← Blog
/

VIST: A new benchmark for brand style transfer in AI image generation
High-quality human expert data. Now accessible for all on Toloka Platform.
AI image generators can produce high-quality visuals, yet most established brands still don't rely on them for production work. The market for marketing content creation is huge, but only about 3.7% uses AI-based generation for brands. That’s because even small deviations from approved brand rules often make outputs completely unusable. Industry research consistently shows that enterprises mainly use AI for early concepts and draft assets rather than final creative. Smaller companies without strict guidelines might have more flexibility, but mature brands need asset generation that stays aligned with their visual identity without manual correction.
Existing benchmarks evaluate general image quality (e.g., Artificial Analysis, LMArena), and there are frameworks for style transfer broadly (e.g., USO-bench). But none focus specifically on what designers care about most – brand-style transfer, which is a model's ability to maintain a brand's signature visual language.
We built the VIST benchmark to close that gap. Using pairwise comparisons against reference material from established brands, 393 expert raters produced 39,300 judgments across five aesthetics and 12 systems to reveal how well current models maintain visual identity under real production expectations.
Benchmark methodology
The framework below shows how we tested whether models can genuinely hold a brand’s visual identity.
Experimental design
Absolute rating scales are widely used in image evaluation, but they break down for style transfer, where judgments are subtle and difficult to calibrate across raters. We therefore evaluate style preservation through side-by-side comparisons conditioned on a reference style.

Here systems are compared pairwise. Raters examine brand reference images alongside two generated outputs and select the one that better matches the reference style. All comparisons are blinded.
Evaluation criteria
Brand style fidelity encompasses multiple elements, which were explained to the raters at the beginning of the survey:
Color palette and tonal balance
Composition and layout: framing, perspective, placement of elements
Brand elements: e.g., logo accuracy, iconography, type/lettering if present
Textures and line quality: brush/pen strokes, grain, edge fidelity
Human depiction (if present): how facial features, hands, and body parts are drawn
Test dataset
Five brands with recognizable, distinct illustration styles were chosen: Coinbase, Notion, Dropbox, Revolut, and Headspace. All styles are diverse and represent popular contemporary directions in brand illustration. For each brand, experts in visual design selected 10 reference images exemplifying their visual identity.
Brands were selected based on two sets of criteria. First, brand recognition was central to the process. The goal was to select companies that people had encountered before rather than ones they had seen for the first time. The second set of criteria concerned stylistic trends. Our selection reflects the range of visual mediums brands work across today.
3D category
Vector aesthetics
Colored hand-drawn illustrations
Vector with clear compositional rules
In accordance with the individual specificity of the styles, we created 15 brand-specific prompts, three per style, written in natural language to describe scenes for generation.

Evaluation setup
We evaluated 12 systems representing consumer-facing products and foundation models used by designers: Gemini 2.5 Flash Image (Nano-Banana), GPT Image 1, Exactly.ai, Firefly Image 4 Ultra, FLUX.1 Kontext [max], Freepik, Krea, Leonardo.ai, OpenArt, Qwen-Image-Edit, Recraft, and Wixel. All generations were produced in October 2025 using default settings.
Every system received identical prompts, and we collected the first four outputs per prompt, with no cherry-picking or regeneration. This yielded 60 items per each of 12 systems (5 brands × 3 prompts × 4 variants). Having 66 system pairs out of 12 systems, we established pairwise evaluation for 3900 tasks (selecting a random subset out of 3960 to form 39 task suites of 100 tasks each).
Each annotator received a randomly assigned questionnaire. Annotations were overlapped to conduct additional analysis related to professional biases. Data collection occurred over one week with a minimum threshold of five votes per pair to balance statistical reliability with practical timeline constraints. The result was unequal vote counts per pair ranging from five to 18 (mean 10.08) and producing 39,300 total judgments provided in this dataset.
To apply Bradley Terry Davidson (BTD) modeling, we aggregated judgments into overall rankings by the majority of raters’ votes. The system with the most votes became the winner within the pair, and when votes were tied, we recorded draws (8.46% of pairs where systems produce indistinguishable results).
The 393 raters comprised 54.5% design professionals (designers, art directors, illustrators, artists, photographers) with expertise in visual identity and brand consistency. An additional 17.8% were non-professional image creators, and 27.7% didn’t specify their profession. These latter groups represent a significant segment of the AI image generation user base, utilizing tools for personal projects or professional needs outside creative roles. To assess potential divergences, we analyzed the preferences of professional creators versus other raters in the Performance Results section.
Performance results
The benchmark revealed meaningful differences between systems. Below are overall rankings and brand-specific breakdowns, showing average win probability with 95% confidence intervals.
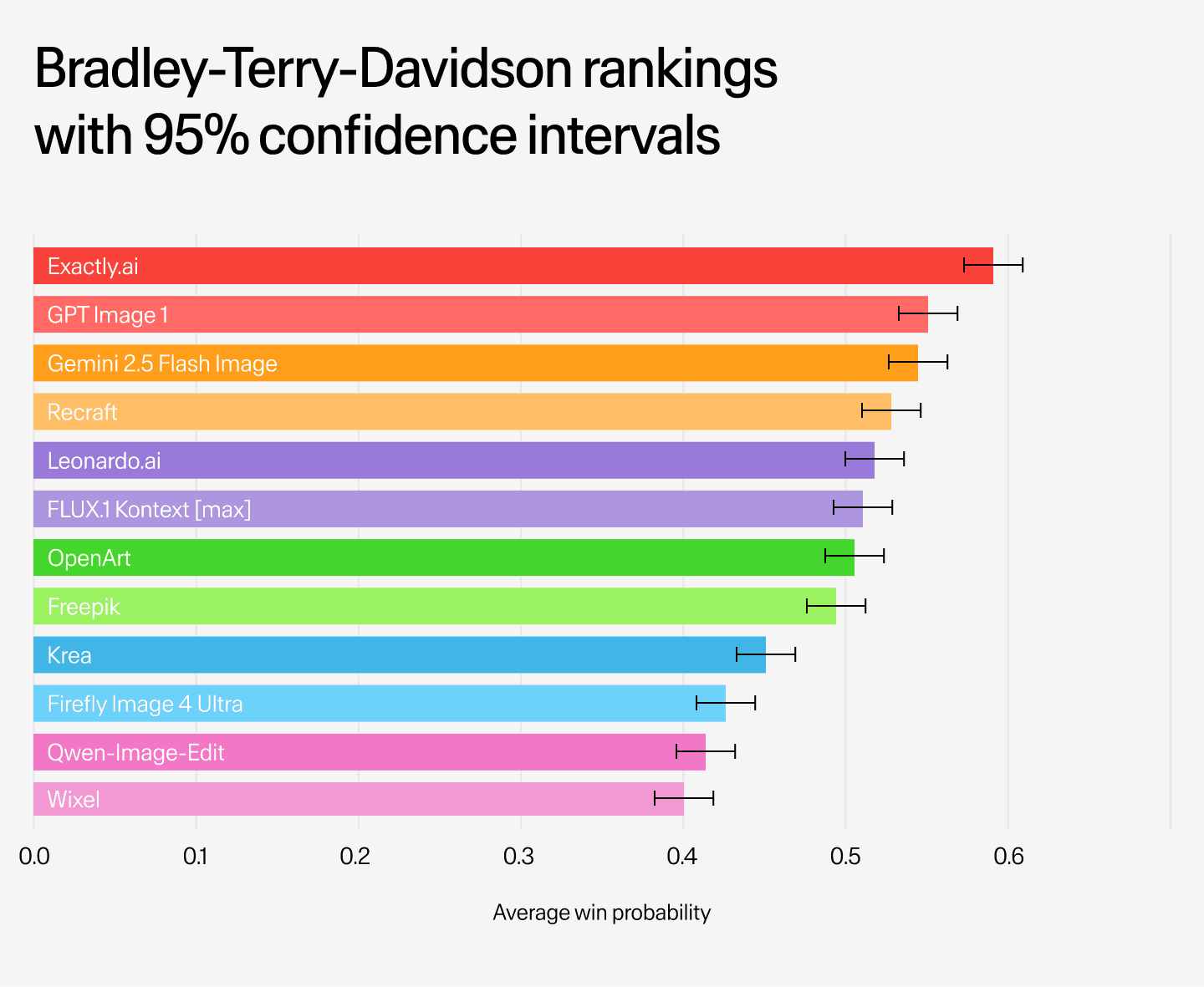
Overall, Exactly.ai stood out as the strongest performer and achieved the highest win probability with a clear gap to the rest of the field. GPT Image 1 and Gemini 2.5 Flash Image followed closely and showed overlapping confidence intervals that point to strong performance from frontier models not built specifically for the task. Recraft and Leonardo.ai came next and performed well, though their results varied more by brand. The remaining systems ranked lower and were less consistent at maintaining brand visual identity in production-style scenarios.
Several consistent patterns emerged across the evaluation.
The generalization vs. specialization trade-off: Top-ranked systems maintained consistent performance across all five brand styles, demonstrating robust generalization. Some lower-ranked systems, however, showed relative strength on specific brands, suggesting certain system-aesthetic compatibilities that aggregate rankings obscure.
Reference count limitations: Several systems accepted fewer than 10 references due to input constraints, a limitation that could theoretically disadvantage them. In each case, the recommended style transfer workflow was followed, using the feature as designed to achieve optimal results for that technology.
First-output consistency reveals production readiness: Evaluating first outputs without regeneration mirrored real production workflows. Top systems produced consistently on-brand images, while lower-ranked systems showed high variance and only occasionally matched the style in a predictable way. The resulting consistency gap has clear implications for teams that rely on dependable production output.

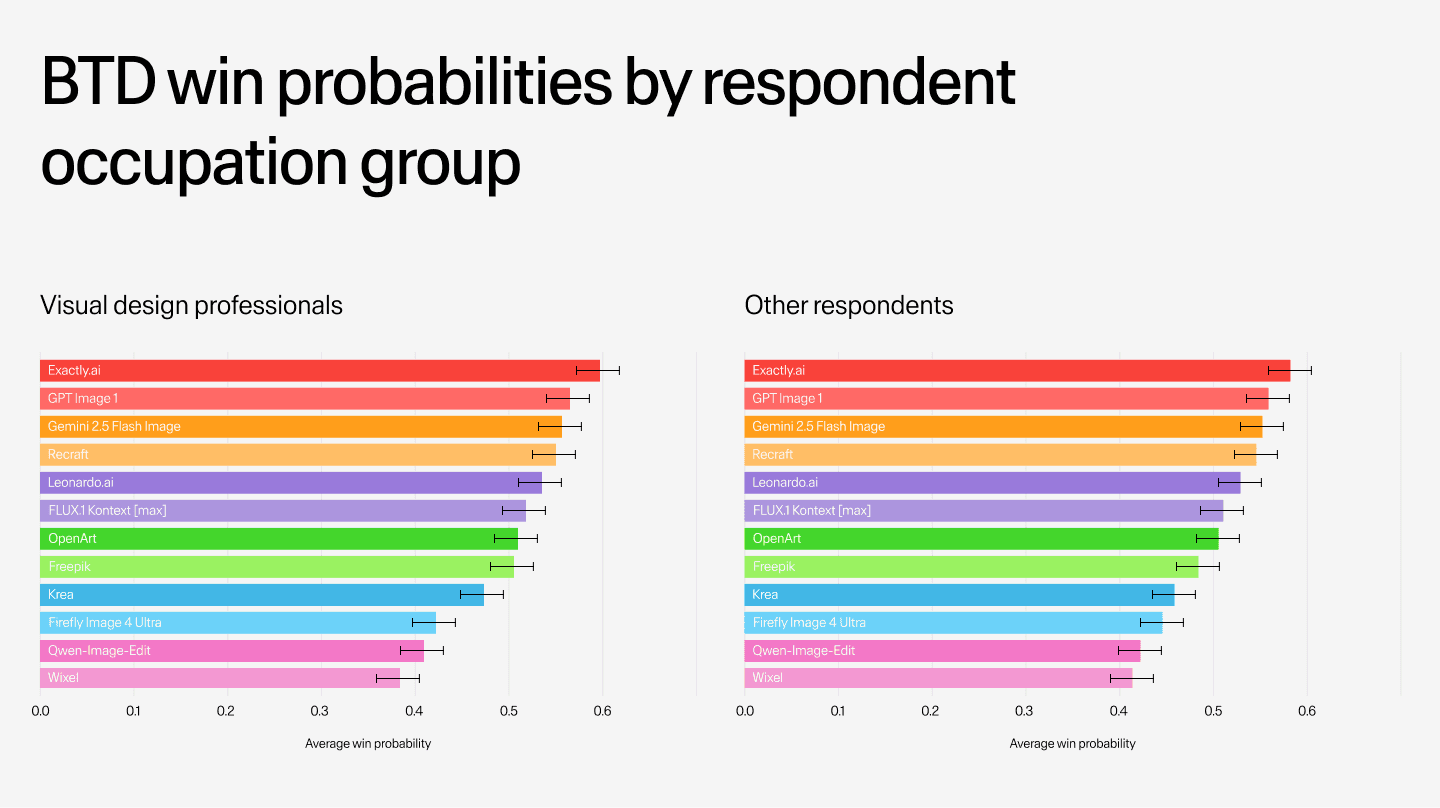
Rater expertise and cross-group validation
More than half of the raters were visual design professionals, including designers, art directors, illustrators, artists, and photographers. The remainder comprised non-professional image creators and respondents who did not specify an occupation. To test whether expertise influenced outcomes, BTD rankings were computed separately for professionals (20,900 judgments) and all other respondents (18,400 judgments).
Identical system rankings emerged across both groups, though visual design professionals showed greater discriminative power. Win probability spread was 21.9% wider among professionals, with stronger separation between leading systems such as Exactly.ai and GPT Image 1 and weaker performers like Firefly Image 4 Ultra. More decisive judgments from professionals increased tier separation while preserving the same overall ordering seen among non-expert users.
Expanding the benchmark
Future iterations could extend evaluation in several directions:
Multi-image consistency: Measuring whether systems maintain style coherence across multiple generations.
Style family expansion: Incorporating commercial photography styles (product, lifestyle, editorial) alongside additional illustration aesthetics to broaden applicability.
Production complexity: Testing style preservation under real-world constraints like compositional requirements, text placement, and multi-subject scenes.
Expanding the benchmark would bring evaluation closer to real production conditions and clarify which systems can reliably support comprehensive brand identities.
Helping AI stay on brand
VIST reframes image model evaluation around brand fidelity rather than surface quality. The results highlight clear differences in production readiness and provide a grounded reference point for teams deciding whether AI-generated assets can meet brand standards.
Benchmark your model against market alternatives using the Toloka self-service platform and run the same evaluations on your own systems.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.