← Blog
/

Toloka Arena: Independent evaluation of agentic intelligence
Toloka Arena is live. See how your model ranks.
If you're choosing an AI model for your business, you're probably looking at a leaderboard. The model at the top wins. Simple.
Except it's not. We just ran 10 frontier models across seven enterprise domains, from manufacturing to airlines to banking, and the results tell a different story:
The model that wins overall is the third-best model for manufacturing.
The model ranked sixth jumps to second place on manufacturing.
The best model for your company depends entirely on what your company does
Public benchmarks can't show you this because they test generic capabilities on static questions that leak into training data and are quickly memorized. They don't look anything like how AI agents actually operate inside a business, be it following multi-step policies, querying real systems, or making decisions that chain across tools and databases. There’s also an obvious incentive problem when labs grade their own homework.
I built Toloka Arena to fix this. Over the past year, my team and I have built dozens of evaluation environments for frontier labs, each one custom and from scratch. After doing this enough times you start to see the same patterns: the same failure modes and gaps in existing infrastructure, and the same problems that every lab solves independently and badly. At some point the obvious move was to stop rebuilding from zero every time and instead build the infrastructure to do it once, properly, and make the results available to everyone who needs them, from the labs training the models to the enterprises deploying them.
What is Arena?
Toloka Arena is a private benchmark platform where models are evaluated on hidden test cases that are never published. Only the scores come out, which means labs can't train against the data, and the results stay meaningful as models improve.
The test cases themselves are RL Gym-style environments. They’re multi-step, multi-tool workflows that mirror real enterprise operations. Instead of answering a static prompt, the model sits inside a simulated environment with mock systems, a policy to follow, and a user that reacts dynamically to the model's actions. Each decision shapes the next step.
Arena launches with environments spanning different enterprise domains that include:
Manufacturing
Airlines
Logistics
Food services
Banking
Travel, and more
Each one is a self-contained simulated enterprise featuring its own tools, databases, policies, and test cases. The model doesn't know which domain it's in until it starts reading the environment.
We chose this approach for a practical reason, as the frontier labs we work with don't need another coding benchmark. What they need is a way to stress-test agent behavior on the kind of messy, policy-heavy, multi-system tasks that break in production. From manufacturing operations to financial compliance, and customer service with real escalation logic, these are the workflows where the gap between "technically capable" and "reliably correct" matters most, and where current benchmarks have almost nothing to say.
The benchmark evolves as models improve. For example, when a model generation starts clearing the existing tests, we make the tests harder. Toloka Arena is designed to evolve with the frontier.
How evaluation works
Take the manufacturing benchmark, where an agent operates as a support system inside a manufacturing facility. It gets MCP tools that simulate real enterprise software, such as mock SAP, mock MES, inventory databases, and communication channels.
A user LLM plays the role of a manufacturing operator and walks in with requests that sound simple but aren't:
"Check the status of pump three. If the pressure reading is above threshold, send an escalation to my supervisor and open a maintenance ticket."
The agent needs to figure out which system to query, read the data, check it against a policy document with dozens of interacting business rules, decide on the correct action, and execute across multiple tools in the right order.
Grading is deterministic. We hash the final database state the agent leaves behind and compare it to a golden state computed from the correct action sequence. There’s no partial credit or rubric-based judgment calls. Either you arrived at the right end state or you didn't. Building these environments is expensive and slow. Every domain needs its own set of tools, databases, policies, and golden paths. But that's exactly what makes the data valuable, as it's hard to produce, which means it's hard to replicate, and, most importantly, hard to game.
First results: the best model depends on your industry
These results reflect the Arena leaderboard as of April 2026. Model rankings will shift as new releases enter evaluation, the domain catalog grows, and test cases are refreshed. The patterns and methodology hold; the specific scores won't.
We ran 10 frontier models across seven enterprise domains. Here's the overall leaderboard:
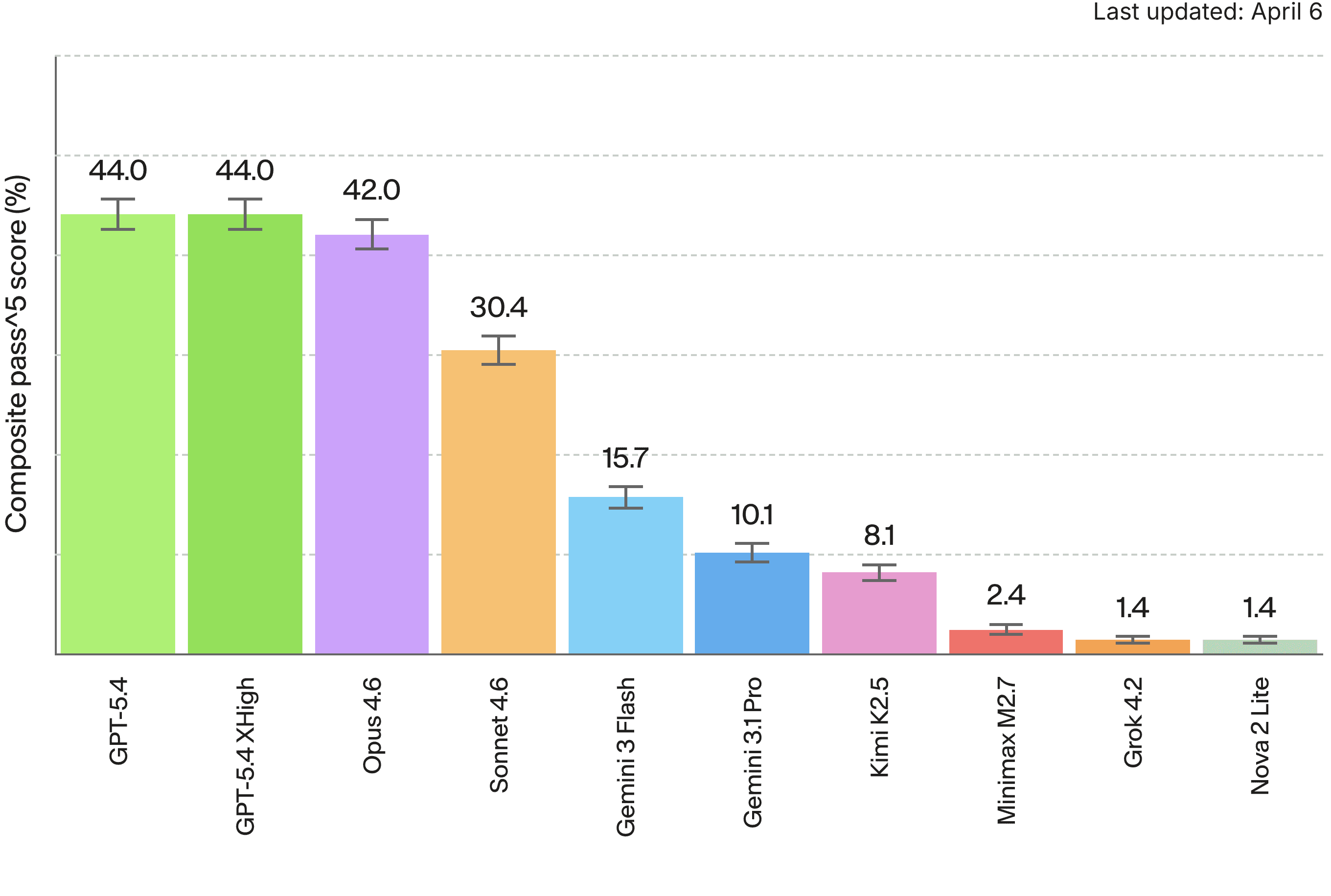
Pass^5 = the fraction of tasks a model solves correctly on five consecutive runs. We use this rather than single-shot accuracy because these are enterprise operations scenarios. If your agent fails even once in five customer interactions, that's a problem.
GPT-5.4 leads overall. But overall is exactly the wrong way to look at this data. Let’s look at what happens when you break it out by domain:
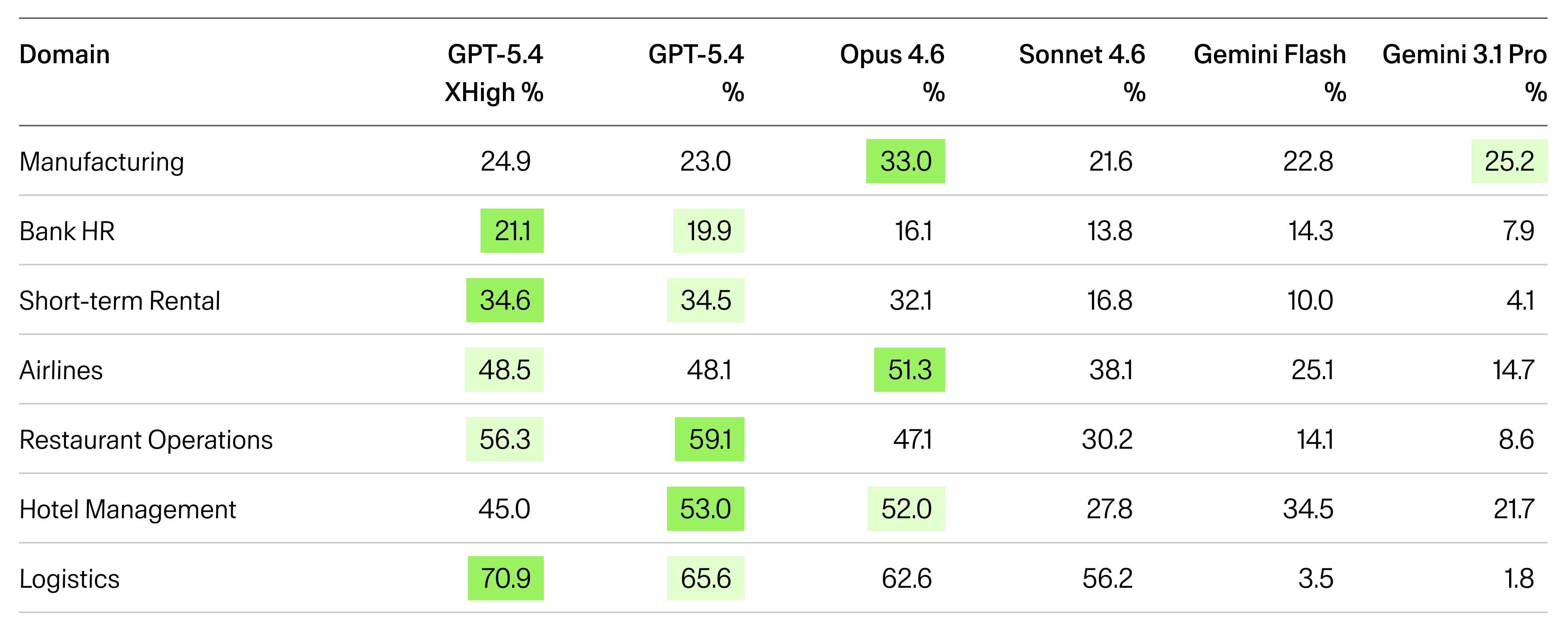
GPT-5.4 is the best model for logistics, but it’s the third-best model for manufacturing. Opus, which sits in third place overall, is actually the best model for manufacturing and airlines. Gemini 3.1 Pro (sixth overall at 10.1%), jumps to second on manufacturing at 25.2%.
If you're deploying an agent for manufacturing operations and you pick GPT-5.4 because it tops the overall leaderboard, you're making the wrong decision. The data says Opus is 10 points better for your use case. That's the difference between a viable deployment and a failed pilot.
This is the core argument for why Arena exists. Single-number leaderboards don't just oversimplify. They actively mislead.
Manufacturing: the great equalizer
Manufacturing is the domain where rankings flip most dramatically. The benchmark covers production order management, lot tracking, material allocation, CAPA handling, and inventory control. It spans 17 tools, 9 databases, 83 test cases, all verified by manufacturing domain experts.
Model | pass^1 | pass^5 |
|---|---|---|
Claude Opus 4.6 | 36.9% | 33.0% |
Gemini 3.1 Pro | 33.7% | 25.2% |
GPT-5.4 | 32.3% | 23.0% |
GPT-5.4 (xhigh) | 31.1% | 24.9% |
Gemini 3.0 Flash | 30.1% | 22.8% |
Claude Sonnet 4.6 | 29.2% | 21.6% |
The top six models sit within an 8-point range on single-shot accuracy. The gap between first and sixth place is smaller than the gap between Opus and GPT on logistics. Manufacturing is where policy complexity overwhelms raw capability. The tasks require interpreting dozens of interacting business rules, where getting the reasoning right matters more than fast tool execution.
Smarter is not always better
The second headline finding is counterintuitive. Across six of seven domains, Gemini 3.0 Flash outperforms Gemini 3.1 Pro. It’s not by a little either, with the final score coming in at 15.7% vs 10.1% overall. On logistics, Flash scores 3.5% while Pro scores 1.8%. On airlines, Flash hits 25.1% vs Pro's 14.7%.
On every major public benchmark, Pro outperforms Flash. Here, the relationship inverts.
Our working hypothesis is that the larger model overthinks. These are scenarios with clear policy rules and defined tool sequences. The reasoning-heavy model explores edge cases that don't exist, second-guesses straightforward instructions, and ends up in a worse state than the smaller model that just followed the rules. Manufacturing is the one exception where Pro (25.2%) beats Flash (22.8%), likely because the policy complexity there actually rewards deeper reasoning.
We see the same pattern with GPT-5.4 and its reasoning-boosted variant. GPT-5.4-xhigh burns dramatically more tokens as of April 2026 (1.1B input vs 867M for standard, plus 74M output vs 19M) and costs 55% more per task. The result is they tie at 44.0% pass^5. On some domains xhigh is slightly better. For others, it’s slightly worse. More compute does not equal more reliability.
This may be the single most important finding from the first Arena run. Public benchmarks optimize for peak capability, which rewards bigger models with more reasoning tokens. Enterprise tool-use tasks optimize for reliable execution, which can actively penalize overthinking. Every practitioner already knows this. Arena quantifies it.
What nobody solves
The difficulty distribution tells a clear story. Across all domains, roughly 3% of tasks are unsolvable by any model. 2% are solved by every model every time. The other 95% is where the signal is.
The impossible tasks share a pattern. They require chaining three or four policy rules in sequence, carrying state across multiple tool calls, and making a judgment that only makes sense if you've correctly interpreted something from several steps earlier. Current models hit a wall around the two-to-three-step mark for conditional policy logic. This is useful information for post-training teams, as it tells you exactly where to focus.
Toloka Forge
Arena runs on Toloka Forge, our evaluation harness. We're open-sourcing it.
I wrote Forge because the alternative was to rebuilding from scratch every single time. Every lab has its own harness, but none of them talk to each other. When we'd get a new client engagement, the first week was always spent wiring up their specific infrastructure before any evaluation could happen. There are decent open-source options for code evaluation or single-domain tool use, but nothing that handles tool use, code, files, and browser-based tasks in one place. If you want to run a model through a diverse benchmark suite today, you're stitching together three or four harnesses and writing glue code for each one.
Forge handles all of those task types under one roof and plugs into standard RL Gym formats. For us internally, it means when a new model ships we can run the full suite and have results in about a day. For clients, it means we write one converter to bridge to their harness instead of rebuilding from scratch. And it makes hybrid benchmarks possible, with tasks that combine coding with browser interaction, or tool use with file management. Nobody else is doing that yet because the infrastructure doesn't exist. Those hybrid evals are in development and will start showing up in Arena later this year.
We open-sourced Forge because the eval space needs shared infrastructure, not more walled gardens. If researchers build environments on Forge, those environments plug into everything else in the ecosystem. That's good for the field and good for us.
Who is Arena for?
Enterprises deploying AI agents
As the leaderboard shows, the right model depends on industry, policy complexity, and tolerance for failure. Arena provides the domain-level data to make that decision rather than inferring it from an aggregate score.
Post-training teams at frontier labs
Arena provides eval signal broken out by domain, showing exactly which enterprise workflows expose a model's weaknesses. The domain catalog goes further: the environments that broke a model are available as training data, complete with golden trajectories. Fail on a task, use that failure to fix the model. Evaluation and training are two sides of the same problem.
What's coming next
The environments at launch are all tool-use, which is where our automated generation pipeline is most mature. But Forge already supports coding, browser-based, and long-horizon task types, and the next wave of environments will include those, along with hybrid benchmarks that blend multiple capability types in a single evaluation. A task that combines coding with browser interaction, or tool use with file management, is far closer to how agents actually operate. Nobody is benchmarking those combinations right now because the infrastructure doesn't exist. It will.
We're building eval-as-a-service: bring your model checkpoint, run it against the full Arena suite, and get your scores back. There’s no need to buy the data. If you want to go deeper, we'll offer detailed human-annotated reports that identify failure patterns and explain why a model breaks, not just where. Both are coming later this year.
We're also building a bounty system where anyone can submit a task. If it breaks a frontier model, we buy it. The test case enters the catalog, never gets published, and makes the benchmark harder. Like all Arena test cases, bounty submissions remain private to the platform. The catalog compounds over time instead of getting stale.
Explore the leaderboard
Arena is a team effort. Elizaveta Yoshida leads program management and operations. Leonid Kozhinov, Anton Piskunov, Roman Arkhipov, Valentin Shishkov, Mikhail Ostanin, and Daniil Galiev built the environments, data pipelines, and client delivery infrastructure that make the benchmark run. The broader Toloka team made the rest possible.
Renaud de la Gueronniere is the creator and technical architect of Toloka Arena. Previously at McKinsey/QuantumBlack, he has built 60+ evaluation environments for frontier AI labs. He presents Arena at ICLR 2026 in Rio de Janeiro.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.