← Blog
/

Human-in-the-loop ML (HITL): When, where, how much, and how
High-quality human expert data. Now accessible for all on Toloka Platform.
Expert raters, consistent criteria, results you can act on.

Let's be real: we all know why HITL machine learning matters — but the tough part is figuring out the when, where, how much, and how.
Can you rely on spot-checking a small output sample and call it due diligence? Could you use a more capable model to evaluate or train a less capable one and treat that as quality assurance (You can, by the way — but not always. Read more about AI quality control here.)
Or the even bigger question: can you generate training data using AI instead of having humans label it, and trust that data to teach your model what “correct” looks like?
You can. Up to a point.
Smarter models do generate training data, distill knowledge into smaller systems, and evaluate their own outputs.
But past a certain point, something tends to break. In generative systems, outputs can become plausible but hollow — confident, fluent, and entirely incorrect. That happens because the system is optimizing for what looks right in the data, not what’s right in human terms. The result is fluent nonsense, and while you can catch some of it with checks and verifiers, you can’t reliably separate ‘sounds right’ from ‘is right’ at scale.
In classification and decision systems, failure looks different — edge cases get misclassified, rare scenarios get ignored, and models can stay confident even when they’re wrong. But the core problem is similar: automation optimizes for patterns, not for what actually matters in the real world.
Not to mention what happens when real doubt and uncertainty show up. When two domain experts legitimately disagree. When context shifts meaning. When policy changes faster than your retraining schedule. Automation has no surefire way to resolve any of it. A model can't tell you which of two valid interpretations serves your users better. It can't tell whether an edge case in a diagnostic image is a rare condition or a scanning artifact. It can't tell whether an autonomous vehicle should yield or proceed when sensor data conflicts.
Human-in-the-loop isn't a workaround until AI gets better. It's the control layer that defines what "better" even means.
What HITL looks like for AI teams building and shipping models today
For the experts designing, building, and shipping ML systems, HITL means different things. Especially when you're talking about pain points and the solutions that address them.

Different roles, different concerns. Yet all three experts are describing the same need: oversight inside ML workflows, built with design intent rather than salvaged by a last-minute retrofit.
At its core, human-in-the-loop is a family of patterns designed for system success. While it includes human review of AI outputs, it goes much further. In machine learning, HITL transforms human involvement into strategic gates, routing rules, and feedback loops. This ensures that AI systems remain usable, reliable, and scalable in real-world scenarios.
Of course, even robust AI models can struggle with edge cases, ambiguity, and ethical nuance. This shows up in the form of content moderation failures, diagnostic errors, and in everyday “this looks fine but isn’t” model outputs that only human intelligence picks up.
Any problems would therefore simply compound as AI workflows become more autonomous. In generative AI and large language models, a fluent answer (no matter how compelling) can still be wrong. In agentic setups, that wrong answer can trigger actions. The more autonomy you add, the more you need clear human intervention points for your AI.
What human-in-the-loop really involves in ML workflows
Human-in-the-loop means a system or process that is operated, supervised, or otherwise influenced by human decisions. In AI speak, HITL means human involvement at some point in the AI workflow to ensure accuracy, safety, accountability, or ethics in decision-making.
The goal is to allow AI systems to achieve the efficiency of automation while not sacrificing any of the precision, nuance, and ethical reasoning of human oversight.
HITL definition (depending on your ML role)
Human-in-the-loop (HITL) is a system or process where human interaction actively contributes to the operation, supervision, or decision-making of an automated system. In ML, humans aid in training, validating, and refining AI models throughout their lifecycle.
The lifecycle is the key.
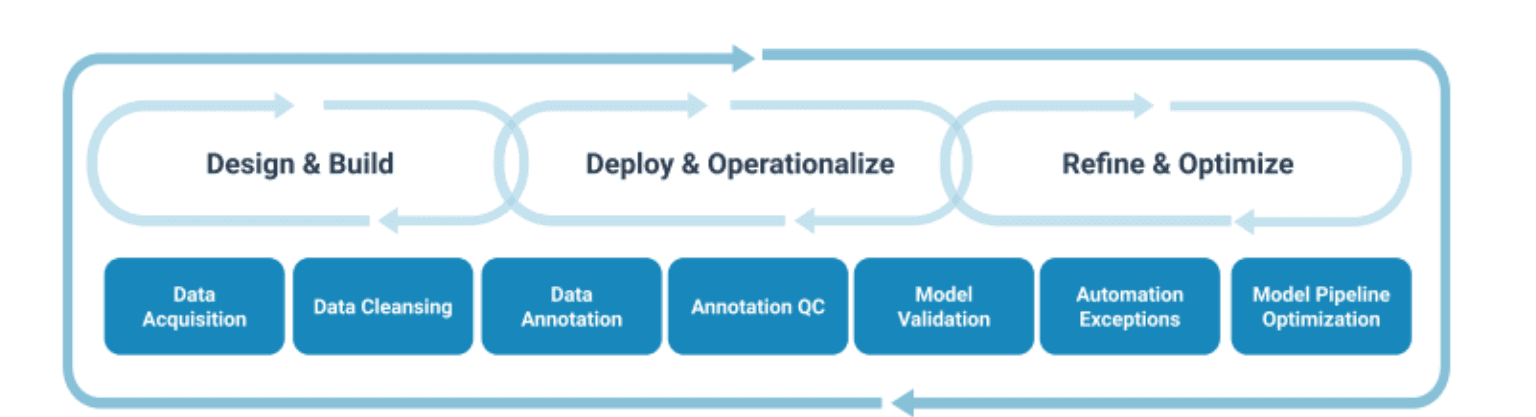
Human-in-the-loop machine learning is not just someone checking a few predictions at the end of the line and giving it an OK or not. It is the line: an intentionally designed feedback loop where human input improves the model, the model assists the human, and the cycle repeats as data, policies, and environments change. This is how continuous human feedback becomes real. Otherwise you're constantly running into manual work everywhere, and none of it makes the model any smarter.
ML practitioners: Your pain is pipeline instability caused by inconsistent labeled data, drifting definitions, and edge cases that sneak through. HITL gives you a way to prevent regressions in ML models without personally policing every sample.
Data scientists: Your challenge might be variance: label noise, disagreement, and evaluation sets that shift under your feet. HITL turns human judgment into a measurable signal.
AI product managers: Your pain is asymmetric responsibility: you’re accountable for AI systems you can’t fully see or verify. HITL gives you receipts of gates, audit logs, escalation paths, etc.
Human in the loop vs human on the loop (HOTL)
HITL and human on the loop are different placements of humans in an AI workflow.
Human in the loop: humans are involved at defined decision points for specified case classes. A human reviewer approves, corrects, or rejects before the output is accepted.
Human on the loop: humans act as supervisors and intervene only when necessary — anomalies, edge cases, low-confidence predictions, or sampled audits.
When to use each: HITL for high-stakes decisions and ambiguous tasks; human on the loop for scaled operations with oversight and monitoring.
Three essential HITL contributions: labeling, tuning, and validating
Labeling: human annotators provide annotations and ground truth for training data and labeled data. In practice, this is where a data annotation platform pays off most — consistent guidelines, quality controls, and expert routing all live at this stage.
Tuning: Humans provide feedback by evaluating and scoring model outputs to improve performance (especially in generative AI).
Validating: People verify decisions before they impact downstream processes.
When and why ML systems need human review
The real-world cracks in “just automate it”
In real-world scenarios, edge cases deviate from training data distribution. A computer vision model that looks robust in controlled data can fail under new lighting, occlusion, background clutter, or new product variants.
The paradox of ambiguity
When people disagree, models inherit the chaos. In some cases, inputs require contextual understanding. If you treat all human labels as identical truth, your metrics become unstable and, most importantly, unreliable.
Ethical gray areas exist
Algorithms crush black and white. Many decisions contain policy nuance that doesn't reduce cleanly to algorithmic reasoning. This is where good judgment and a human element are required.
When rapid change strikes
Domains become stale. Labels drift. Requirements change. A model trained on last quarter's definition can be "correct" and still wrong.
For ML people, these limitations look like regressions and pipeline uncertainty. For data scientists, they might look like noisy experiments and unclear signals. For an AI product manager, it looks like accountability risk and loss of stakeholder confidence.
Use cases that require a human in the loop
Medical AI: In most regulated deployments, radiologists validate AI interpretations because consequence and liability are high, and diagnostic errors are unacceptable without human review.
Robotics and automation: Human intervention is needed for safety-critical scenarios and rare edge cases.
Content moderation: Nuanced decisions on borderline content require cultural context, because policies can't be fully hard-coded.
Financial services and risk assessment: Credit decisions often require explainable AI and human approval gates so outcomes can be defended.
Legal and compliance: AI suggestions are useful, but must pass human review because consequences are contractual and binding.
Beyond these high-stakes examples, human-in-the-loop applies broadly — from quality control for aircraft components to smart city infrastructure. It's especially valuable when datasets are rare, and it powers everyday applications like image classification, natural language processing, and speech recognition. In healthcare, incorporating human feedback during training helps improve model accuracy before deployment.
The shared pattern remains simple: if you can't treat AI outputs as final without a defensible process, you need HITL machine learning in some form.
The business case for a 'human in the loop'
Human-in-the-loop practices improve accuracy by concentrating human effort where it matters. Combined human-AI workflows are used in high-stakes domains precisely because neither humans nor machines alone cover all failure modes.
Human-in-the-loop checkpoints also buys governance: regulatory compliance, audit trails, and clear accountability. It reduces organizational risk by turning "trust the model" into "the workflow checked." It builds trust with end users and stakeholders because you can show what happened and why.
That’s the bridge to action: if you need a repeatable, scalable way to manage human-in-the-loop, platforms like Toloka can help manage this at scale — see Toloka’s guide on how crowdsourcing powers AI data here.
Best practices for implementing human-in-the-loop workflows
Pivot low-confidence predictions to human review. If the model is unsure, don't guess. Rather get human input.
Use uncertainty sampling to identify edge cases in real-time. In a computer vision model pipeline, this is how you surface rare conditions that the training data missed.
Implement active learning to prioritize the most informative examples, so each new label improves decision boundaries faster.
Apply the 80/20 principle. Human effort goes to the small fraction of cases that drive the majority of risk or learning value.
For ML practitioners, active learning means fewer training runs. For data scientists, it means better signal per labeled sample. For AI product managers, it could mean a principled routing policy for human intervention.
Defining clear human roles
Human annotators are generally responsible for labeling training data with consistent guidelines. In computer vision model work, this may include classification, bounding boxes, segmentation, and explicit edge case rules.
Reviewers: Human reviewers validate model outputs before deployment and validate label quality. This is the layer that makes human review measurable.
Domain experts: Human expertise is reserved for specialized or high-stakes decisions. Experts define guidelines, resolve ambiguity, and handle escalations.
Escalation paths: Define what triggers escalation. Low agreement, repeated disputes, high-consequence categories, or policy ambiguity should route upward.
This is the difference between "humans are unpredictable" and "human involvement is structured."
Feedback integration (turn human corrections into learning)
Establish continuous feedback loops. Human feedback must become data, not comments.
Systematically collect human corrections. Capture what changed, why, and under which guideline.
Set model retraining schedules based on feedback volume or drift signals. Retraining should be triggered intentionally, not emotionally.
Use version control for datasets and models. If you can't reproduce, you can't improve. Versioned training data and labeled data turn debugging into engineering instead of archaeology.
This is the core HITL feedback loop: provide feedback → update labeled data → retrain → re-evaluate → repeat.
Quality assurance in human-in-the-loop systems
Use inter-annotator agreement metrics to measure whether humans apply definitions consistently. Disagreement can indicate ambiguity, unclear guidelines, or human error.
Run calibration sessions for consistency. This reduces drift across annotators and human reviewers. You can also add LLM-based QA for automated quality checks where appropriate. Automated checks can detect inconsistencies, missing fields, and common errors, so humans focus on the tough cases.
Maintain audit logging for compliance and improvement. AI product managers need receipts. ML practitioners need traceability. Data scientists need stable evaluation contexts.
Why Toloka Platform fits here
Notice what you just built: routing rules, role tiers, QA metrics, audit logs, and a continuous human feedback loop. Implementing this manually becomes a cumbersome internal operations burden. A platform like Toloka makes it manageable. Toloka's workflow approach is designed to support these HITL checkpoints in a way that reduces engineering overhead while preserving integrity.
Human in the loop vs full automation: which is best?
The decision is not so much HITL or automation. It’s about where human input adds value and where it creates drag.
When to use full automation
Use full automation when tasks are high-volume and low-stakes, with clear success criteria. Mature AI models with stable performance in a stable domain are candidates. Real-time requirements also matter; some AI workflows can't wait for humans.
Even then, many teams keep human on the loop supervision via sampling and monitoring, because drift detection is cheaper than incidents.
When to use human-in-the-loop interventions
Use HITL when decisions are high-stakes with significant consequences, when tasks require nuance or cultural context, when models are early-stage, or when regulated industries require human accountability.
This is where human intervention is mandatory and becomes the control mechanism.
How much human review is enough?
There is no universal answer, but a few practical frameworks help calibrate the right level of oversight for your system.
The simplest starting point is confidence-based routing: set a threshold below which predictions go to human review and above which they are auto-accepted. A threshold of 0.7–0.8 model confidence is a common default for classification tasks, routing roughly 10–20% of outputs depending on model maturity. The right number depends on the cost of errors in your domain — medical and legal contexts warrant lower thresholds than content tagging.
For systems where you cannot route individual predictions, sampling-based oversight is the practical alternative. Auditing 5–10% of auto-accepted outputs on a rolling basis catches drift early without creating a review bottleneck. If your error rate in sampled audits exceeds 2–3%, that is a signal to tighten the routing threshold or retrain.
A third consideration is coverage of edge cases. Raw percentage targets miss the point if sampled audits only catch common-case outputs. Stratified sampling — deliberately including low-frequency categories, recent distribution shifts, and flagged inputs — gives you a more accurate picture of where the model is actually failing.
The practical rule: start with more human review than you think you need, measure your error rate, and reduce oversight only once you have evidence the model is stable. Cutting human review prematurely to save cost is the most common way HITL implementations fail quietly.
Hybrid approaches that calibrate human effort to actual risk
Risk-based human-in-the-loop frameworks: Match oversight intensity to consequence severity. Low-stakes predictions? Let the model run. Catastrophic downside? Lock in mandatory human sign-off. No blanket "always review everything".
Confidence-based routing: Set sharp thresholds. High-confidence outputs fly straight to production. Low-confidence ones? Auto-escalate to a human reviewer. This turns uncertainty into a precise trigger, not a vague feeling.
Smart sampling for ongoing quality: Don't sample blindly. Use periodic, targeted human curation on auto-accepted outputs, stratified by model confidence, drift signals, or edge-case patterns. Catch regressions early without drowning your team in busywork.
The goal is to optimize oversight where it's most impactful, in such a way that your ML practitioner keeps velocity, your data scientists keep signal, and your AI product manager keeps defensibility.
Challenges and limitations of HITL
Scalability constraints
Human annotation is slower and expensive at scale. Bottlenecks appear if you route too much work to humans. Balancing speed with accuracy requirements is the core tension.
Cost considerations
Specialized domains require expensive subject matter experts. Continuous human feedback creates ongoing costs. The ROI question becomes: cost of errors vs cost of human oversight.
Human factors
Annotator fatigue and declining accuracy are real. Bias in people exists. Training and calibration requirements are often underestimated.
Mitigation strategies
Automate routine checks so humans focus on complex cases. Use quality monitoring, inter-annotator agreement, and annotator rotation. Maintain clear guidelines and regular calibration. Platform solutions reduce overhead by standardizing workflows, QA, and expert routing across projects.
If you're building on Google Cloud, this mitigation often looks like combining Google Cloud pipelines with a dedicated human-in-the-loop layer for data quality and review. The infrastructure runs fast; the human oversight stays targeted.
Agentic AI takes charge, but humans stay in control
As AI systems become more autonomous, oversight shifts from reviewing every model output to governing actions. Agentic systems don't only predict; they decide and act. That changes the design requirement.
The future looks less like "human in the loop for everything" and more like "human over the loop" at checkpoints. Approval gates, rollback mechanisms, and monitoring triggers become standard. Human-computer interaction becomes part of system safety: the workflow must make it easy for humans to intervene quickly and correctly.
The symbiotic future is not humans versus machines. It's AI handling routine tasks and humans handling exceptions, policy boundaries, and strategy — supported by continuous human feedback that keeps systems aligned as real-world scenarios shift.
This is also where Google Cloud style architectures and platform HITL layers work well together: the model stack runs at scale, and the human-in-the-loop layer enforces governance at the right moments.
The bottom line: Human-in-the-loop powers better models, equipped with real accountability
Human-in-the-loop machine learning is the practical bridge between AI capability and human judgment. For ML practitioners, it means quality gates for labeled data so model training isn't repeatedly undermined. For data scientists, it means measurable disagreement and stable evaluation so models improve with confidence. For AI product managers, it means a defensible process — human oversight, audit trails, and approval gates. So, accountability is real.
The real power of HITL lies in turning human judgment into a repeatable, scalable asset: one that stabilizes pipelines, sharpens signals, and builds genuine trust. Toloka makes this effortless at scale. Its AI-assisted project setup serves as your co-pilot, instantly translating needs into optimized HITL checkpoints with minimal effort. Automatic routing taps a three-tier expert network — Domain Experts for high-stakes nuance in 90+ fields, AI Tutors for precise RLHF and reasoning tasks, General Annotators for efficient volume — balancing quality, speed, and cost perfectly. Always-on LLM-based QA validates every output in real-time, catches drift early, tunes from your feedback, and eliminates manual overhead and engineering rework.
The outcome? Faster, more reliable iteration; defensible decisions; and AI that earns human trust.
Build your HITL workflow with Toloka Platform
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.