← Blog
/

LLM QA: Scaling data quality assurance technologically
High-quality human expert data. Now accessible for all on Toloka Platform.
The data needed for frontier AI development is drastically changing as models become exponentially more capable. Acquiring high quality data at the rigor, complexity, and scale required by these labs has simply become harder. Models are capable enough now that the gaps in their reasoning don't announce themselves. They show up as subtle logic failures that a human reviewer might catch, but standard human review can't keep up with the throughput frontier labs need.
If you’ve run annotation pipelines long enough, you know how human QA scales. It relies on operations. You hit a throughput ceiling fast. Costs become exponential right at the exact moment you are under the most pressure to deliver.
We realized we needed to stop treating this as an operations bottleneck and reframe it as a technological one.
The core insight here is that generating perfect output from scratch is a highly complex, unconstrained task. But having an LLM verify existing work against a strict, predefined set of rules is a much simpler problem. It’s bounded.
So we built LLM QA, an agentic autocheck running on every submission.
It acts as a forcing function, handling the high-volume verification so expert human judgment is reserved only for edge cases where it truly matters. But throughput is only half the value. Every submission that goes through LLM QA comes back with feedback that helps annotators understand and correct their own work, closing the quality loop in real time, not after the fact.
An agent, not just a prompted LLM
This isn’t your standard LLM-as-judge setup where you pass text into a zero-shot prompt. It’s a fully equipped agent operating within an environment.
We enforce a deliberate constraint: one metric, one entity, one verdict. Asking a single agent to evaluate multiple attributes simultaneously is how you get imprecise, averaged-out verdicts that provide zero actionable signal.
Because it has an environment, it can use tools to investigate the submission. The agent can …
Download web pages
View images
Process audio or video
Run Python scripts
Execute bash commands
If your quality criterion dictates that a product page needs to resolve and match an annotator's description, the agent actively checks the URL.
Pass, fail, and the necessity of "unable to verify"
LLM QA launches a separate instance for every single quality metric. It gets the task, the annotation guidelines, and the specific entity being evaluated. The agent returns a deterministic score measured strictly against your project's quality criteria. The scale is intentionally rigid: Pass, Fail, or Unable to verify.
That last state is the most important part of the design, because without a designated failure state for uncertainty, a model will hallucinate a guess. That destroys the integrity of the audit trail. "Unable to verify" catches technical blockers, like when a required link throws a 500 error or a proxy blocks the agent's access. More importantly, it catches ambiguous project setups. If the guidelines leave room for interpretation, the agent bails out.
Recent work in agentic annotation systems has explored using dedicated QA agents to evaluate collected outputs and aggregations. CrowdAgent (Qin et al., 2025), for example, introduces a multi-agent system for end-to-end annotation process control, including quality and cost management.
LLM QA takes this a step further: rather than stopping at output verification, it closes the feedback loop with the annotator directly . When the agent returns its verdict, it also provides Socratic-style feedback. Instead of pointing directly to the error, it asks the questions that lead the annotator there and draws their attention to the specific element that needs scrutiny and lets them work through the reasoning themselves.
This is deliberate: the goal isn't simply to reject bad work. It’s to make annotators better at their jobs over time. Each feedback loop is a low-cost coaching moment at a scale no human QA operation could match. Under the hood, developers get the full, unvarnished reasoning trace for calibration and debugging.
Benchmarking the reality
To understand how LLM QA performs in practice end-to-end—across reasoning, tool use, and verdict accuracy—we test the system against a controlled, internal benchmark of over 300 real submissions from 20-plus live projects.
We deliberately bias this dataset toward hard, edge-case scenarios: ambiguous instructions, borderline submissions, and situations where human reviewers would typically disagree. Each benchmark item consists of a completed expert task, the relevant quality criteria, and the project guidelines. The agent evaluates against all three and returns a verdict with feedback. Here's what that looks like in practice:
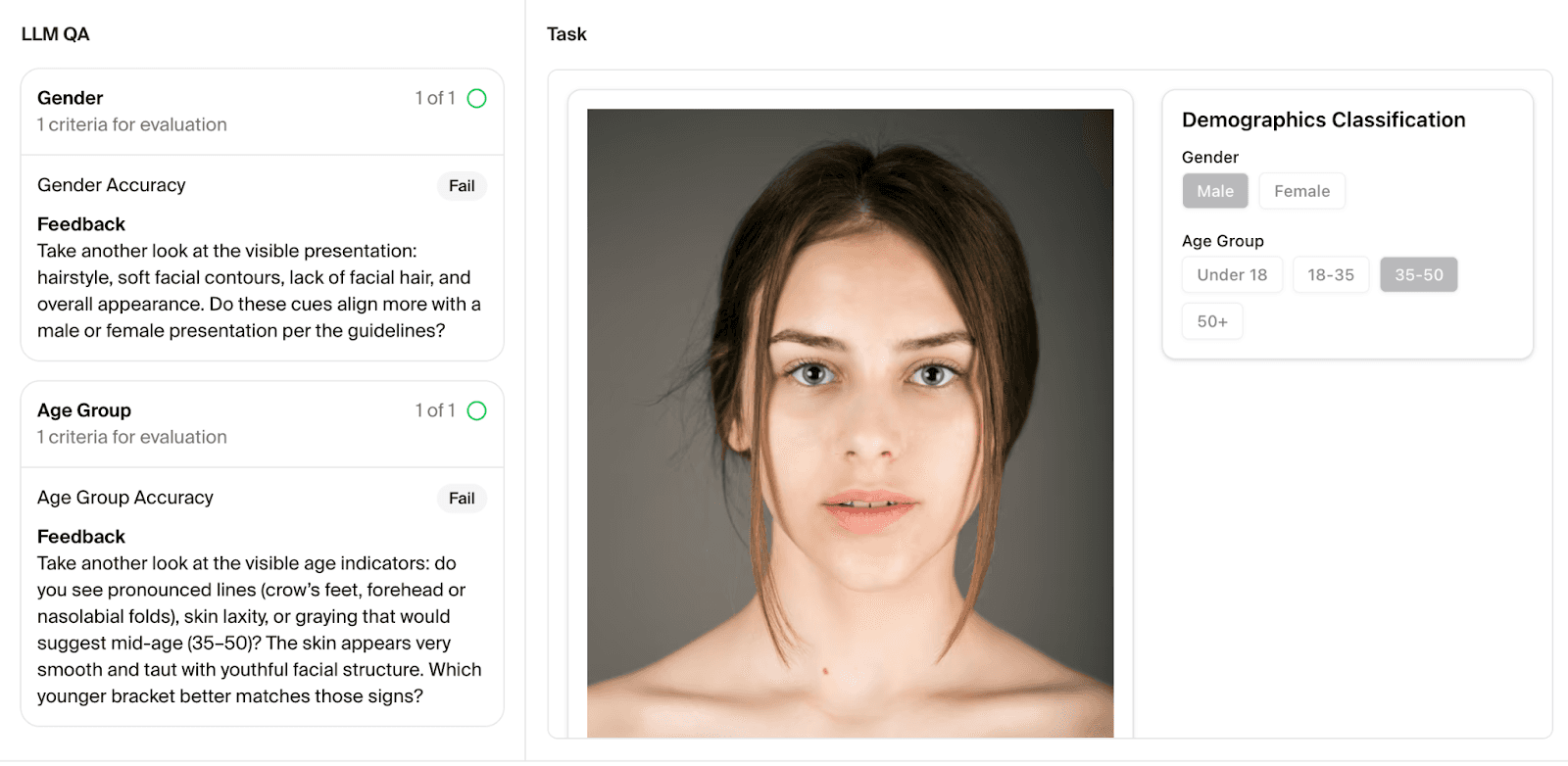
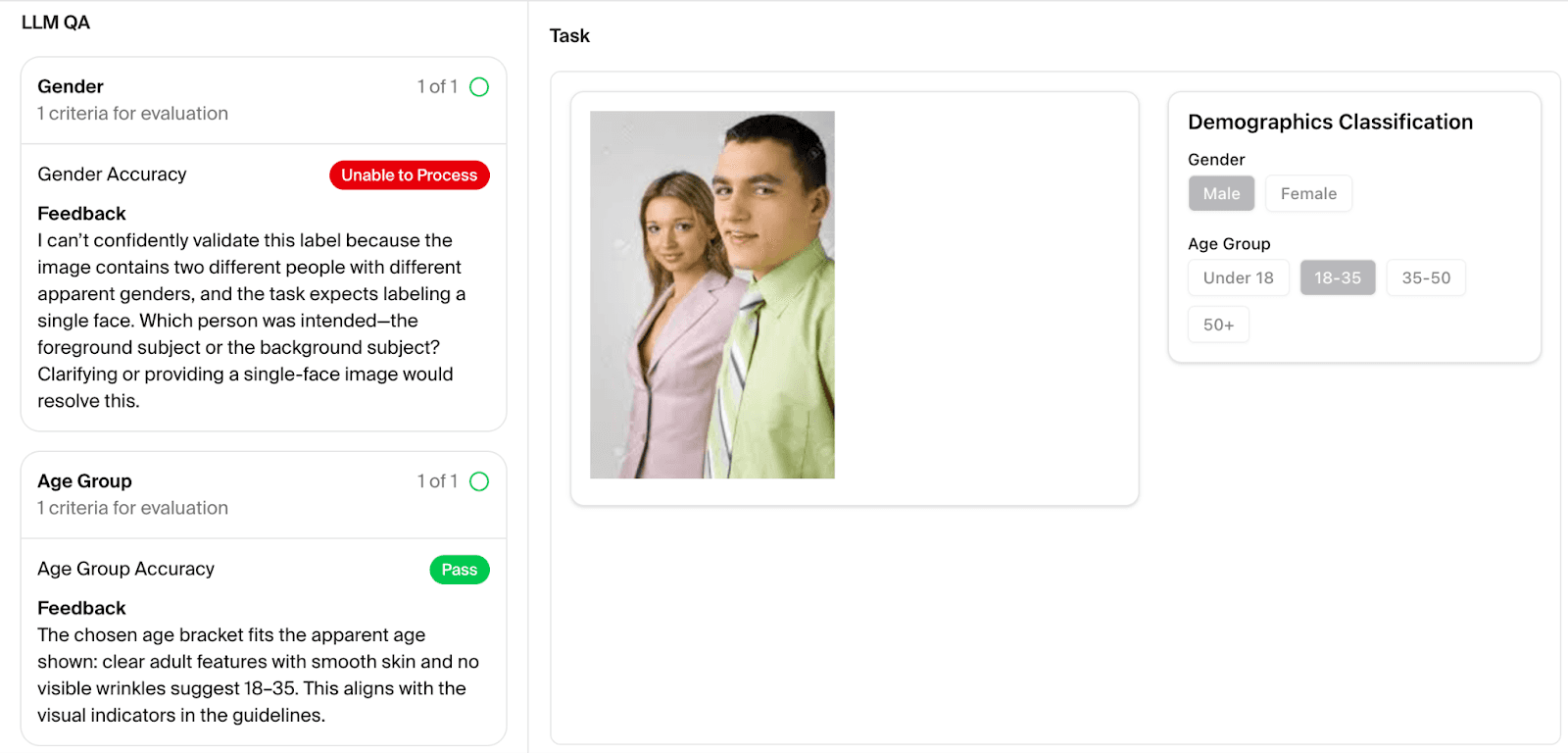
Ground truth for this benchmark was established by Toloka's senior QA reviewers, the most reliable human reference we have access to, rather than production-level annotation, which means these results reflect performance against a high bar, not an average one.
Tasks included in the benchmark come from projects with different needs, from image annotation performed by general annotators to complex reasoning data generated by PhD level STEM experts.
Here is a snapshot of Toloka’s LLM QA current overall performance:

Lower precision on Fail verdicts is an acceptable tradeoff – and often reflects genuine ambiguity or edge cases rather than system error. A false pass is more costly than sending a genuine pass to human review.
Setup as a forcing function
The hardest lesson using LLM QA in our self-service platform is that performance is entirely bounded by task design. The agent derives its entire understanding of the task from your guidelines, which means the setup phase is also a consistency check on your own work. If the terminology in your quality matrix doesn't align with the wording in your instructions, that's a signal your documentation needs tightening, not a limitation of the agent.
The self-check sequence
Because the agent derives everything from your documentation, the best way to deploy LLM QA is to treat the setup phase as a self-check of your own logic. Do not build them simultaneously. Follow this exact sequence:
Tune your quality criteria first. Make sure your matrix is mathematically tight.
Write your project guidelines second. Structure them specifically to support those exact criteria.
If you turn the agent on and immediately get a wall of "Unable to verify" errors, the system is working exactly as intended. It’s telling you your guidelines are ambiguous and need work before you spend the money to scale.
Stop brute-forcing data quality
Relying purely on human operations to scale quality is a losing game. LLM QA changes the math, leaving a legible audit trail while reserving your human experts for true edge cases. Stop hitting the throughput ceiling and start running agentic quality checks on your Toloka pipelines.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.