← Blog
/

Automated data annotation: The foundation of reliable AI models
High-quality human expert data. Now accessible for all on Toloka Platform.
Hybrid data generation blends scale and quality for better training
Automated data annotation: The foundation of reliable AI models
Most AI projects do not collapse in the dramatic fashion one might expect. They erode quietly, over time. This pattern shows up again and again, and for reasons that are not especially surprising.
Data annotation, often referred to as data labeling, may be the unsung backbone of AI, yet it is also one of the first processes to take strain as systems begin to scale. It can no longer remain a purely manual effort. Automation — supported by a hybrid human approach — has become unavoidable.
To understand why, it helps to look at how we arrived here in the first place.
When a model is trained, generally speaking, the results look promising. A pilot version works well enough to run past clients and justify further investment. As the system moves into the realm of real users, real environments, and real variability, small issues begin to surface. Predictions feel inconsistent. Edge cases behave strangely. The model is confident when it should hesitate and hesitant when it should be confident.
When development teams start to investigate what went wrong, the explanation is rarely exotic. The machine learning algorithms themselves are not the problem. It is not a missing layer or an overlooked hyperparameter. Almost always, the issue can be traced back to the training data — and more specifically, to how teams label data during annotation.
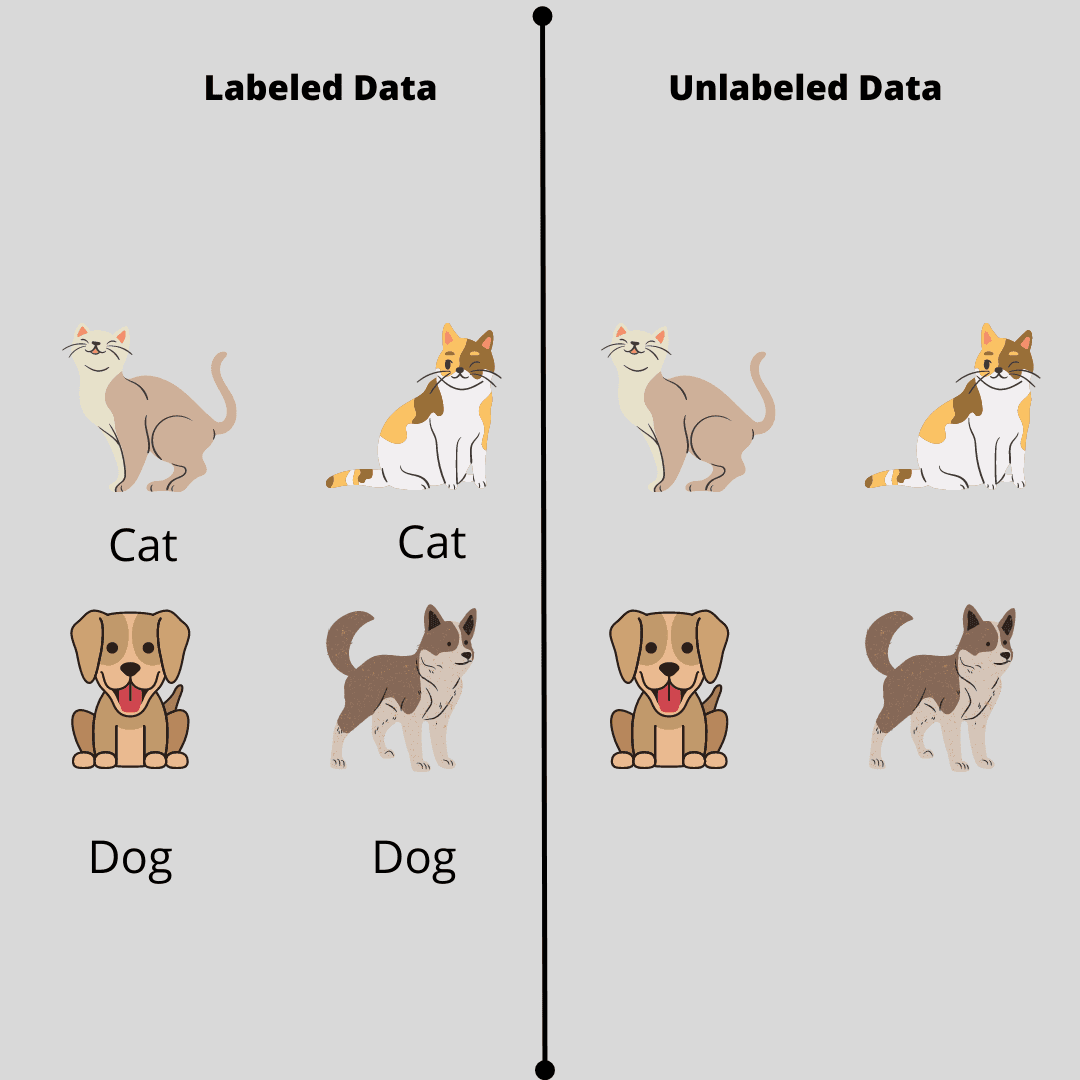
In practice, data annotation rarely receives sustained attention. In many teams, including those led by data scientists, the labeling process is treated as a one-time setup task rather than a system that must remain consistent, observable, and correctable as data volumes grow.
It sits upstream of model training, evaluation, and deployment, which means its effects are often invisible until much later. By the time performance issues surface, annotation decisions may be weeks or months old. Those decisions are already embedded in the dataset and, by extension, in the model itself. At scale, revisiting or undoing them becomes slow, costly, and operationally disruptive.
This upstream positioning is also why early tool choices matter more than teams often realize, particularly when teams are working across multiple data types.
Teams evaluating the best data annotation tool are therefore not really comparing interfaces or feature lists, but choosing the foundation that will shape data consistency, governance, and model behavior long after the first training run.
Decisions made when selecting image annotation tools, a video annotation tool, or a text annotation tool, for example, influence not only how efficiently labels are produced, but how consistently objects, language, and meaning are defined, reviewed, and corrected over time. When those same annotation tools lack structure or visibility, small annotation issues can quietly propagate through entire datasets long before anyone notices.
This is why automated data annotation has moved from a “nice to have” capability into a core requirement for teams trying to build reliable AI systems. If the conversation is about scaling the next generation of LLMs, annotation automation inevitably becomes part of the discussion.
At scale, annotation errors don’t average out — they compound.
Automation is what turns correction into a system instead of a reaction.
But before jumping straight into workflows, platforms, label data, and annotation tools, it’s worth pausing for a moment to reflect on why data annotation itself remains non-negotiable — and why purely manual approaches start to break the moment scale enters the equation.
What makes data annotation the backbone of AI?
Machine learning models do not learn directly from the world. They are not observing reality as it unfolds, nor are they independently interpreting information from the internet. What they learn from instead are representations of the world — simplified, structured versions of reality that have already been filtered and defined. Data annotation is what creates those representations, turning atomic data into something a machine learning system can actually digest and learn from.
An image on its own is just a grid of pixels. A sentence is just text. An audio file is just sound. Data annotation adds meaning. It tells the model what matters, what does not, and how to interpret what it sees.
This is true across AI disciplines, even though the data itself may look very different from one domain to the next. These differences in data types (from images and text to audio and video) shape not only how annotation is performed, but how meaning is extracted and learned by models.
This distinction is especially pronounced in computer vision systems, where spatial structure, object boundaries, and visual context must be made explicit for models to learn effectively.
In computer vision production systems, image annotation defines how teams label images to identify objects, boundaries, and relationships within a scene. Bounding boxes, segmentation masks, and labels tell the model what constitutes an object, where it begins and ends, and how it relates to its surroundings.
Bounding boxes, often referred to as box annotation, are often the first annotation primitive introduced because they strike a balance between speed and spatial precision, especially during early model iterations. Without this structure, a model has no way of distinguishing between foreground and background, signal and noise.
In natural language processing, text annotation serves a similar role. Labels clarify intent, sentiment, entities, and structure, turning free-form language into something a model can reason about. The same sentence can mean very different things depending on context, and data annotation is how that context is made explicit during training.
In speech systems, audio transcription connects sound to language. Raw waveforms are mapped to words, speakers, or emotions, allowing models to learn not just what is being said, but how it is being said. Without accurate annotation, speech models struggle with ambiguity and variability across accents, environments, and speakers.
In robotics and autonomous systems, the challenge becomes even more concrete. Sensor data and point cloud data define spatial understanding. Data annotation determines what is considered an obstacle, a navigable surface, or a moving object. These decisions directly influence how systems perceive and interact with the physical world.
In every case, annotated data becomes the reference point for learning. Models do not question that reference. If it is wrong, inconsistent, or incomplete, the model absorbs those flaws as if they were truth. Over time, those small inaccuracies compound, showing up later as brittle behavior, unexpected failures, and a growing gap between how the system performs in controlled settings and how it behaves in the real world.
Training data quality and model behavior are inseparable
There is a tendency to think of data annotation errors as “noise.” In practice, annotation errors are instructions.
Machine learning models do not know which labels are correct and which are sloppy. They treat them all as ground truth. If a dataset contains inconsistencies, the model learns inconsistency. If edge cases are mislabeled, the model misbehaves on edge cases. If ambiguity is handled differently by different annotators, the model internalizes that ambiguity.
This is why training data quality is such a strong determinant of downstream performance. It is also why data annotation problems are so difficult to fix later. Once a model has learned from flawed data, correcting its behavior often requires rebuilding the dataset, not just retraining the model.
Where manual data annotation starts to break
Manual annotation is not the villain here. Human judgment is essential, especially for nuanced tasks. The problem is scale.
Manual workflows work reasonably well when datasets are small, teams are tight-knit, and feedback loops are short. As soon as projects grow beyond that, cracks appear.
Instructions drift. Review processes lag. Different annotators interpret the same task differently. By the time problems are discovered, thousands or millions of labels may already be affected.
The instinctive response is to add more reviewers or tighten guidelines. That helps, briefly. But without structural support, manual annotation eventually becomes fragile.
Why scale changes everything
At scale, data annotation stops being an individual activity and becomes a system. At that point, the labeling process must operate reliably across contributors, data types, and time — or small inconsistencies will propagate faster than teams can detect or correct them.
That system must operate consistently across growing volumes and increasingly diverse data types, each with its own annotation logic, failure modes, and quality risks. As a result, the questions teams ask begin to change. Data annotation tools are no longer optional utilities, but foundational components that determine whether annotation can function as a reliable system or not.
So, instead of “Is this label correct?”, the question becomes “Are we labeling consistently across this entire dataset?” Instead of “Did this annotator make a mistake?” the question becomes: “Is our process surfacing mistakes early enough?”
These are not questions that humans alone can answer efficiently. They require automation.
Automation is about control, not speed
It is tempting to frame automated annotation as a productivity tool. In reality, its primary value is control.
Automation introduces structure into the annotation process. It defines how tasks are created, how work is distributed, how outputs are validated, and how quality is measured. This structure allows teams to reason about annotation as a process, not just a collection of individual labeling jobs.
With automation in place, quality control shifts from being reactive to proactive. Errors can be detected while work is ongoing, not after datasets are finalized. Patterns of disagreement can be identified early. Instructions can be refined before inconsistencies spread.
Automated annotation as infrastructure
In mature AI organizations, annotation is no longer treated as a temporary phase. It is treated as infrastructure. At that point, a data annotation platform stops being a place where labeling happens and becomes the system that enforces consistency, governance, and continuity across the lifecycle of training data for computer vision and other AI systems.
That infrastructure supports:
continuous data ingestion,
repeated rounds of annotation,
model retraining,
and long-term dataset maintenance.
Automated data annotation platforms make this possible by integrating workflow orchestration, validation logic, reporting, and data management into a single system. Annotation becomes traceable, auditable, and repeatable.
This matters because AI systems do not stand still. Data changes. Models evolve. Annotation must keep pace.
Hybrid human and machine annotation systems
The most effective annotation workflows today are hybrid by design.
In practice, this balance is only achievable when data annotation tools are designed to coordinate human judgment and automated enforcement within a single, coherent workflow, particularly in computer vision workflows where volume and visual complexity collide.
Humans contribute interpretation, context, and judgment. Machines contribute consistency, enforcement, and scale. Each does what it is best at.
In a well-designed hybrid system, automation handles routine checks and structural validation. Humans focus on complex annotation tasks where nuance matters. Review effort is targeted rather than blanket.
This approach allows teams to scale annotation without flattening human expertise or introducing unnecessary friction.
Why humans are still central to annotation
Despite advances in automation, there are limits to what machines can label reliably. Language is contextual. Visual scenes can be ambiguous. Cultural and domain-specific knowledge matters.
Tasks such as sentiment analysis, content moderation, and nuanced classification still depend on human understanding. In computer vision, ambiguous object detection, overlapping instances, and edge cases often require expert judgment.
Automation does not replace this expertise. It supports it by ensuring that decisions are applied consistently and reviewed systematically.
How automation improves the annotator experience
Automation is not only about outputs. It affects the people doing the work. As expectations increase, data annotation tools are judged not only by task coverage, but by how well they support scale, quality control, long-term reuse of annotated data, and an intuitive user interface.
Clear task definitions, immediate feedback, and structured validation reduce guesswork. A user-friendly interface helps annotators focus on accuracy rather than tooling. Automated checks prevent simple mistakes from slipping through.
When automation is done well, annotators spend less time correcting errors and more time doing meaningful work.
What you expect modern data annotation tools to 'handle'
Today’s data annotation tools are expected to support a wide range of annotation tasks and data types.
This includes image annotation and image labeling alongside video annotation for computer vision, as well as text annotation and audio transcription. Within those categories, teams may need to support image labeling, drawing boundary boxes for object detection, semantic segmentation, instance segmentation, polygon annotations, and object tracking across video frames.
Annotation platforms must also handle data management, including importing source data, organizing annotated data, and exporting datasets in the correct data format for model training.
Why annotation tools differ more than they appear
Many annotation tools look similar at first glance. The differences emerge under pressure.
This becomes immediately apparent in large-scale computer vision projects, where annotation errors propagate visually and compound across large datasets.
Some tools are optimized for a single modality, such as images or text. Others emphasize speed but provide limited quality oversight. Some offer flexibility but require teams to build their own governance processes.
At scale, these differences matter. Fragmented tooling increases operational overhead. Inconsistent workflows introduce risk. Limited visibility makes quality issues harder to diagnose. This is why evaluating data annotation tools requires looking beyond surface features and focusing on how well they support consistency, governance, and long-term dataset evolution.
Choosing the right data annotation tool is therefore less about individual features and more about how those features work together.
Multimodal annotation is now a baseline requirement
Few real-world AI systems rely on a single data type. Modern models often combine images, video data, text, audio, and sensor inputs.
Annotation platforms must support this reality. Running image and video annotation in one system and text annotation in another creates unnecessary complexity. Unified workflows reduce friction and improve consistency across datasets.
Image annotation in computer vision applications and production systems
Image annotation remains central to many computer vision applications. Common tasks include image classification, object detection, and image segmentation.
Bounding boxes are widely used, particularly when speed matters and datasets are large. In many production workflows, bounding boxes serve as the baseline representation for object detection before more granular techniques are introduced. While more precise tasks rely on semantic segmentation, instance segmentation, and polygon annotations to capture object boundaries accurately, bounding boxes often remain part of the pipeline for validation, bootstrapping, or hybrid labeling strategies.
Consistency across large image datasets is one of the hardest problems to solve, and one of the easiest to underestimate.
Video annotation and temporal complexity
Video annotation adds time as a variable. Object tracking requires labels to remain coherent across frames, not just within a single image.
Automated validation helps ensure continuity and detect drift, especially in long sequences where manual review becomes impractical.
Text annotation and language ambiguity
Text annotation underpins natural language processing tasks such as sentiment analysis and entity recognition. Language is subjective, and interpretation varies across annotators.
Structured workflows and automated checks help surface disagreement early and prevent subtle inconsistencies from spreading.
Sensor data and spatial understanding
Sensor data, including LiDAR data and point cloud data, introduces spatial complexity. Annotating this data supports 3D object detection and spatial reasoning in robotics and autonomous systems.
These workflows demand precision and benefit significantly from automation.
The annotation process from raw data to training-ready datasets
A robust annotation process begins with data ingestion and task definition. Labeling is followed by continuous validation and review. Annotated data is exported and fed directly into model training pipelines.
When automation is embedded throughout this process, annotation becomes a closed loop. Feedback informs instruction updates. Quality trends guide workflow adjustments. Data improves over time.
Data management and integration
Large annotation projects depend on effective data management. Integration with cloud storage allows teams to manage large datasets, track versions, and ensure that the correct data feeds into model training.
As datasets grow, cloud storage becomes the backbone for versioning annotated data, coordinating distributed annotation workflows, and maintaining a reliable link between raw inputs, labeled outputs, and trained models.
This is most often delivered through an online annotation tool that connects distributed annotators, centralized data storage, and machine learning pipelines in real time. Automation ensures traceability and reduces operational risk.
Quality assurance as a system, not a checkpoint
Quality assurance works best when it is continuous. Redundancy, consensus scoring, automated rules, and targeted human review each play a role. Embedding quality control throughout the workflow improves reliability without slowing throughput.
Workflow customization and governance
Different projects require different workflows. Annotation platforms that allow customization enable teams to adapt processes as requirements evolve.
Governance matters as projects grow, especially when multiple stakeholders and teams are involved.
Visibility through reporting
Reporting provides insight into throughput, disagreement rates, and instruction clarity.
These signals help teams improve annotation quality and efficiency over time. Without visibility, problems remain hidden until they affect model performance.
Final thoughts: Something to remember for the future
Data annotation has always mattered. What has changed is the scale.
As datasets grow and AI systems become more complex, manual annotation alone is no longer sufficient. Automated data annotation allows human judgment to operate reliably at scale.
For organizations building production AI systems, this is not an optional upgrade. It is part of the foundation.
Scale Your Annotation Without Sacrificing Quality
Manual annotation breaks at scale — but pure automation misses nuance. The Toloka Platform delivers the hybrid approach production AI demands: expert human annotators across 90+ domains combined with automated quality control workflows that catch inconsistencies before they compound. From bounding boxes to semantic segmentation, our AI Assistant streamlines annotation setup while the Toloka Quality Loop validates every label against your standards. Whether you're building computer vision models or training on vast datasets, get the accurate, consistent annotations that improve model performance. Start annotating at scale →
Frequently Asked Questions
What is the difference between automated annotation and manual labeling?
Manual labeling relies entirely on human annotators to review and tag each data point individually, which works for small datasets but becomes slow and inconsistent at scale. Automated annotation uses machine learning algorithms, pre-trained models, and rule-based systems to generate labels automatically, with humans reviewing edge cases. The key advantage of auto annotation is maintaining consistency across vast datasets while reducing the time and in-house engineering resources required. Most production systems use a hybrid approach where automated processes handle routine labeling objects and manual methods address complex or ambiguous cases.
How does automated data annotation improve computer vision models?
Computer vision models require massive volumes of accurately labeled visual data to learn how to detect objects, recognize objects in different contexts, and perform tasks like image classification and semantic segmentation. Automated annotation tools accelerate the data annotation process by pre-labeling images with bounding boxes and segmentation masks, which human reviewers then verify. This speeds up training dataset creation while ensuring accurate data annotation. For specialized applications like medical image annotation and autonomous driving, automation helps maintain the labeling consistency that directly impacts model performance and generalization.
Why do automated annotation tools still require human-in-the-loop workflows?
Even the most advanced automated systems struggle with ambiguous input data, nuanced context, and edge cases that require judgment. Human-in-the-loop workflows combine the speed of automation with the interpretive accuracy of human annotators. This is critical for tasks like sentiment analysis, entity recognition, and classifying objects in complex scenes where context matters. Automated tools handle structured data and routine annotation tasks efficiently, while humans focus on reviewing uncertain predictions, correcting errors, and refining guidelines. This approach prevents poor quality data from propagating through training datasets and improves model generalization over time.
What features should teams prioritize when selecting automated data annotation tools?
Teams should evaluate automated annotation tools based on support for multiple data types including visual data, audio data, and text. Look for customizable quality control workflows that enable consensus scoring, automated validation rules, and targeted review. Active learning capabilities help prioritize uncertain samples for human review, reducing annotation effort while improving high-quality data output. Integration with cloud storage and existing machine learning pipelines ensures annotated data flows directly into model training. Finally, a user-friendly interface reduces annotator friction and supports the learning process for new team members scaling annotation operations.
How does automation help teams handle large volumes of annotation work?
When datasets grow to millions of samples, manually annotating every item becomes impossible without sacrificing consistency or timeline. An automated system applies labeling rules uniformly across the entire dataset, catching errors that human reviewers would miss in large datasets. Automation also enables continuous annotation workflows where new data is processed incrementally rather than in batches. For computer vision projects, automatic annotation can pre-label large volumes of images overnight, leaving reviewers to focus on corrections rather than starting from scratch. This transforms annotation from a bottleneck into a scalable, supervised learning pipeline that keeps pace with model development.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.