to reveal if a person regularly demonstrates suspicious behavior, like clicking through tasks too quickly and inattentively. Here are some popular approaches to control bot-like behavior:
- CAPTCHA. This is a well-known tool that helps filter out bots by displaying an image with a text that a user needs to decipher and enter. It's a great basic mechanism, but it's better not to rely solely on it because it only helps to filter out bots or users who don't pay any attention at all. Besides, regular users also tend to make CAPTCHA mistakes because CAPTCHAs may be complicated or just irritating. Best practice here is to ban users only after a certain number of missed CAPTCHAs in a row (more than one).
- Speed monitoring. For every crowd-based task there's a reasonable amount of time it takes to understand the task and make an assessment. If a certain user regularly closes tasks much faster than the average time, they're probably just clicking through the tasks without looking at them carefully. The suspicious speed is different for every project, but it can be defined as 10-20% of the normal speed in the project. If a Toloker submits a string of tasks under this limit, it's better to single them out and ban them from the project.
- Checking for certain actions. A crowd task is basically an interface that allows you to implement any controls or checks based on Javascript. If a task involves interaction with content like playing a media file, visiting a link, or typing in text, these interactions can be checked and analyzed. As discussed in the Interfaces section, some of these checks can be transformed into warnings. Another option is to keep a record of Toloker actions and calculate attributes based on how diligently a user handles task content.
Asynchronous quality control
Synchronous quality control methods are only applicable to tasks where there's a single correct answer. But not all crowd tasks are like that: some demand a creative approach or content processing and can have a variety of correct solutions. Tasks like these can be checked via assignment review. There are two possible ways to review a task:
- The review can be done by someone on the requester's side. A crowdsourcing platform may even have this option in its UI. But this is only a viable option for very small data volumes (or for requesters with unlimited resources).
- Other Tolokers can do the review. This requires starting a new project using marked data that is transferred from the first project and asking Tolokers whether the task was completed correctly. After verification, incorrect tasks are transferred back for evaluation, payments ar made for correctly completed tasks, and individual quality can be calculated.
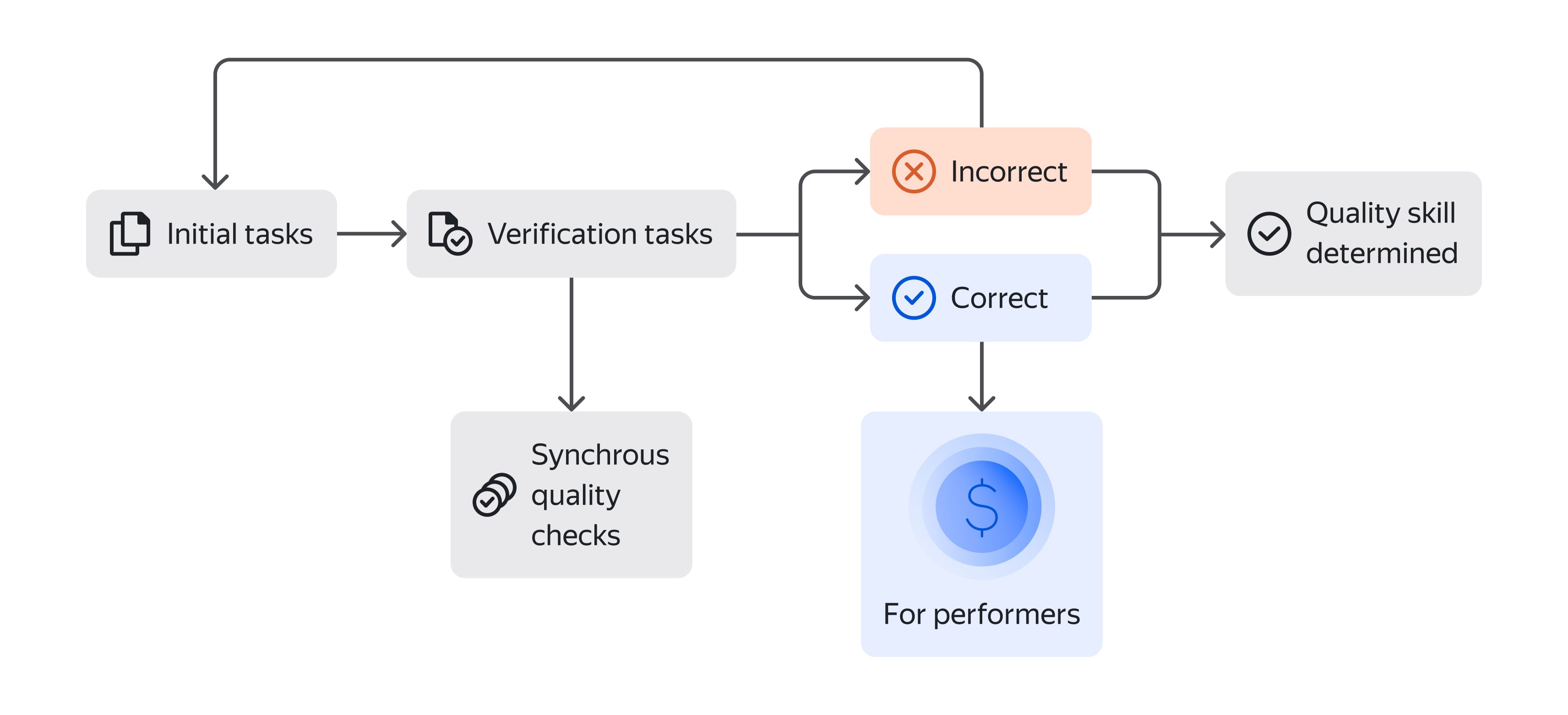
See the docs for a step-by-step description of assignment review settings.