← Blog
/

Data annotation company: How Toloka delivers high-quality data for modern AI applications
High-quality human expert data. Now accessible for all on Toloka Platform.
Hybrid data generation blends scale and quality for better training
Data Annotation Company: How Toloka Delivers High-Quality Data for Modern AI Applications
The rate at which Artificial Intelligence (AI) is evolving and penetrating various industries is quite impressive. Every other day, there is an innovation making the news. All these are the workings of a bigger system made up of different players working together. Data annotation companies are no doubt an essential part of this system.
For AI systems to work perfectly and autonomously, there is an essential requirement of training data, which calls for high-quality data annotation. Data being the front and center of AI systems, its preparation is key to the model training process of AI development. Without accurate data labeling, even the most advanced models struggle to learn, generalize, or operate reliably in real-world environments.
This is where a data annotation company comes in. Not everyone can prepare the data used to train AI models, and that is why annotation companies like Toloka exist. These companies play a foundational role in modern machine learning by transforming raw, unstructured information into structured and labeled datasets. These datasets become the training fuel that allows computer systems to “see, hear, read, and reason.”
As AI systems grow more complex, organizations increasingly depend on specialized annotation services rather than handling annotation internally. This is because annotation companies have the right resource reach and workforce to handle annotation (labeling) fast and efficiently.
It is at the center of this ecosystem that Toloka operates. As a top-rated company, it offers a scalable platform, a global workforce, and managed services designed to support complex annotation projects across various industries. Its approach combines human expertise with technology-driven workflows. In doing so, Toloka ensures accuracy, scalability, and ethical responsibility throughout the data labeling process.
Why Data Annotation Companies Matter in AI Development
We’ve seen that modern machine learning models (ml models) depend on labeled data for supervised learning. Data labeling provides the essential context by teaching systems to recognize patterns, classify objects, and understand language. As such, precise data labeling directly impacts model performance across the various fields of AI, like computer vision and natural language processing.
The Cost and Limitations of In-House Data Annotation
One would wonder, why not just annotate your data in-house and train the model? This is actually possible, but not sustainable in the long run. As projects scale, datasets grow in size and complexity, thus managing annotation internally becomes costly and inefficient.
A specialized data labeling company, therefore, brings established workflows, trained teams, and built-in quality control, which allows organizations to scale faster without sacrificing accuracy. Outsourcing data annotation, therefore, can reduce project completion time by up to 50%, making it a smart choice for ambitious AI projects.
Toloka’s Human-in-the-Loop Data Annotation Model
A defining feature of Toloka’s approach, as a company providing labeling services, is its strong human-in-the-loop foundation. This ensures ethical, bias-aware data labeling tailored to evolving project needs. Toloka's platform supports annotation for building AI applications by combining human and AI capabilities to build and improve AI implementations across diverse use cases. Simply put, professional annotation companies like Toloka use diverse teams to reduce human bias in datasets and promote ethical outcomes in AI models.
Key Criteria for Selecting a Data Annotation Company
Honestly speaking, choosing the right annotation provider is challenging due to the variety of features and services offered. However, it is advisable to prioritize experience, quality control, security measures, technology, and cost structure when selecting a data labeling company. Most of the other considerations will, in one way or another, revolve around these five factors.
Compliance
For sensitive projects, it’s a standard practice to verify security certifications such as ISO 27001, SOC 2 Type II, GDPR, and HIPAA. Besides these standards, it is quite beneficial to choose a company that can integrate with your existing workflows and tools.
Experience
In order to ascertain experience, clients should always request a Proof of Concept (PoC) or paid pilot project before a long-term contract. A pilot project can help assess the capabilities of an annotation company before committing to a larger contract. At the same time, transparency in pricing and quality metrics is a key consideration when selecting an annotation partner.
Technology, Scalability, and Data Requirements
On the technical side, key considerations when selecting an annotation provider include domain expertise and the types of data they handle. When you understand the type of data that your project requires, you’ll find it quite easy to choose an annotation partner whose labeling approaches integrate seamlessly with your existing machine learning pipelines. In short, evaluating your technology stack, scalability prospects, and security requirements comes first before settling on the partner to work with.
What Is Toloka as a Data Annotation Company?
Among the top global brands that have gained footing in the data labeling, Toloka is certainly at the top of the list. Toloka has made a name for itself as a premier data labeling company delivering scalable, high-quality data labeling services for building and refining AI models.
Its advanced platform supports everything from self-service task design to fully managed service options, which makes it ideal for AI teams of all sizes. With no minimums and no long-term contracts, Toloka’s self-service platform allows users to start annotation projects in minutes, while managed services handle end-to-end delivery upon request.
What Makes Toloka Stand Out?
We’ve already mentioned that at its core, Toloka emphasizes human-in-the-loop processes, where expert judgment validates and enhances outputs. This foundation supports advanced abilities and techniques like active learning, RLHF (reinforcement learning from human feedback), and model evaluation, which are critical for today's generative AI and multimodal systems.
The Hybrid Platform
Toloka’s platform takes a hybrid approach when it comes to data annotation. With top-notch precision, it supports data labeling projects across various AI application areas like autonomous driving, conversational agents, and coding copilots, just to mention a few.
Toloka also boasts one of the world's largest multilingual crowds, spanning 235+ dialects and specializing in speech, text, and conversational AI. To the rapidly growing niche of global annotators, Toloka offers jobs that can be completed in hours, with competitive pay per hour based on expertise and task complexity.
Types of Data Toloka Supports in Annotation Services
Flexibility of data formats is a defining factor for a good annotation company. Toloka knows this better than any other company out there and offers a platform that supports data labeling for various data types. Its platform’s workflow accommodates annotation processes like adding tags, bounding boxes, transcriptions, and other metadata to raw data like images, text, audio, and video.
Image Annotation for Computer Vision
Image annotation is critical for computer vision applications such as autonomous vehicles, medical imaging, and retail analytics. Toloka supports bounding boxes for object detection, pixel-level semantic segmentation, instance segmentation, image classification, and keypoint labeling.
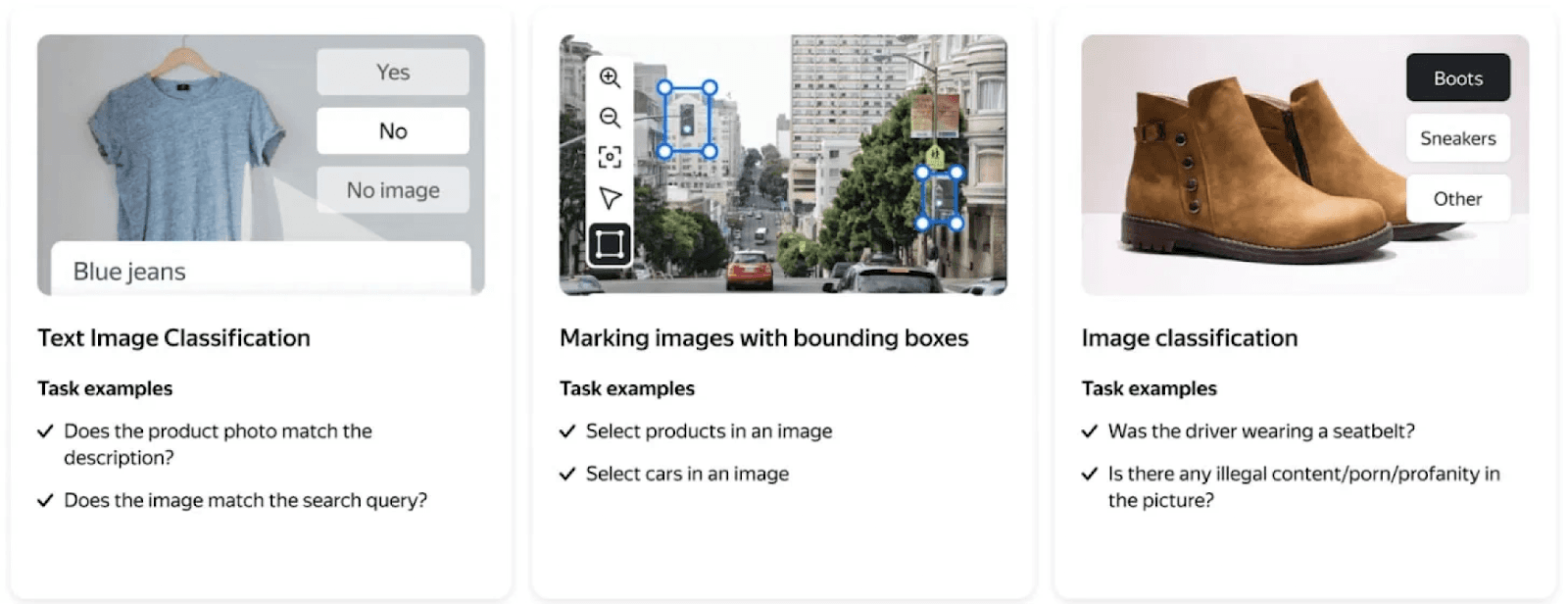
Image annotation through classification and marking with bounding boxes (Source Toloka).
Toloka ensures accurate image labeling services, which translate to accurate model training across various applications like autonomous vehicles in computer vision, facial recognition, and other visual AI applications. These data labeling services help computers understand visual environments with precision, which in turn improves accuracy and safety in real-world applications.
Video Annotation with Object Tracking
Video data requires temporal awareness. Toloka supports frame-by-frame labeling, object tracking across sequences, and action recognition, which are essential for behavioral analysis and autonomous driving systems.
Video annotation involves labeling sequences of images (frames) to train models for video analysis and recognition tasks. The way Toloka handles this with precision makes it the best platform for video annotation.
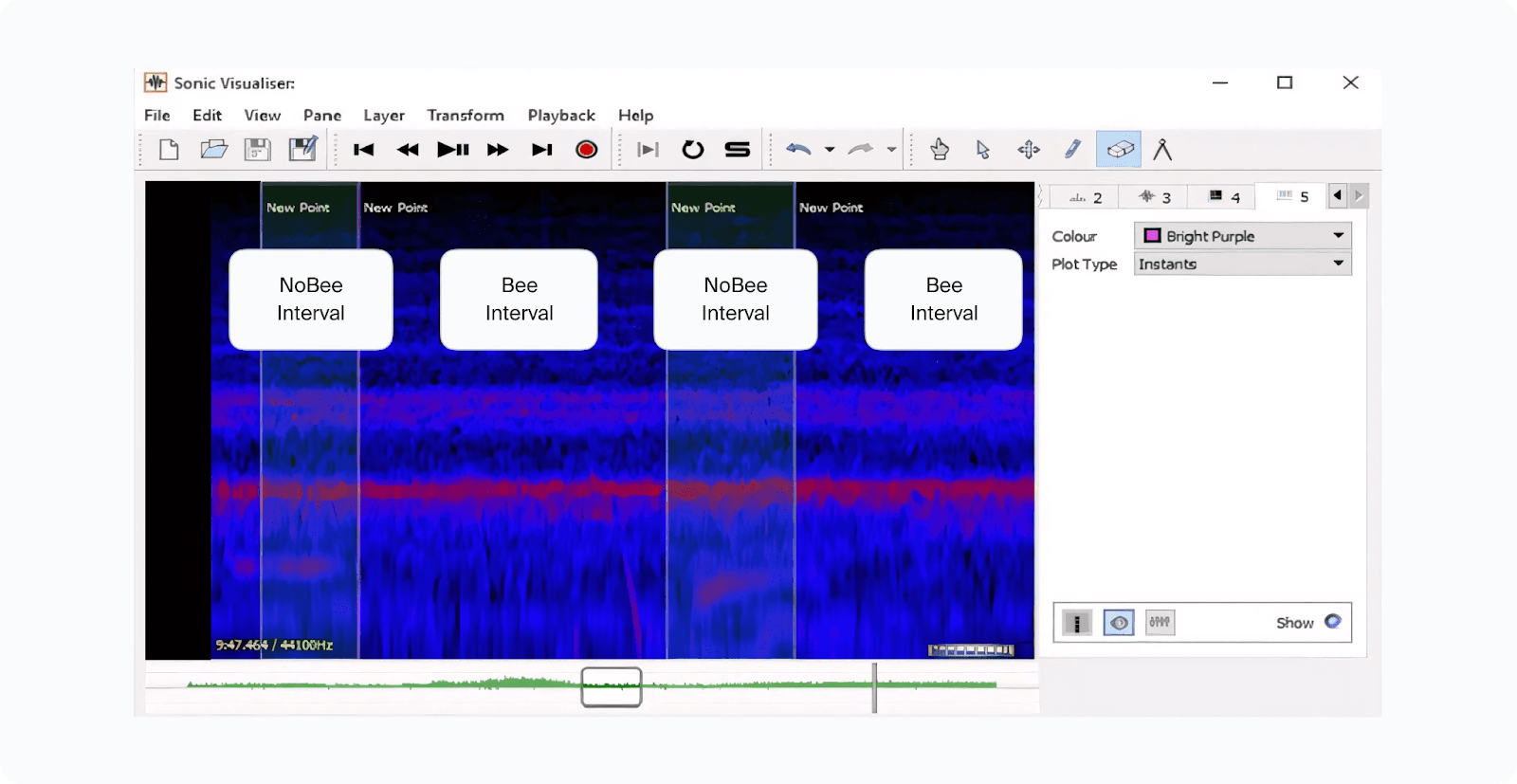
A typical video annotation task (Source Toloka).
Text Annotation for Natural Language Processing (NLP) AI Applications
Textual data that is used for training NLP models like chatbots is also prepared by annotation companies. Text annotation fuels natural language processing, including Named Entity Recognition (NER), sentiment analysis, intent detection, and preference ranking for RLHF. Toloka's experts handle complex tasks like instruction tuning and question answering, which support LLMs and chatbots.
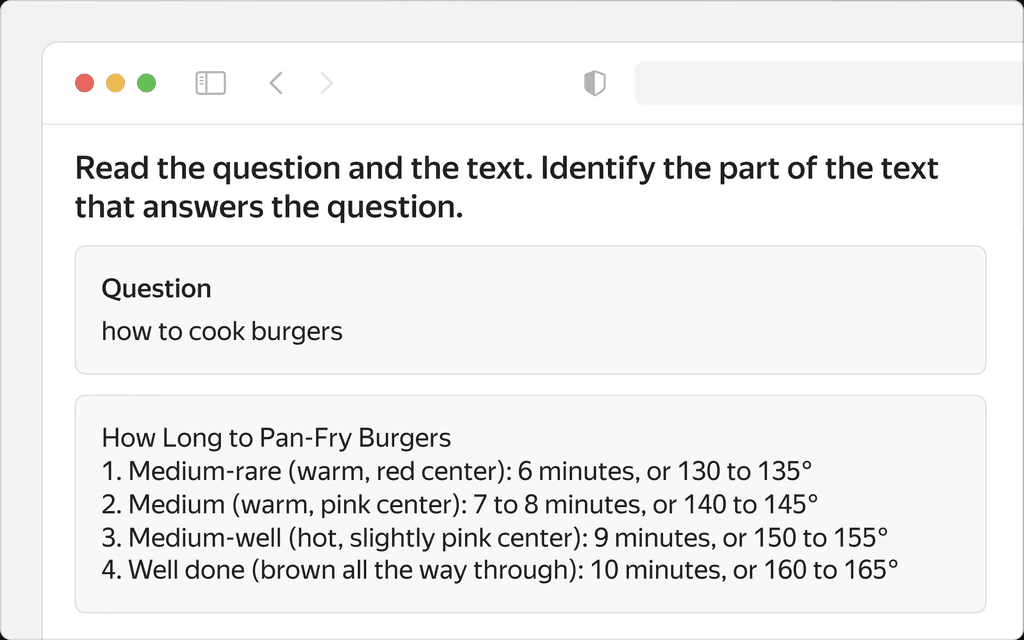
Question answering as a form of text annotation (Source Toloka).
Text annotation is one of the most widely used data types in AI. Toloka supplies expertly crafted demonstrations for multilingual instruction tuning, with examples like 2500 datapoints per language in English, German, and Italian.
Audio Data Annotation and Transcription
Even organizations building audio AI systems are catered to by data labeling companies. For voice-driven AI applications, Toloka annotates audio data with speech-to-text, audio transcription, speaker identification, emotion recognition, and acoustic event detection.
In practice, audio annotation includes transcription and timestamping of speech data. Accurate data labeling and transcription in an auditory dataset improve accessibility tools and conversational AI systems.
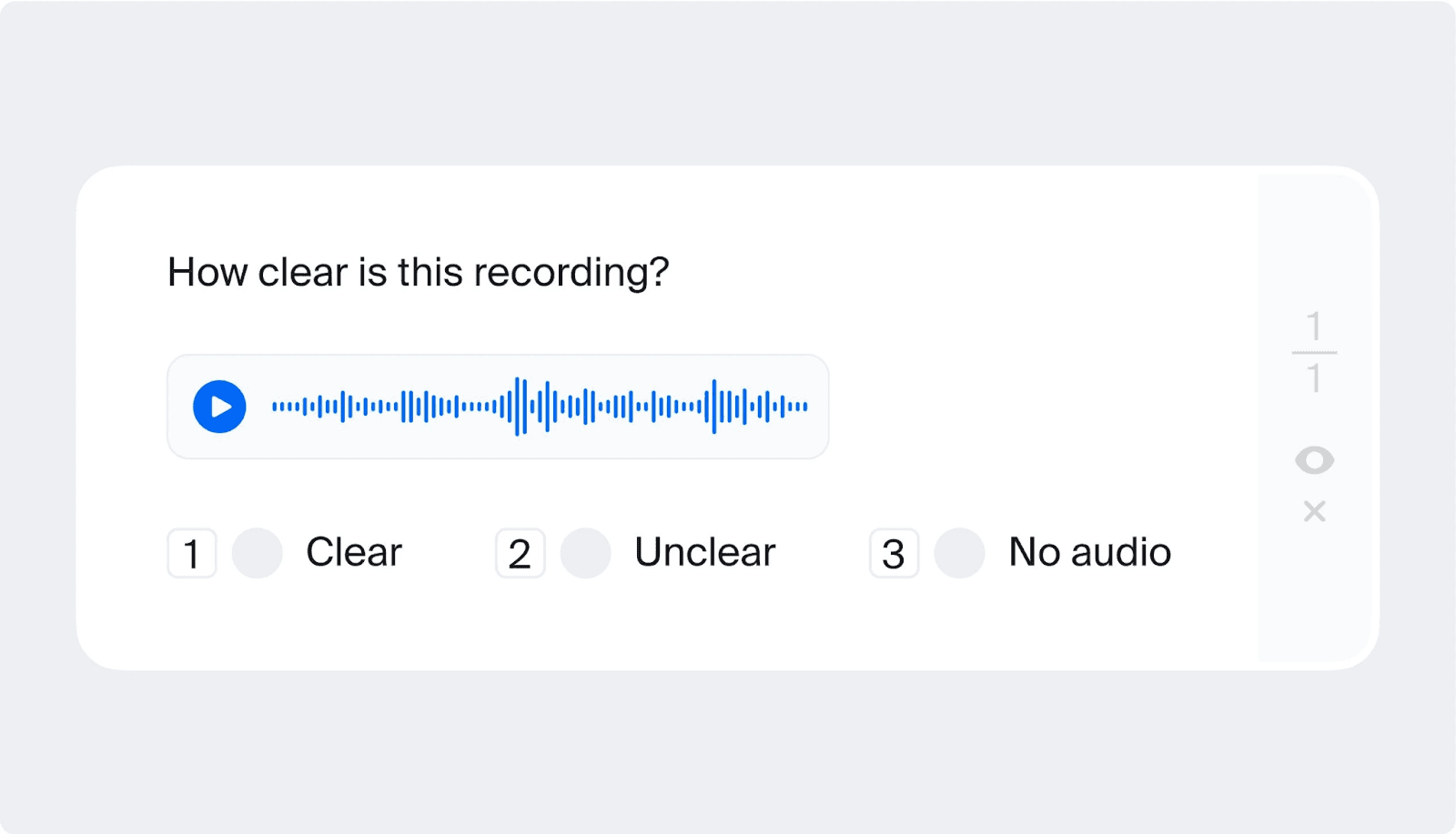
Audio classification as a form of audio annotation (Source Toloka).
Multimodal Data and Complex Projects
Toloka shines with multimodal data, which combines text, images, video, audio data, and even 3D point clouds or LiDAR for advanced AI models. Hybrid pipelines blend AI generation with human verification, which is ideal for vision-language models (VLMs) and AI agents requiring rich, context-aware datasets.
Multimodal annotation enables models to process complex inputs across different media types. Toloka's hybrid data annotation services focus on multimodal data through tasks like demonstrations for supervised fine-tuning (SFT), preferences for RLHF, and evaluation datasets.
How Toloka’s Data Annotation Process Works for Your Data Annotation Project
In Toloka, like every other annotation platform, the project begins with careful task design. Large, complex objectives are broken down into smaller, well-defined annotation tasks that annotators can execute accurately and efficiently. The platform's AI assistant translates needs into full projects and simplifies the workflow by suggesting expertise tiers and sample sizes.
Annotator Matching and Skill Alignment
After task design and decomposition, annotators are matched by skills, expertise (90+ domains), language (40+), and location for cultural accuracy. The platform automatically selects from tiered experts. Domain specialists are selected for complex reasoning, AI tutors for RLHF, and generalists for volume. This targeted-matching improves both quality and cultural accuracy in labeling data.
Quality Control Loops in Data Annotation Services
Toloka’s quality control loops include redundancy, consensus scoring, automated checks, and peer review. These loops ensure errors are detected early and corrected before delivery. Toloka's five-stage Quality System is powered by agentic technology and incorporates:
Systematic sampling
Saged validation
LLM-driven pattern recognition.
This structured approach directly boosts model performance, reduces noise, and improves generalization. For advanced projects, Toloka supports active learning by iterating on feedback to refine datasets.
Why Quality Assurance and Accuracy in Data Labeling?
Quality control is a key consideration when choosing a data annotation partner because modern AI systems are only as good as the data they are trained on. Toloka's Quality Loop ensures superior data labeling. It boasts multi-level verification that combines systematic sampling, staged human review, and LLM-driven QA. These layers guarantee high-accuracy datasets, which is crucial for reliable model training and deployment.
Its Consensus-based validation resolves discrepancies, while gold standards benchmark accuracy. The platform also has automated flags to catch inconsistencies, with human experts on standby to provide final oversight.
Achieving Accurate Labeling with GT Studio Standards
In order to achieve labeling with high accuracy, Toloka applies ground truth (GT) studio-level precision. It embeds gold standard tasks and benchmarks into workflows to ensure labeling meets the highest standards, similar to specialized GT studio approaches but integrated seamlessly into Toloka's platform.
Toloka’s ability to maintain GT studio consistency across hours of labeling work supports high-volume projects without quality loss. The GT studio-inspired methods include detailed bounding boxes and metadata addition, which consequently enhance model evaluation.
Global Workforce and Scalability for AI Projects
Toloka operates a globally distributed workforce of over 6000 active contributors, with 70%+ holding advanced degrees, which enables rapid scaling of data annotation services. This model supports multilingual datasets, regional diversity, and bias-aware data collection. The distributed structure allows organizations to scale annotation volume without sacrificing flexibility or quality, even for time-sensitive AI deployments.
Toloka stands out as a company with the ability to handle flexible annotation formats and projects that scale without inflating budgets, something most clients look for. The platform empowers users with jobs that offer competitive pay per hour, thus attracting skilled annotators who can complete tasks in hours.
Toloka as a Managed Data Annotation Partner
For teams that prefer a hands-off approach, Toloka offers fully managed data annotation services. These include workflow design, execution, quality control, and final dataset delivery. Managed services are particularly valuable for organizations running complex AI initiatives and training large-scale models with strict accuracy requirements. Upon request, the team provides end-to-end dataset delivery with custom workflows and task pipelines.
Compliance, Ethics, and Responsible AI Data
Toloka places strong emphasis on responsible AI. Human oversight ensures ethical data annotation, while privacy and security safeguards protect sensitive datasets. Toloka's responsible AI approach includes ISO 9001/27001, SOC 2 Type II, GDPR compliance, and enterprise SLAs. As a way of ensuring safer AI models, Toloka workflows integrate efforts like red-teaming, vulnerability assessments, and debiasing.
Who Should Use Toloka’s Annotation Services?
One may ask, why Toloka? The answer is simple: Toloka supports a wide range of users, including AI startups prototyping quickly, enterprises developing machine learning products, academic research teams, and organizations training LLMs and multimodal systems. Any organization that depends on accurate data labeling to train reliable models can benefit from Toloka's scalable infrastructure and expert workforce. Also, the ability to request tailored support makes it ideal for projects needing multilingual coverage or domain-specific expertise.
Key Benefits of Choosing Toloka
Any organization that chooses Toloka as its data annotation partner will enjoy unbeatable benefits like:
Scalable global workforce for any data annotation project size, with the ability to handle spikes in hours
Superior accuracy through advanced quality control and human expertise.
Broad support for data types, including multimodal data and audio data, with flexible instructions
Flexible platform and managed service options adapting to project needs.
Ethical and compliant approaches that foster trustworthy AI, with strong security for sensitive AI data.
Wrapping Up
In a nutshell, the success of every AI initiative hinges more on the right choice of an annotation company than anything else. In the rapidly growing AI marketplace, Toloka stands to be counted as the go-to data labeling company. Its combination of technology and human expertise makes it an ideal strong long-term partner for AI development. The platform's AI-assisted setup enables users to match annotation workflows to their capabilities and timelines, while ensuring that your projects meet modern standards for scalability, security, and quality.
Frequently Asked Questions
What does a data annotation company do?
A data annotation company transforms raw, unstructured data into labeled datasets that train AI and machine learning models. These companies employ skilled annotators who add tags, bounding boxes, transcriptions, and metadata to images, text, audio, and video files. This labeled data teaches AI systems to recognize patterns, classify objects, understand language, and make accurate predictions. Without precise data labeling from specialized annotation providers, even the most advanced AI models struggle to learn effectively or perform reliably in real-world applications.
Why should organizations outsource data annotation instead of handling it in-house?
Outsourcing data annotation reduces project completion time by up to 50% compared to in-house efforts. As AI projects scale, datasets grow exponentially in size and complexity, making internal annotation costly and inefficient. Specialized annotation companies bring established workflows, trained teams across multiple domains and languages, and built-in quality control systems. This allows organizations to scale faster without sacrificing accuracy while avoiding the overhead of recruiting, training, and managing large annotation teams internally.
What types of data can Toloka annotate for AI projects?
Toloka supports annotation across all major data formats used in AI development. For images, this includes bounding boxes, semantic segmentation, instance segmentation, and keypoint labeling for computer vision applications. Video annotation covers frame-by-frame labeling, object tracking, and action recognition. Text annotation supports named entity recognition, sentiment analysis, intent detection, and RLHF preference ranking for LLMs. Audio services include speech-to-text transcription, speaker identification, and emotion recognition. Toloka also handles complex multimodal projects combining text, images, video, audio, and 3D point cloud data.
How does Toloka ensure high-quality data labeling?
Toloka employs a five-stage Quality System that combines systematic sampling, staged human validation, and LLM-driven pattern recognition. Quality control loops include redundancy checks, consensus scoring among multiple annotators, automated error detection, and peer review. Gold standard tasks and benchmarks are embedded into workflows to maintain ground truth studio-level precision. For complex projects, the platform supports active learning that iteratively refines datasets based on feedback. This multi-level verification approach catches inconsistencies early and ensures datasets meet accuracy requirements before delivery.
What makes Toloka different from other data annotation companies?
Toloka combines a global workforce of over 6,000 active contributors with AI-assisted workflows and flexible service options. The platform supports 235+ language dialects and 90+ domain expertise areas, with 70% of contributors holding advanced degrees. Organizations can choose self-service annotation with no minimums or contracts, or opt for fully managed services with end-to-end delivery. Toloka's human-in-the-loop approach supports advanced techniques like RLHF, active learning, and model evaluation critical for generative AI. The platform maintains ISO 9001/27001, SOC 2 Type II, and GDPR compliance for enterprise security requirements.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.