← Blog
/

Fable 5 reset the leaderboard. The blind spots didn't move.
Toloka Arena is live. See how your model ranks.
We ran 28 models through 116,760 enterprise task runs. Here's what a better model actually fixes, and what it doesn't.
Last month we reported that the best agent reliably handled about half of routine enterprise work. Since then the most capable model we have ever measured arrived. The comprehension gap it was supposed to close is still wide open.
When a new flagship model ships, the demos are flawless and the production rollouts are not. The distance between those two things is the whole problem, and it is not the one most people think they are buying their way out of.
We run Toloka Arena, a private benchmark of AI agents doing real enterprise software work: logistics, airlines, quick-service restaurants, bank HR, travel support, manufacturing. Agents read policy through retrieval tools, call domain APIs, and have to leave the system in the right state, not just say the right thing. Every model runs each task five times, and every run is graded field by field against an expert-authored answer. A task counts as reliably solved only if all five runs land it.
Since our last report the panel has grown from 18 models to 28, and the corpus to 116,760 transcripts over 99,540 clean graded runs. A genuinely new flagship arrived in the middle of it: Fable 5. It is the most capable enterprise agent we have ever measured, and it does not just edge ahead, it leads almost everywhere. It is also the clearest proof yet that capability was never the bottleneck.
The newest model took the top
Fable 5 reliably solves 57.8% of these tasks. That is the highest score any model has posted in Arena, nearly eight points clear of the next model, Opus 4.8 (50.1%), and further still ahead of the GPT-5.5 family (around 46 to 48%).
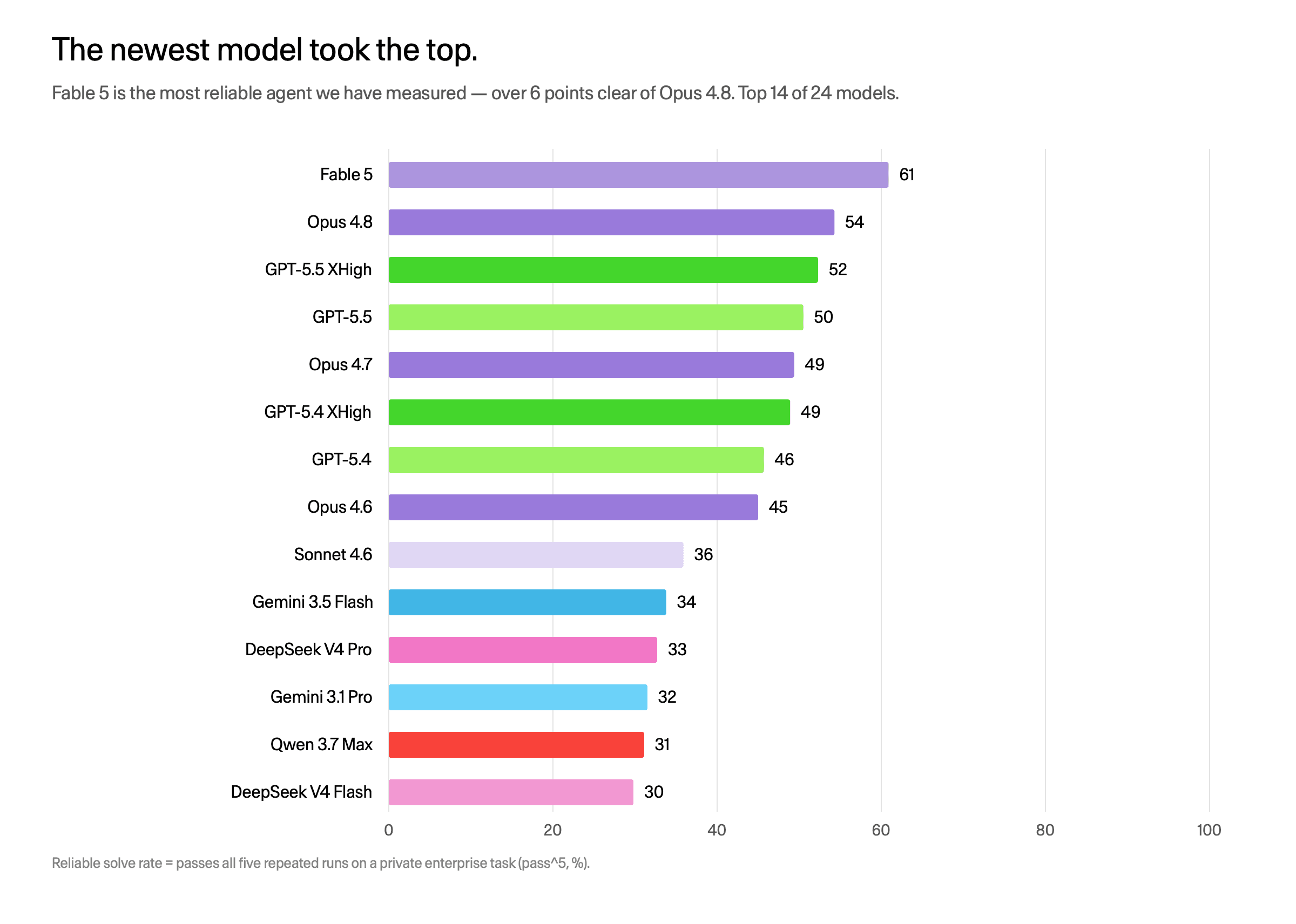
Reliable solve rate by model. Fable 5 leads at 58%, well clear of the previous flagship Opus 4.8.
This is real progress, and worth saying plainly. Fable wins five of the seven enterprise domains we test outright, and posts numbers like 85% on manufacturing that no earlier model came close to.
The cleanest way to see the jump is against the model it replaced. Opus 4.8 and Fable 5 are consecutive flagships from the same lab, scored on the same task set, released twelve days apart.
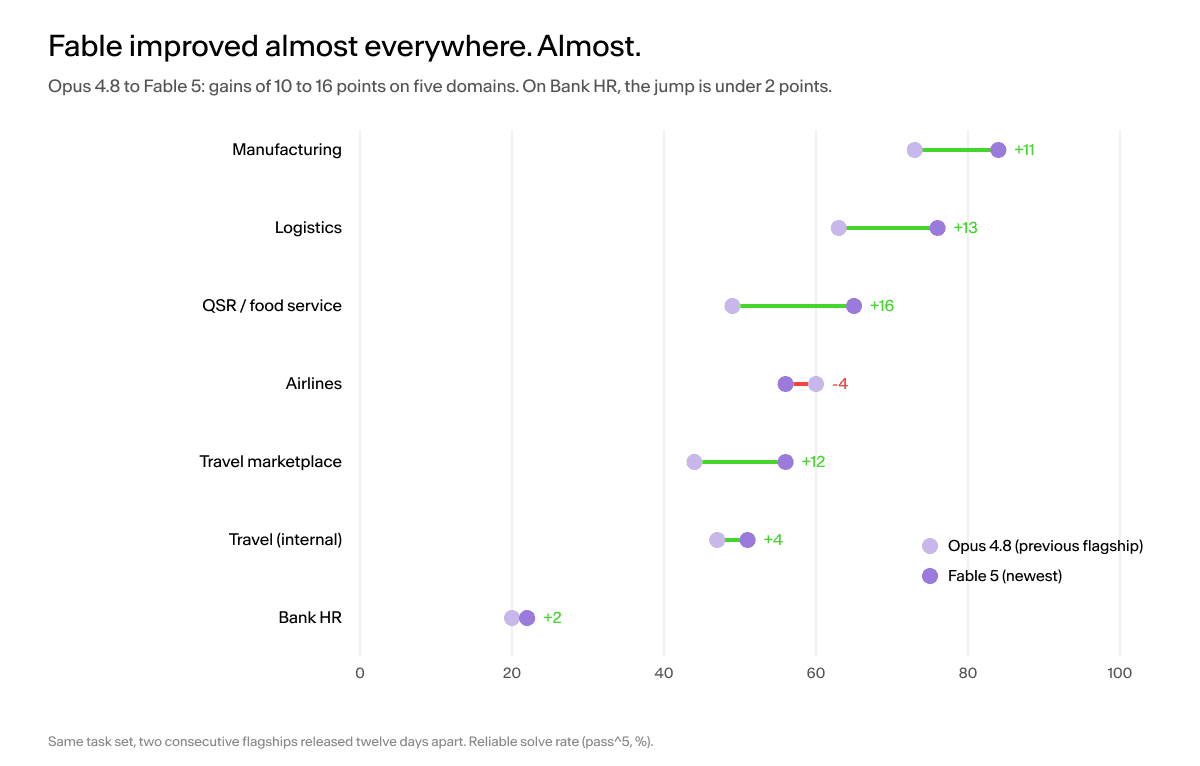
Opus 4.8 to Fable 5 by domain. Double-digit gains almost everywhere, except bank HR.
Fable beats Opus 4.8 on six of the seven domains, with double-digit gains on four of them: plus 16 on quick-service, plus 13 on logistics, plus 12 on travel marketplace, plus 11 on manufacturing. This is a serious model.
And then there is bank HR. Opus 4.8 reliably solved 20.2% of it. Fable 5 reliably solves 21.7%. Twelve days, a new flagship, a clean sweep of the leaderboard, and the hardest comprehension domain moved 1.6 points. That gap is not waiting for a bigger model. It already saw one.
It still cannot read a policy
Bank HR is the most policy-dense domain we test, and it exposes the pattern that runs through everything else. Split what an agent writes into two kinds of fields and the problem comes into focus.
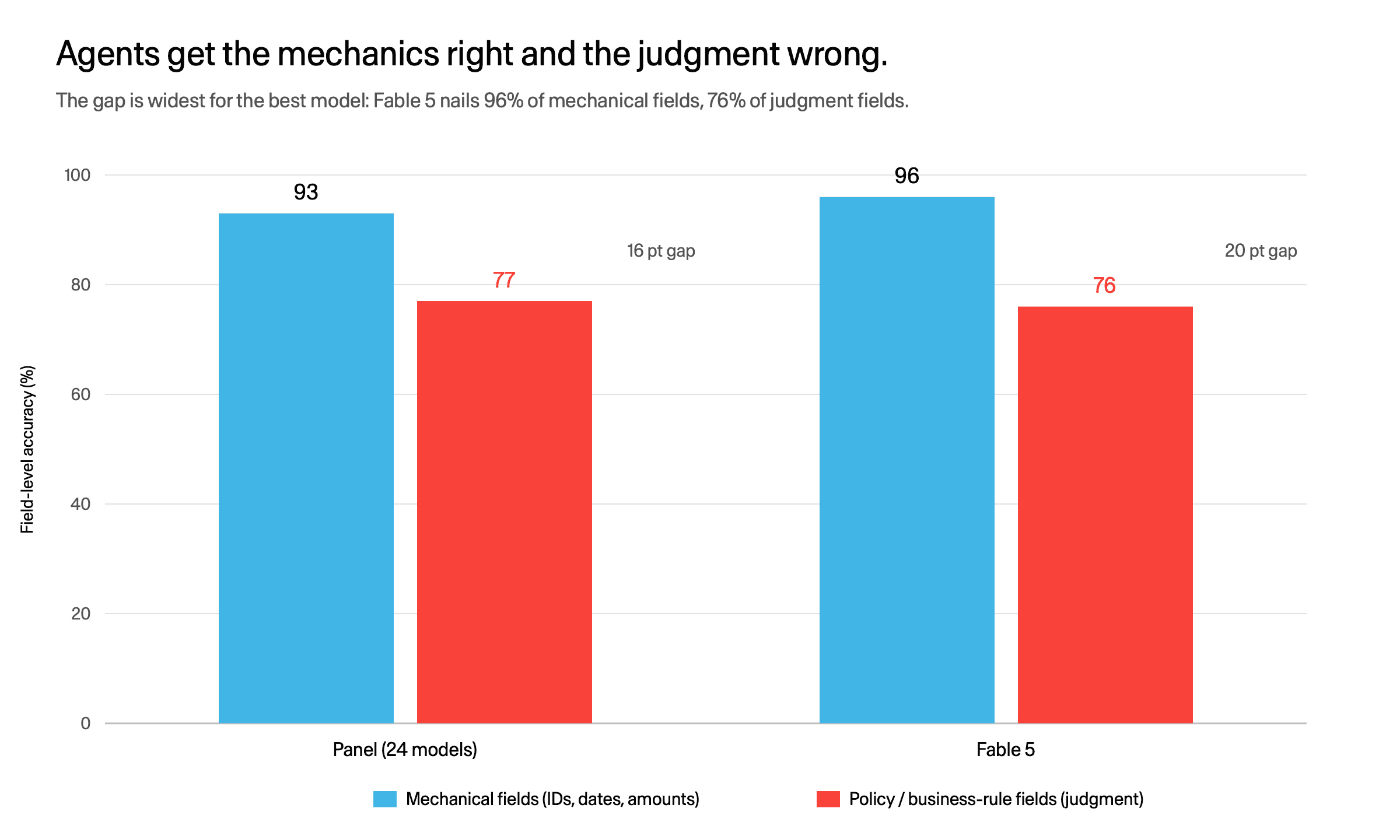
Mechanical vs judgment field accuracy. Fable's gap is the widest: 96% vs 76%.
Across the panel, agents get 93% of mechanical fields right: the IDs, the dates, the amounts, the things with one correct value you can look up. On the policy and business-rule fields, the ones that require reading a rule and applying judgment, accuracy drops to 77%. The telling part: the gap is widest for the best model. Fable 5 nails 96% of the mechanical fields and only 76% of the judgment fields, a 20-point spread. Getting better at the mechanics does not close the comprehension gap. It widens it.
The obvious fix is to give the model the policy. We checked. Retrieval helps, but it is not comprehension.
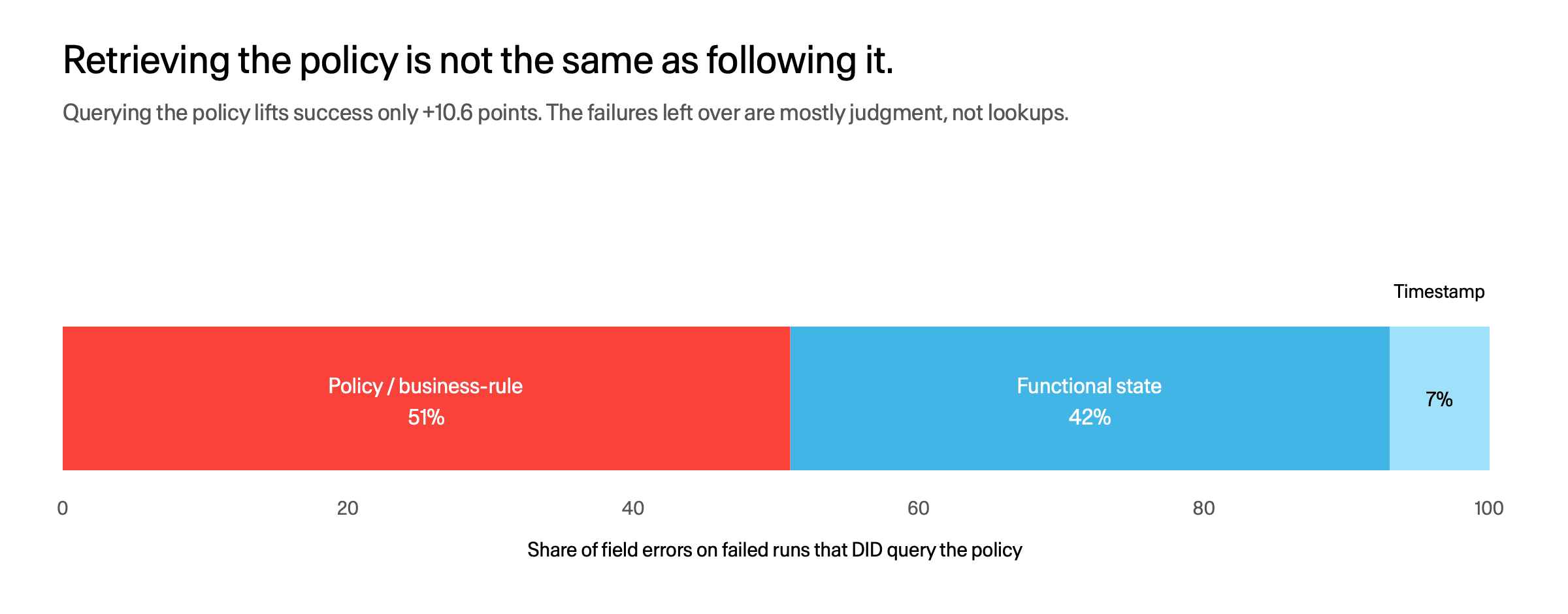
Where post-retrieval failures land: mostly policy and business-rule fields.
Within the same task, runs that actually query the policy succeed only 10.6 points more often than runs that do not. And when a run queries the policy and still fails, the leftover errors are not lookup misses. More than half land on the exact policy and business-rule fields the model just retrieved. Knowing which rule to read is not the same as following it.
Why this is comprehension, not capability
If these were capability gaps, they would look like noise: random, unpredictable, smoothed away by a bigger model. They do not.
The same failures repeat. When a model fails a task it has solved on another run, it usually fails the identical way.
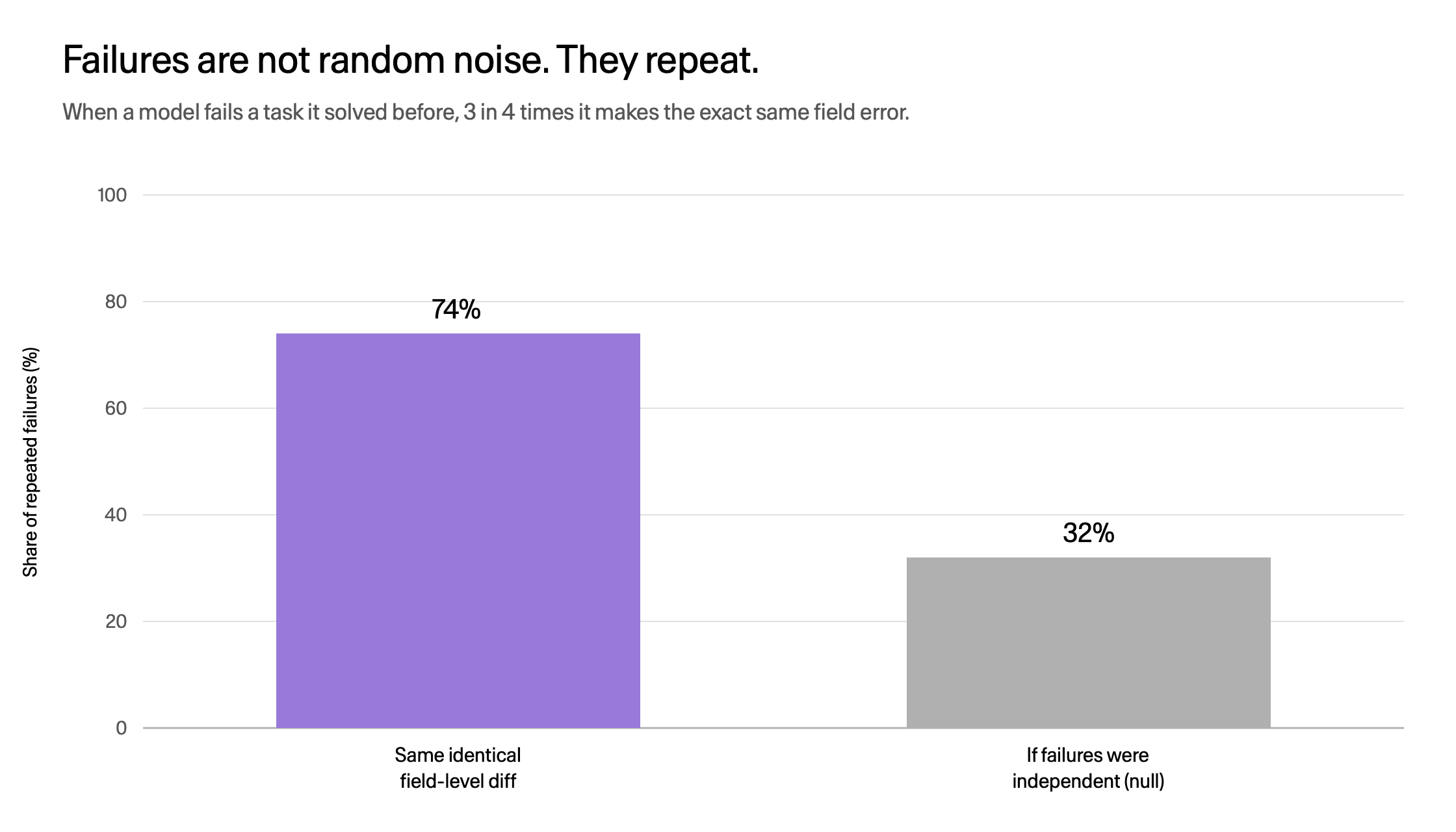
Repeated failures share the identical field-level error 74.5% of the time vs a 32.4% null.
Among flaky cells, where a model passes some runs and fails others, 74.5% reproduce the exact same field-level error, against a 32.4% rate if failures were independent. A flaky agent is not rolling dice. It holds a stable misconception and returns to it.
Upgrades fix the coin-flips, not the blind spots. This is the version story, and Fable is the headline.
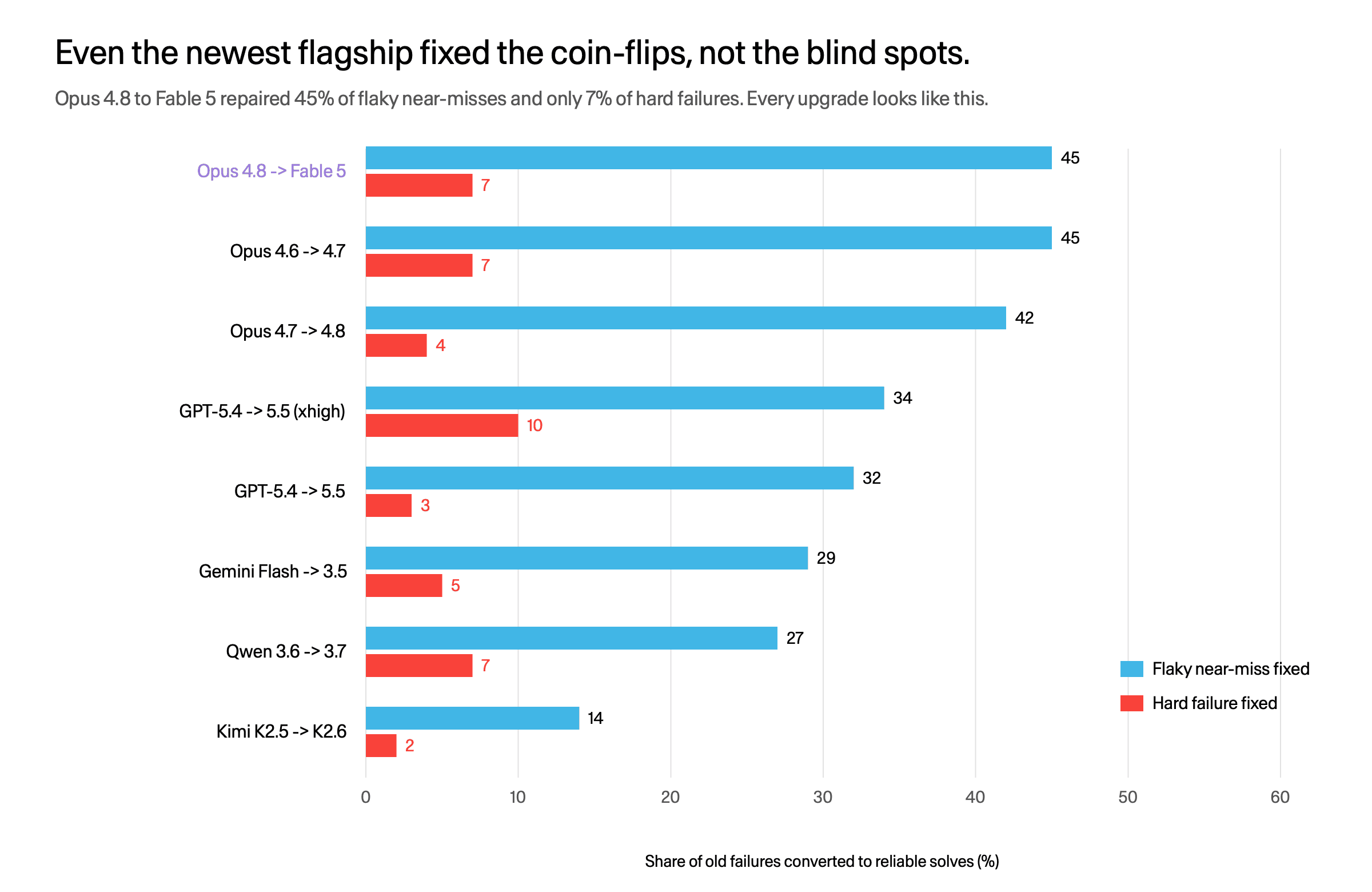
Version upgrades convert flaky cells to reliable solves; hard failures barely move. Opus 4.8 to Fable 5 fixed 45% of coin-flips, 7% of blind spots.
The Opus 4.8 to Fable 5 jump converted 45% of the predecessor's flaky near-misses into reliable solves, and only 7% of its hard failures. Every version pair we can trace looks the same: 16 to 49% of the coin-flips fixed, 1 to 7% of the blind spots. The tasks a model gets reliably wrong tend to stay reliably wrong across a generation, even the generation that resets the leaderboard. Waiting for the next release is a good way to fix the cases you were almost handling and a poor way to fix the ones you were not.
When agents err on judgment, they err in one direction. Policy mistakes are not symmetric.
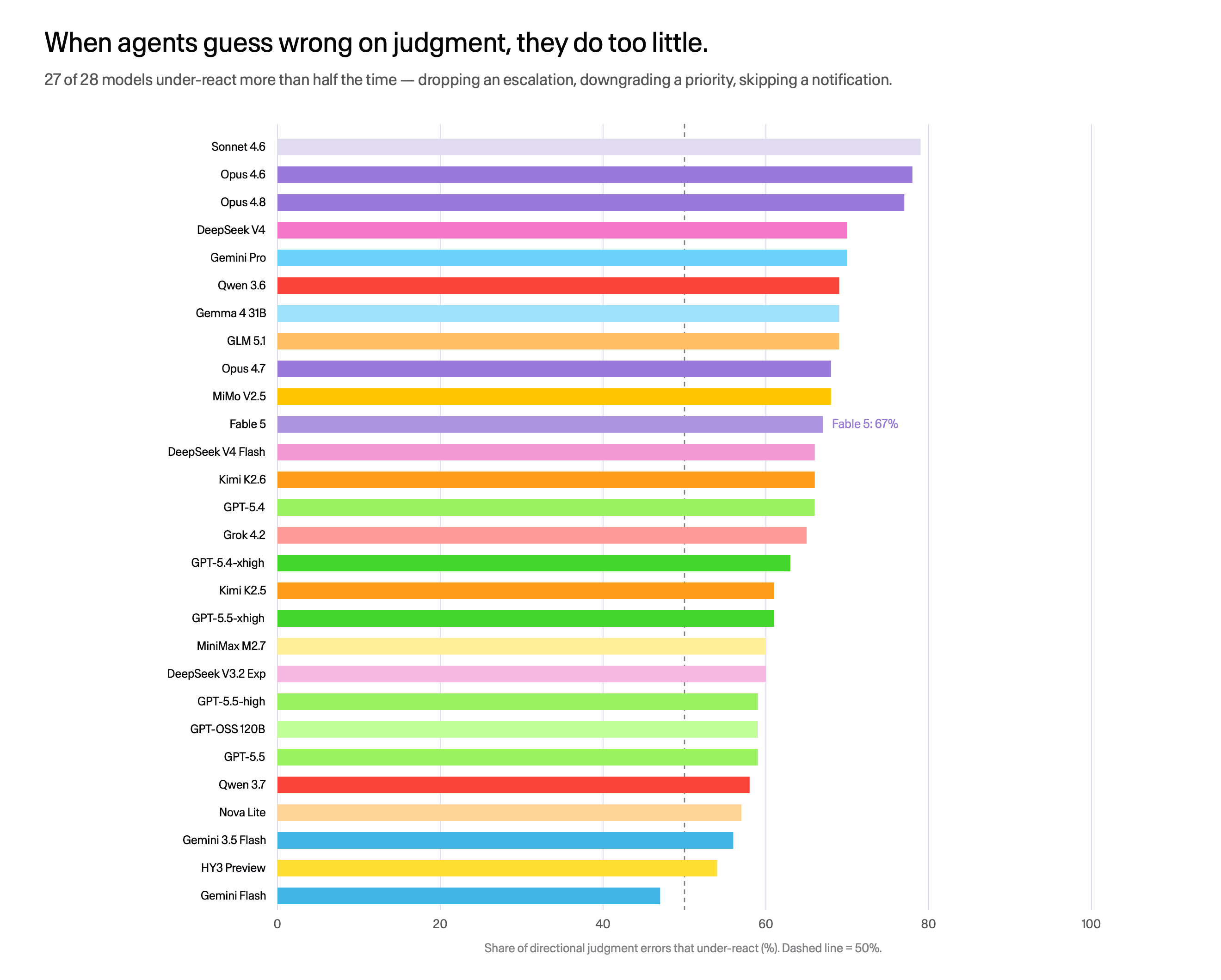
Per-model under-reaction. 27 of 28 models under-react more than half the time.
Of the directional judgment errors we see, 63% move toward doing too little: dropping an escalation, downgrading a priority, skipping a notification. 27 of 28 models under-react more than half the time, and the effect holds after multiple-comparison correction for 26 of them. Fable 5 under-reacts on 67% of its directional errors. The best model is not exempt. If anything, the most capable families lean most conservative, which is comforting until you remember that in an enterprise workflow, the dropped escalation is the expensive one.
Different labs make the same mistakes. This is the finding that should make you stop attributing failures to any one model.
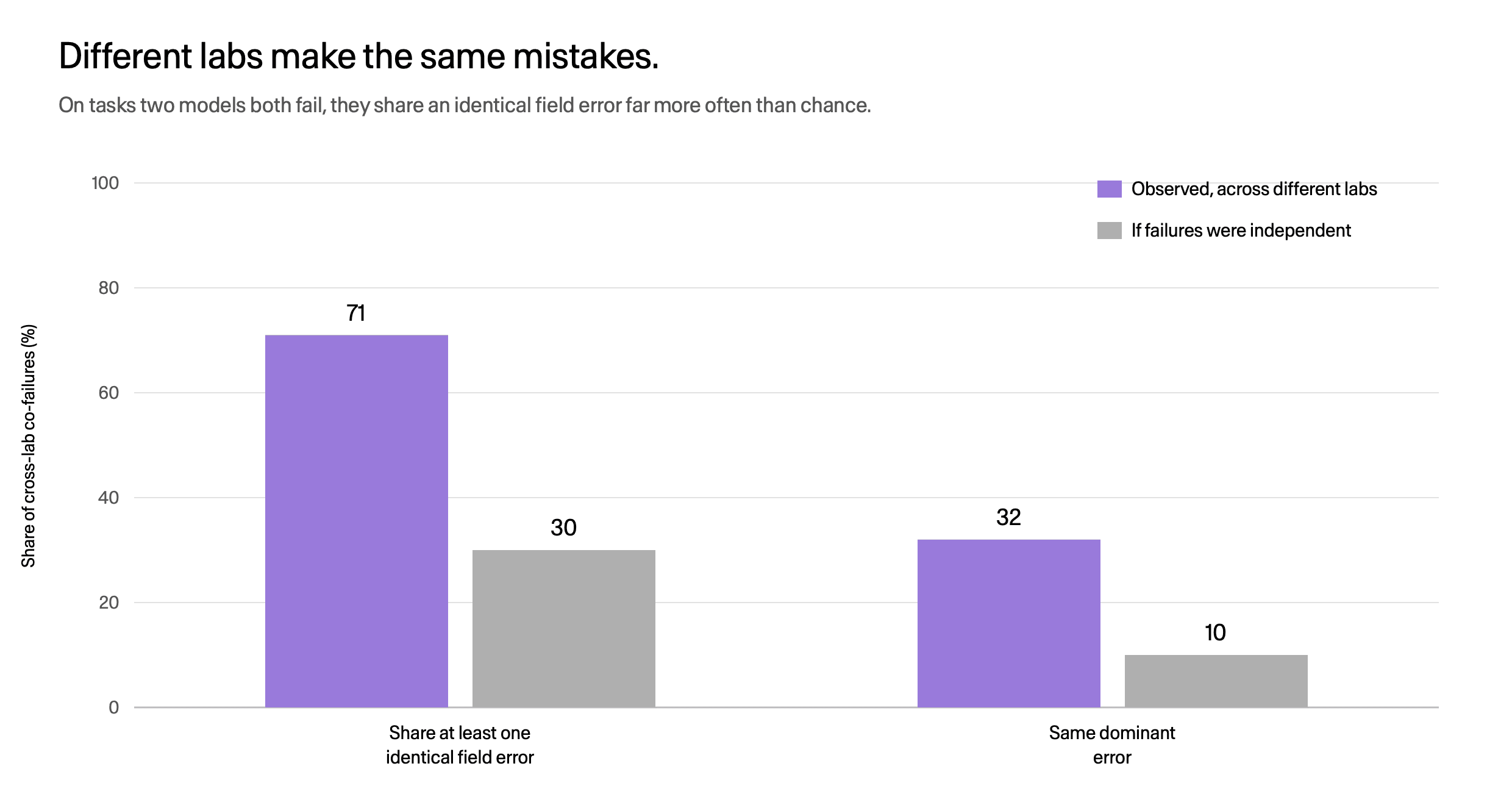
Cross-lab co-failures share an identical error far above chance.
When two models from different labs both fail the same task, they share at least one identical field-level error 71% of the time, against a 30% baseline. The same dominant error shows up three times more often than chance. These are not idiosyncratic bugs. They are shared blind spots in how current agents read enterprise policy, and they cross lab boundaries.
What this means for deployment
If the gap is comprehension, the buying decision changes.
Paying more buys very little at the top. Reliability and price come apart fast.
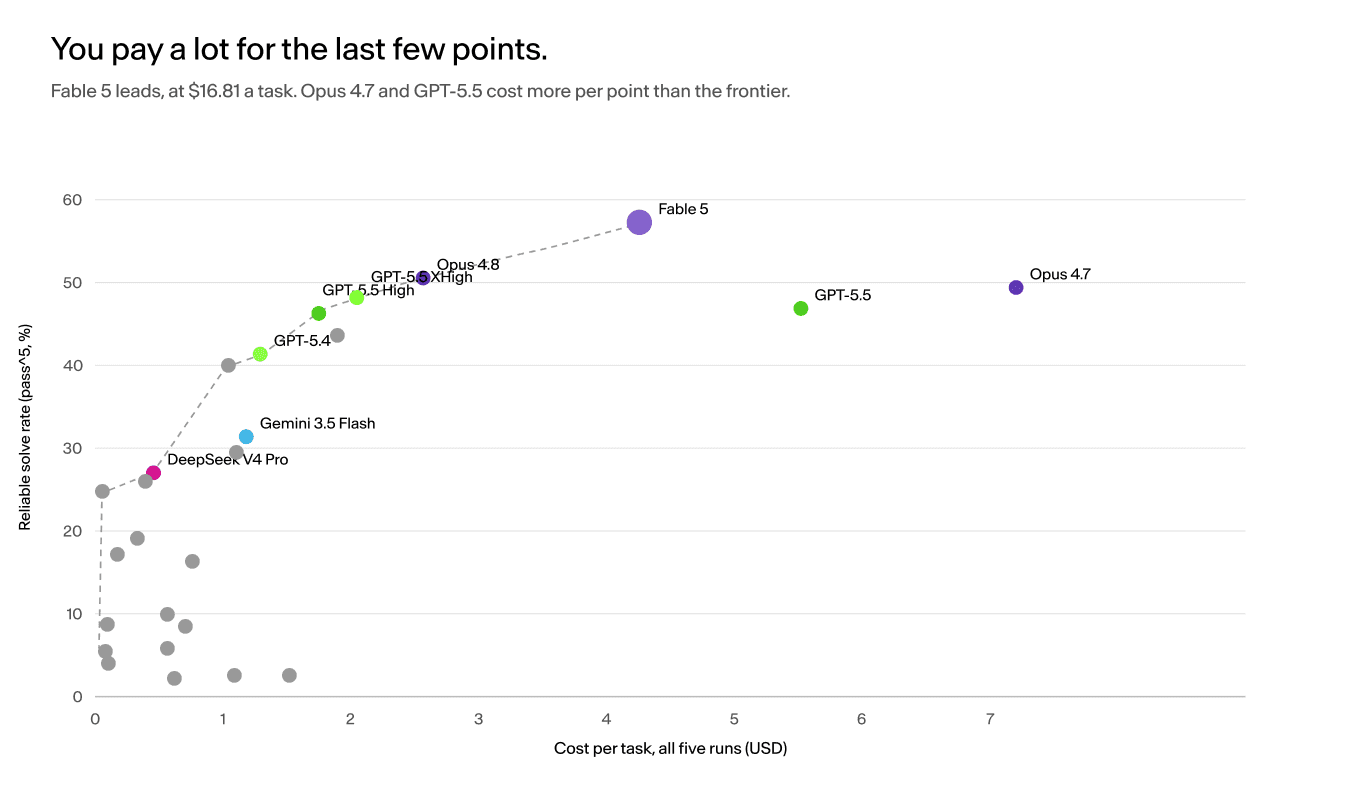
Cost vs reliability. Fable leads at $4.24 a task; Opus 4.7 and GPT-5.5 cost more and score lower.
Fable 5 leads, at $4.24 per task across five runs. But Opus 4.7 ($7.22) and standard GPT-5.5 ($5.39) cost more and deliver less, and the cheap capable models, DeepSeek V4 at $0.40 and a few others, sit on a steep early curve where most of the reliability is bought with the first dollar. The last few points are the expensive ones.
No single model is universal. The score hides a set of specialists.
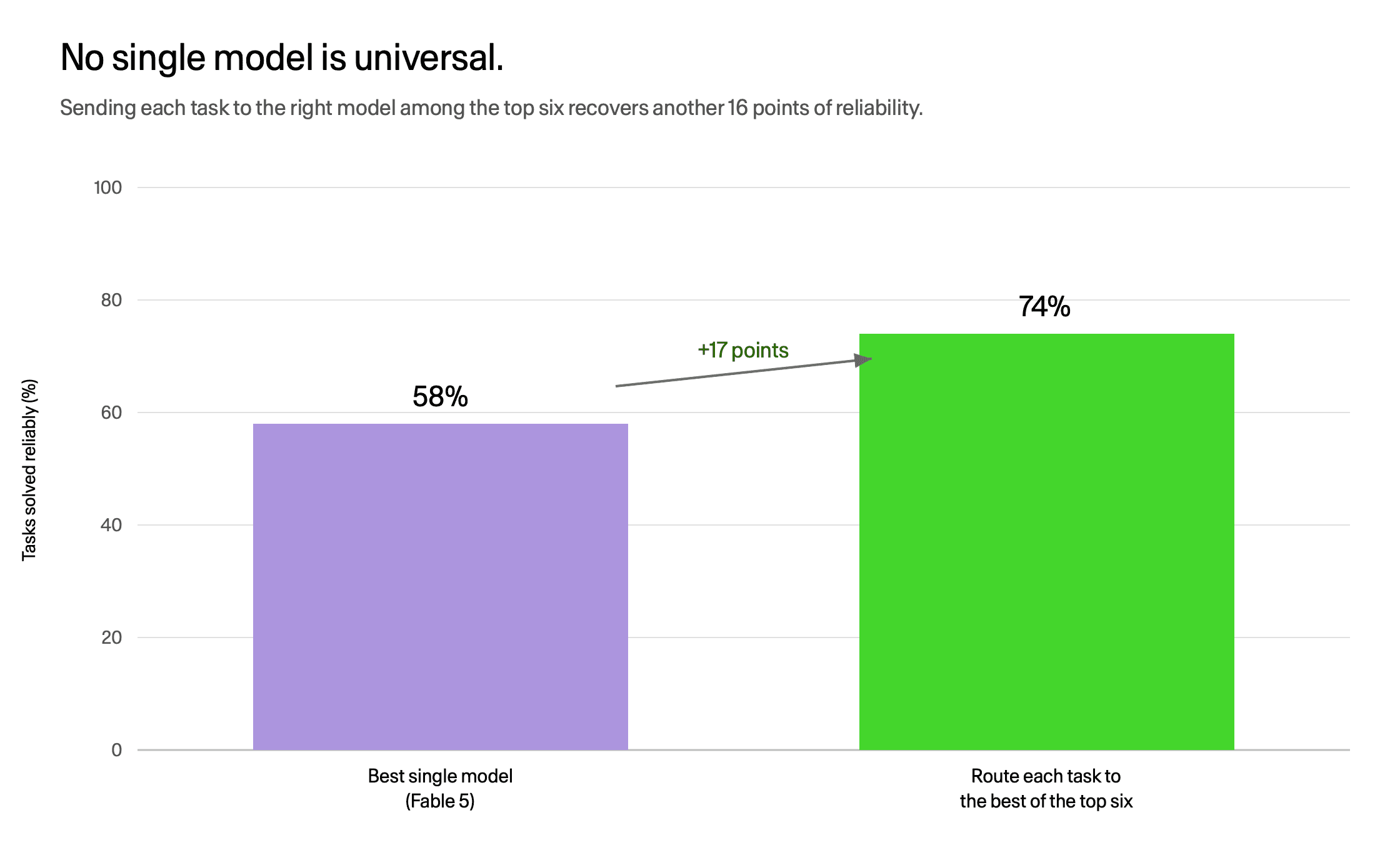
Routing each task to the best of the top six lifts coverage from 58% to 74%.
Send each task to the single best model and you cover 57.8%. Route each task to the best of the top six and you cover 74.3%, a 16-point gain over any one model. Fable wins five domains; Opus 4.8 wins airlines; Gemini 3.5 Flash wins internal travel. The leaderboard is not a deployment policy. The right unit of choice is the task, not the model.
Where these behaviors come from
There is one more pattern in the data, and it points somewhere we are still working.
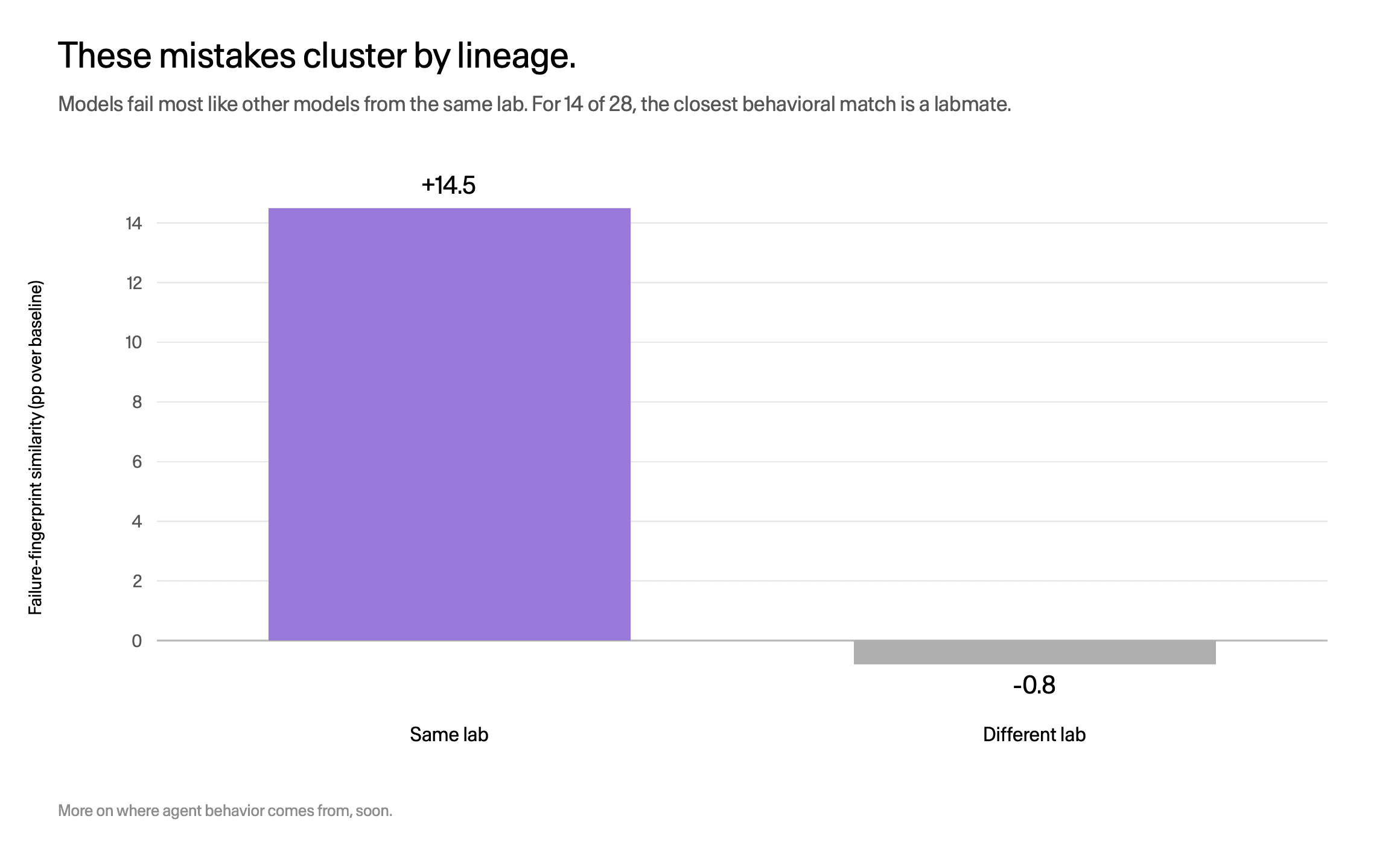
Failure fingerprints cluster by lab. For 14 of 28 models, the closest behavioral match is a labmate.
Those shared mistakes are not evenly shared. Failure fingerprints cluster by lineage: models fail most like other models from the same lab, and for 14 of 28 the closest behavioral match in the whole panel is a labmate. Some models even reproduce specific behavioral components of frontier models that shipped before them. We are looking hard at what that says about how agent behavior is inherited and where it comes from. More on that soon.
The takeaway
A new flagship landed and the ceiling moved. The floor did not. The most capable agent we have ever measured still cannot reliably do bank HR, still under-reacts two times out of three, and still gets one in four judgment fields wrong while getting the mechanics nearly perfect. It improved on its predecessor almost everywhere, and on the one domain that most demands reading a policy and applying it, it improved by less than two points. The next model will not fix this on its own, because this is not the kind of problem a bigger model fixes. It is a comprehension problem.
Closing it is engineering work that sits around the model, not inside it: policy-to-state validators that check the system ended up where the rule requires, task-level routing instead of one model for everything, and state-level review before an agent touches production. That is the layer enterprises actually have to build. The model is necessary. It was never going to be sufficient.
Toloka Arena evaluates 28 models across 116,760 graded agent runs on private enterprise tasks. If you want your own workflows measured this way, get in touch.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.