
Audio annotation
Collect, classify, transcribe or annotate audio data on our industry-leading data labeling platform.
Use cases
- Voice assistants
- Text-to-speech
- Speech recognition
- Natural utterance collection
- Speech emotion recognition
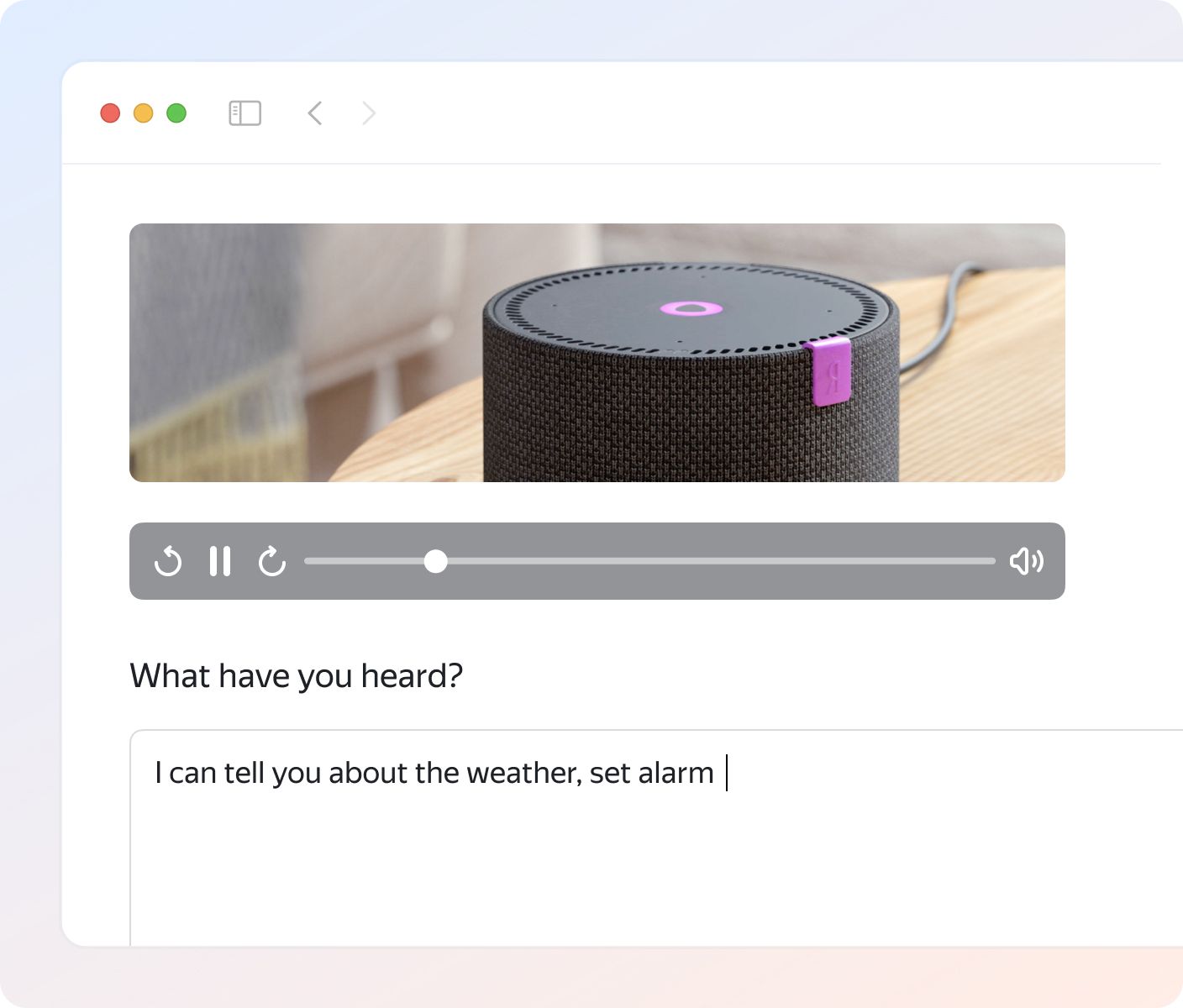
Label audio with flexible tools
Use our data labeling tools and templates to create high quality training data for audio based ML models. Generate or annotate audio files for any type of project.
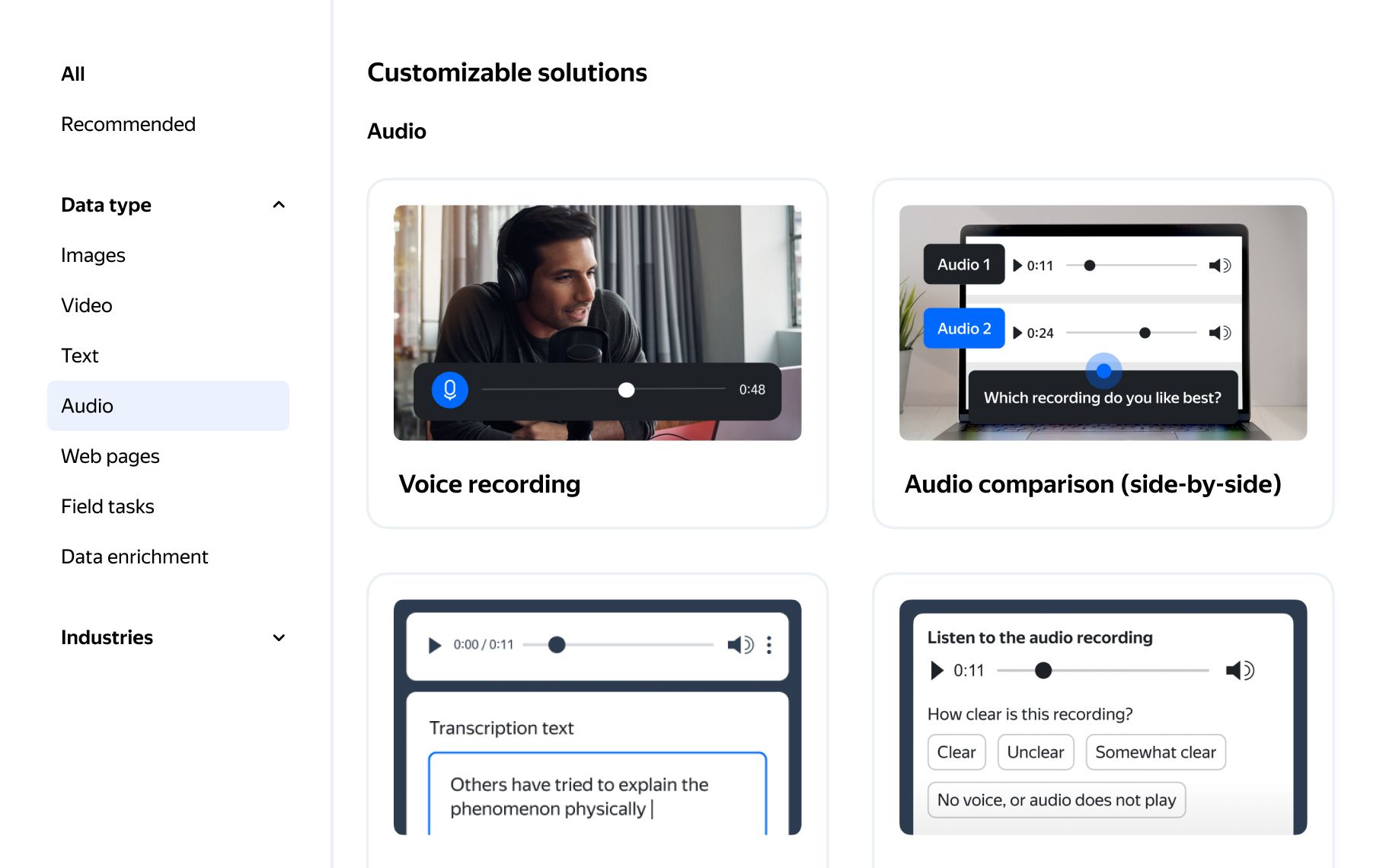
How audio annotation works in Toloka
Hand your data labeling tasks over to our global crowd and get scalable human
insights for your audio data in over 40 languages.
- Audio labeling
- 1
Pick a project preset for audio data that matches your use case. Or start from scratch and design your own template.
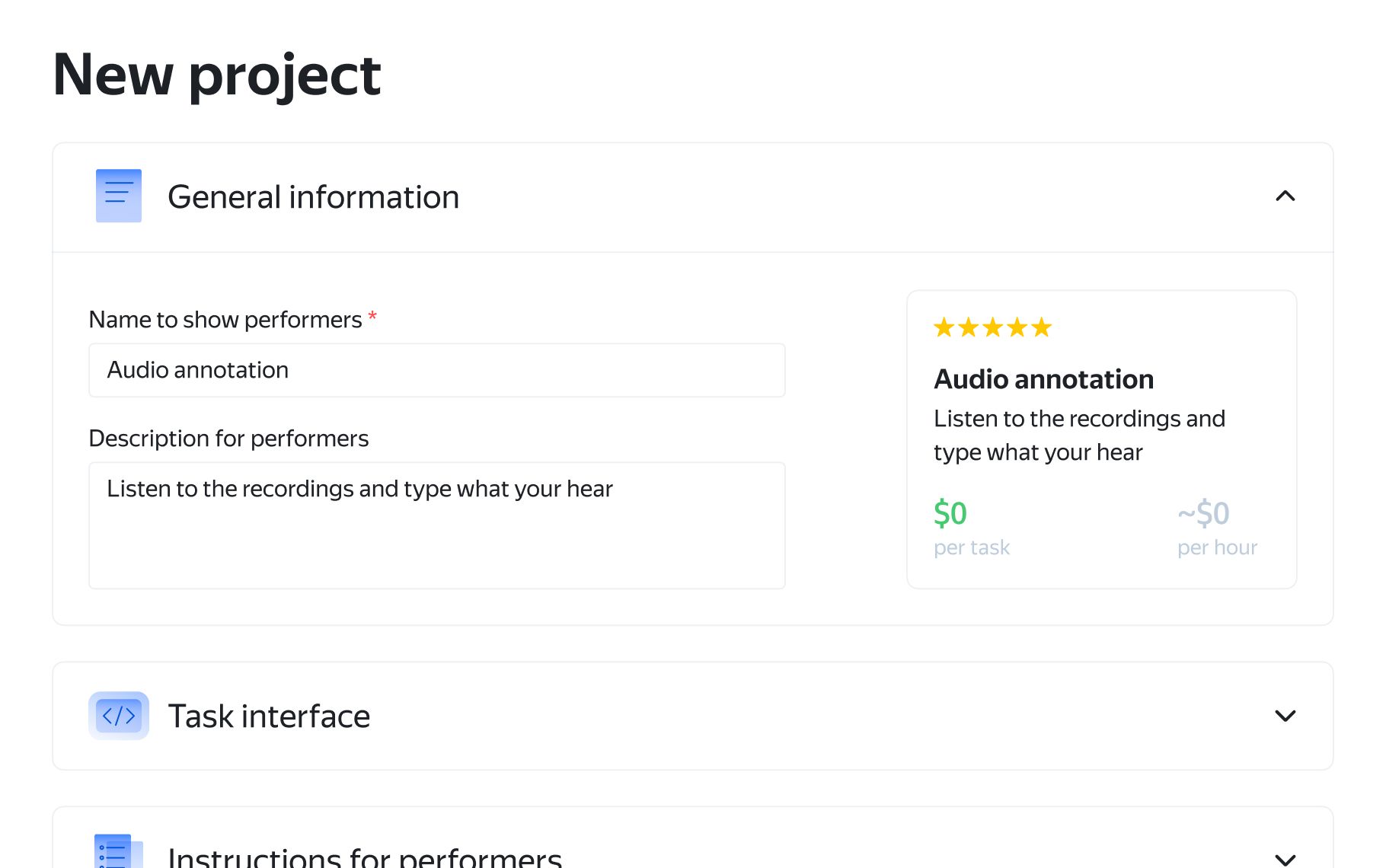
- 1
Choose the audience, quality control methods, and other options.
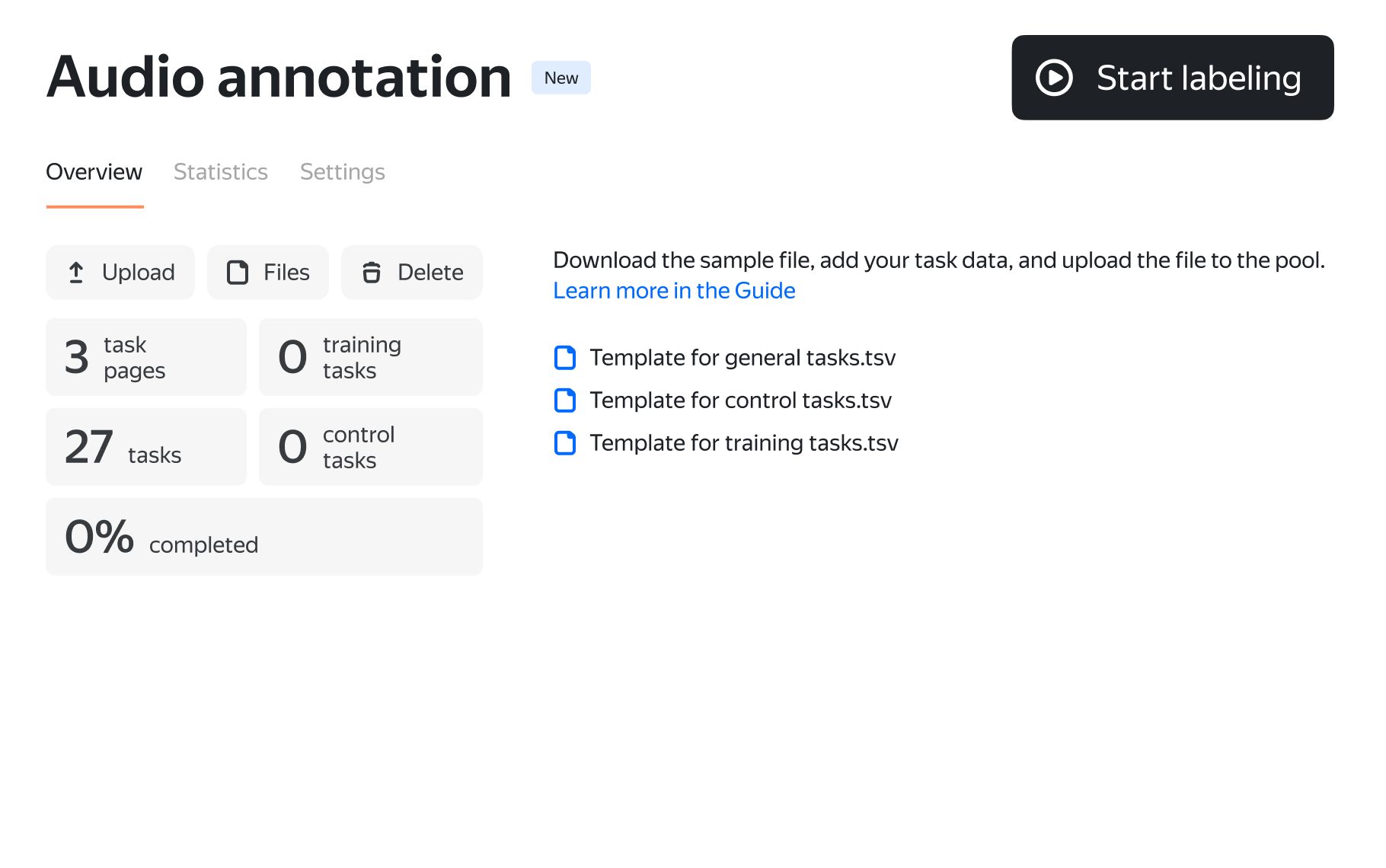
- 1
Upload the first batch of raw data for labeling. Launch your pool of tasks and monitor progress as tasks are completed.
- 1
Download the file with results and get ground truth data.
- 1
Tweak settings to improve results for the next batch of audio data.
Why choose Toloka for video labeling
Our platform is purpose-built to meet the most challenging data labeling demands.
- Fast scalability
- Short turnaround time
- Wide range of quality
control tools - Real-time data labeling
- API and Python SDK
for easy integrations - Clear pricing
Find out more
State-of-the-art technologies
Our technologies have grown out of scientific research and 10 years of practical experience to make optimal quality attainable in labeled data.
Learn moreThe largest global crowd coverage
Our diverse global crowd spans every time zone for non-stop labeling and instant scaling, with support for 40+ languages.
Learn moreRobust infrastructure
Fault-tolerant high-load system for rapid knowledge enrichment that prioritizes data security and privacy.
Learn moreFull API and Python SDK
ML teams can integrate an on-demand workforce directly into their processes to build scalable and fully automated data pipelines.
Learn more
Automated solutions for speech recognition
Skip model development — start off with our pre-trained autoML model for speech recognition and automatically tune it as needed using your data streams. Capture the text from audio content in 13 languages (English, German, French, Italian, Spanish, Portugese, Finnish, Swedish, Dutch, Polish, Russian, Kazakh and Turkish), with automatic language detection. Our model recognizes speech on any topic, including short and long utterances, names, addresses, dates, and numbers.
Learn moreGet data labeling
on your terms
- Choose from self-service and bespoke
options to meet your needs - Connect to our global crowd or your own in-house
workforce on the Toloka data labeling platform
Ready to learn more?
to your business needs.