← Blog
/

The role of a data annotator in machine learning
High-quality human expert data. Now accessible for all on Toloka Platform.
The two synonymous terms “data annotator” and “data labeler” seem to be everywhere these days. But who is a data annotator? Many know that annotators are somehow connected to the fields of Artificial Intelligence (AI) and Machine Learning (ML), and they probably have important roles to play in the data labelling market. But not everyone fully understands what data labelers actually do. If you want to find out once and for all is data annotation a good job, especially if you’re considering a data labeling career – read on!
What is data annotation and why is data important?
Data annotation is the process of labeling elements of data (images, videos, text, or any other format) by adding contextual information which ML models can learn from. It helps ML models understand what exactly is important about each piece of data.
To fully grasp and appreciate everything data labelers do and what data annotation skills they need, we need to start with the basics by explaining data annotation and data usage in the field of machine learning. So, let’s begin with something broad to give us appropriate context and then dive into more narrow processes and definitions.
Data comes in many different forms – from images and videos to text and audio files – but in almost all cases, this data has to be processed to render itself usable. What it means is that this data has to be organized and made “clear” to whomever is using it, or as we say, it has to be “labeled”.
If, for example, we have a dataset full of geometric shapes (data points), to prepare this dataset for further use, we need to make sure that every circle is labeled as “circle,” every square as “square,” every triangle as “triangle,” and so on. This turns a random collection of items in the dataset into something with a system that can be picked up and inserted into a real-life project, a bunch of training data for a machine learning algorithm. The opposite of it is “raw” data, which is essentially a mass of disorganized information. And this is where the data annotator role comes in: these people turn “raw data” into “labeled data”.
Data annotation in machine learning models
This processing and organization of raw unstructured data – “data labeling” or “data annotation” – is even more important in business. When your business relies on data in any way (which is becoming more and more common today), you simply cannot afford for your data to be messy, or else your business will likely run into serious troubles or fail altogether.
Labeled data can assist many different companies, both big and small, whether these companies rely on ML technologies, or have nothing to do with AI. For instance, a real-estate developer or a hotel executive may need to make an expansion decision about building a new facility. But before investing, they need to perform an in-depth analysis in order to understand what types of accommodation get booked, how quickly, during which months, and so on. All of that implies highly organized and “labeled” data (whether it’s called that or not) that can be visualized and used in decision-making.
A training algorithm (also referred to as machine learning algorithm or ML model) is basically clever code written by software engineers that tells an AI solution how to use the data it encounters. The process of training machine learning models involves several stages that we won’t go into right now.
But the main point is this: each and every machine learning model requires adequately labeled data at multiple points in its life cycle. And normally not just some high-quality training data – lots of it! Such ground truth data is used to train an ML model initially, as well as to monitor that it continues to produce accurate results over time.
AI-based applications: why do we need a machine learning model?
Today, AI products are no longer the stuff of fiction or even something niche and unique. Most people use AI products on a regular basis, perhaps without even realizing that they’re dealing with an ML-backed solution. Probably one of the best examples is when we use Google Translate or a similar web service.
Think ML models, think data annotations, think training and test data. Feel like asking Siri or Alexa something? It’s the same deal again with virtual assistants: training algorithms, labeled data. Driving somewhere and having an online map service lay out and narrate a route for you? Yes, you guessed it!
Some other examples of disrupting AI technologies include self-driving vehicles, online shopping and product cataloging (e-commerce), cyber security, moderating reviews on social media, financial trading, legal assistance, interpretation of medical results, nautical and space navigation, gaming, and even programming among many others. Regardless of what industry an AI solution is made for or what domain it falls under (for instance, Computer Vision that deals with visual imagery or Natural Language Processing/NLP that deals with speech) – all of them imply continuous data annotation at almost every turn. And, of course, that means having people at hand who can carry out human powered data annotation.
Data annotation methods and types
Data annotation can be carried out in a number of ways by utilizing different “approaches”:
Data can be labeled by human annotators.
It can be labeled synthetically (using machine intelligence).
Or it can be labeled in a “hybrid” manner (having both human and machine features).
As of right now, human-handled data annotation remains the most sought-after approach, because it tends to deliver the highest quality datasets. ML processes that involve human-handled data annotation are often referred to as being or having “human-in-the-loop pipelines.”
When it comes to the data annotation process, methodologies of acquiring manually annotated training data differ. One of them is to label the data “internally,” that is, to use an “in-house” team. In this scenario, as usual, the company has to write code and build an ML model at the core of their AI product. But then it also has to prepare training datasets for this machine learning model, often from scratch. While there are advantages to this setup (mainly having full control over every step), the main downside is that this track is normally extremely costly and time-consuming. The reason is that you have to do everything yourself, including training your staff, finding the right data annotation software, learning quality control techniques, and so on.
The alternative is to have your data labeled “externally,” which is known as “outsourcing.” Creators of AI products may outsource to individuals or whole companies to carry out their data annotation for them, which may involve different levels of supervision and project management. In this case, the tasks of annotating data are tackled by specialized groups of human annotators with relevant experience who often work within their chosen paradigm (for example, transcribing speech or working with image annotation).
In a way, outsourcing is a bit like having your own external in-house team that you hire temporarily, except that this team already comes with its own set of data annotation tools. While appealing to some, this method can also be very expensive for AI product makers. What’s more, data quality can often fluctuate wildly from project to project and team to team; after all, the whole data annotation process is handled by a third party. And when you spend so much, you want to be sure you’re getting your money’s worth.
Crowdsourced data annotation
There’s also a type of large-scale outsourcing known as “crowdsourcing” or “crowd-assisted labeling,” which is what we do at Toloka. The logic here is simple: rather than relying on fixed teams of data labelers with fixed skill sets (who are often based in one place), instead, crowdsourcing relies on a large and diverse network of data annotators from all over the globe.
In contrast to other data labeling methodologies, annotators from the “global crowd” choose what exactly they’re going to do and when exactly they wish to contribute. Another big difference between crowdsourcing and all other approaches, both internal and external, is that “crowd contributors” (or “Tolokers” as we call them) do not have to be experts or even have any experience at all. This is possible because:
A short, task-oriented training course takes place before each project in labeling data – only those who perform test tasks at a satisfactory level are allowed to proceed to actual project tasks.
Crowdsourcing utilizes advanced “aggregation techniques,” which means that it’s not so much about individual efforts of crowd contributors, but rather about the “accumulated effort” of everyone on the data annotation project.
To understand this better, think of it as painting a giant canvas. While in-house or outsourced teams gradually paint a complete picture, relying on their knowledge and tenacity, crowd contributors instead paint a tiny brush stroke each. In fact, the same brush stroke in terms of its position on the canvas is painted by several contributors. This is the reason why an individual mistake isn’t detrimental to the final result. A “data annotation analyst” (a special type of ML engineer) then does the following:
They take each contributor’s input and discard any “noisy” (i.e., low-quality) responses.
They aggregate the results by putting all of the overlapping brush strokes together (to get the best version of each brush stroke).
They then merge different brush strokes together to receive a complete image. Voila – here’s our ready canvas!
Being a crowd contributor: what is data annotator job?
This methodology serves those who need annotated data very well, but it also makes data annotation a lot less tedious for human annotators. Probably the best thing about being a data annotator for a crowdsourcing platform like Toloka is that you can work any time you want, from any location you desire – it’s completely up to you. You can also work in any language, so speaking your native tongue is more than enough. If you speak English together with another language (native or non-native), that’s even better – you’ll be able to participate in more labeling projects.
Another great thing is that all you need is internet access and a device such as a smartphone, a tablet, or a laptop/desktop computer. Nothing else is required, and no prior experience is needed, because, as we've explained already, task-specific training is provided before every labeling project. Certainly, if you have expertise in some field, this will only help you, and you may even be asked to evaluate other contributors’ submissions based on your performance. What you produce may also be treated as a “golden” set (or “honeypot” as we say at Toloka), which is a high-quality standard that the others will be judged against.
All annotation tasks at Toloka are relatively small, because ML engineers decompose large labeling projects into more manageable segments. As a result, no matter how difficult the actual request to label data made by our client, as a crowd contributor, you’ll only ever have to deal with micro tasks. The main thing is following your instructions to the word. You have to be careful and diligent when you label the data. The tasks are normally quite easy, but to do them well, one needs to remain focused throughout the entire labeling process and avoid distractions.
Types of data annotation tasks
There are many different labeling tasks for crowd contributors to choose from, but they all fall into these two categories:
Online tasks (you complete everything on your device without traveling anywhere in person)
Offline tasks, also known as “field” or “feet-on-street” tasks (you travel to target locations to complete labeling assignments).
When you choose to participate in a field task, you’re asked to go to a specific location in your area (normally your town or your neighborhood) to complete a short on-site assignment. This assignment could involve taking photos of all bus stops in the area, monuments, or coffee shops. It can also be something more elaborate like following a specific route within a shopping mall to determine how long it takes or counting and marking benches in a park. The results of these tasks are used to improve web mapping services, as well as brick-and-mortar retail (i.e., physical stores).
Online assignments have a variety of applications, some of which we mentioned earlier, and they may include text, audio, video, or image annotation. Each ML application contains several common task formats that our clients (or “requesters” as we say at Toloka) often ask for.
Text annotation
Text annotation tasks usually require annotators to extract specific information from natural language data. Such labeled data is used for training NLP (natural language processing) models. NLP models are used in search engines, voice assistants, automated translators, parsing of text documents, and so on.
Text classification
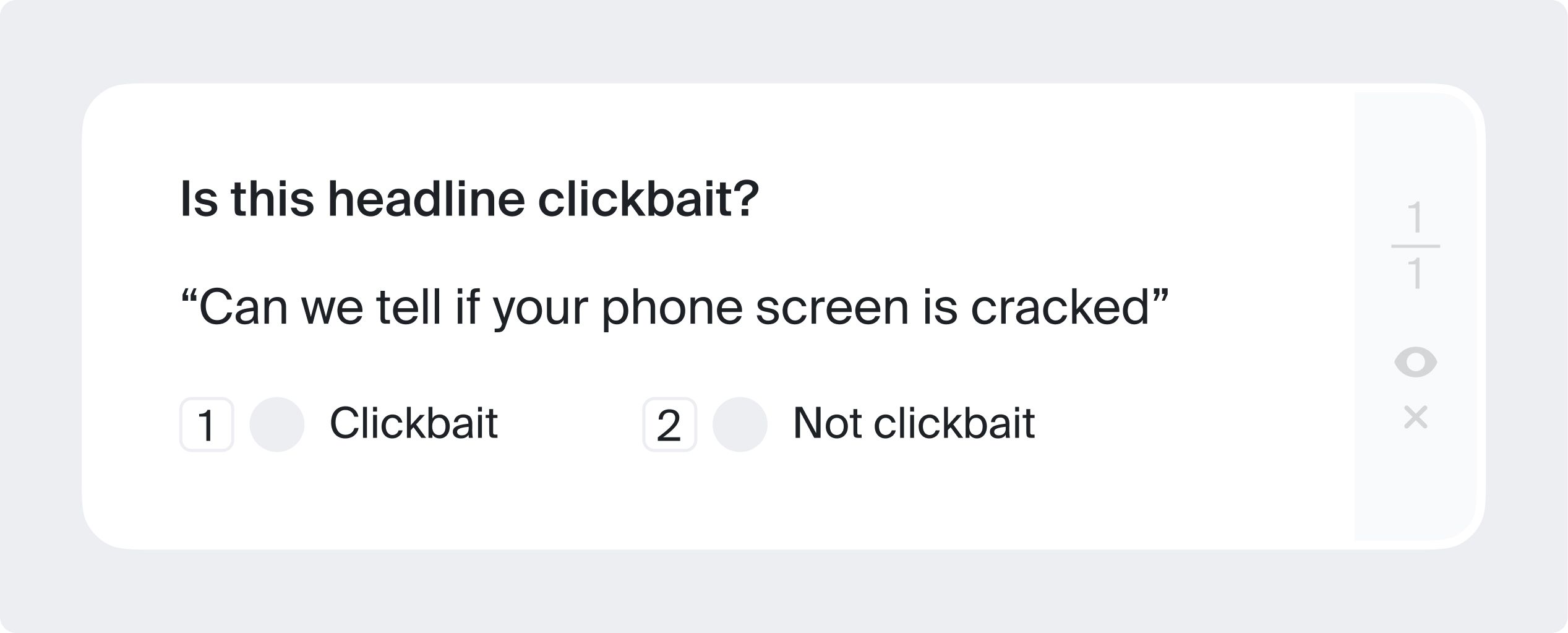
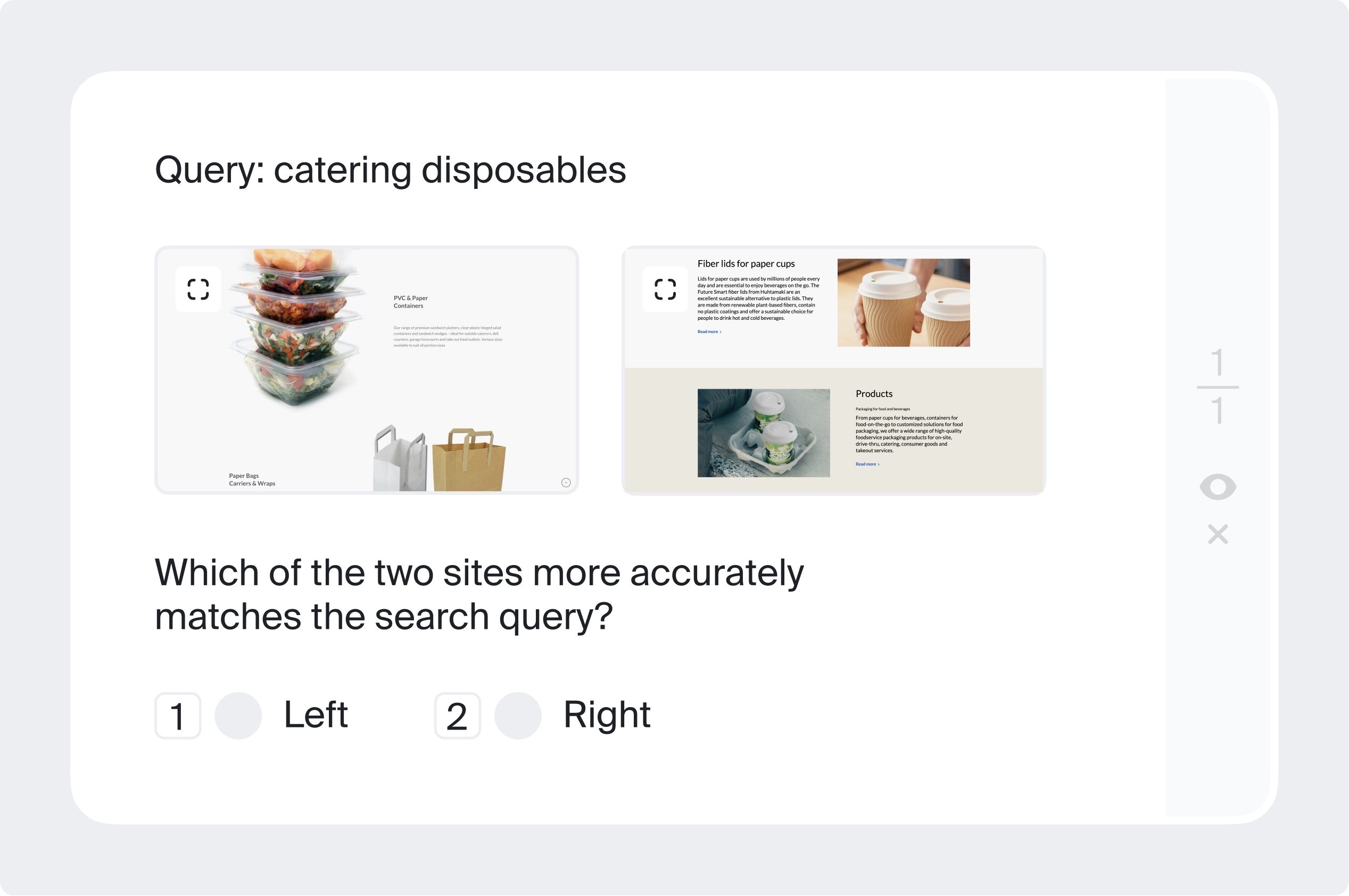
In such tasks (also called text categorization) you may need to answer whether the text you see matches the topic provided. For example, to see if a search query matches search engine results — such data helps improve search relevance. It can also be a simple yes/no questionnaire, or you may need to assign the text a specific category. For example, to decide whether the text contains a question or a purchase intent (this is also called intent annotation).
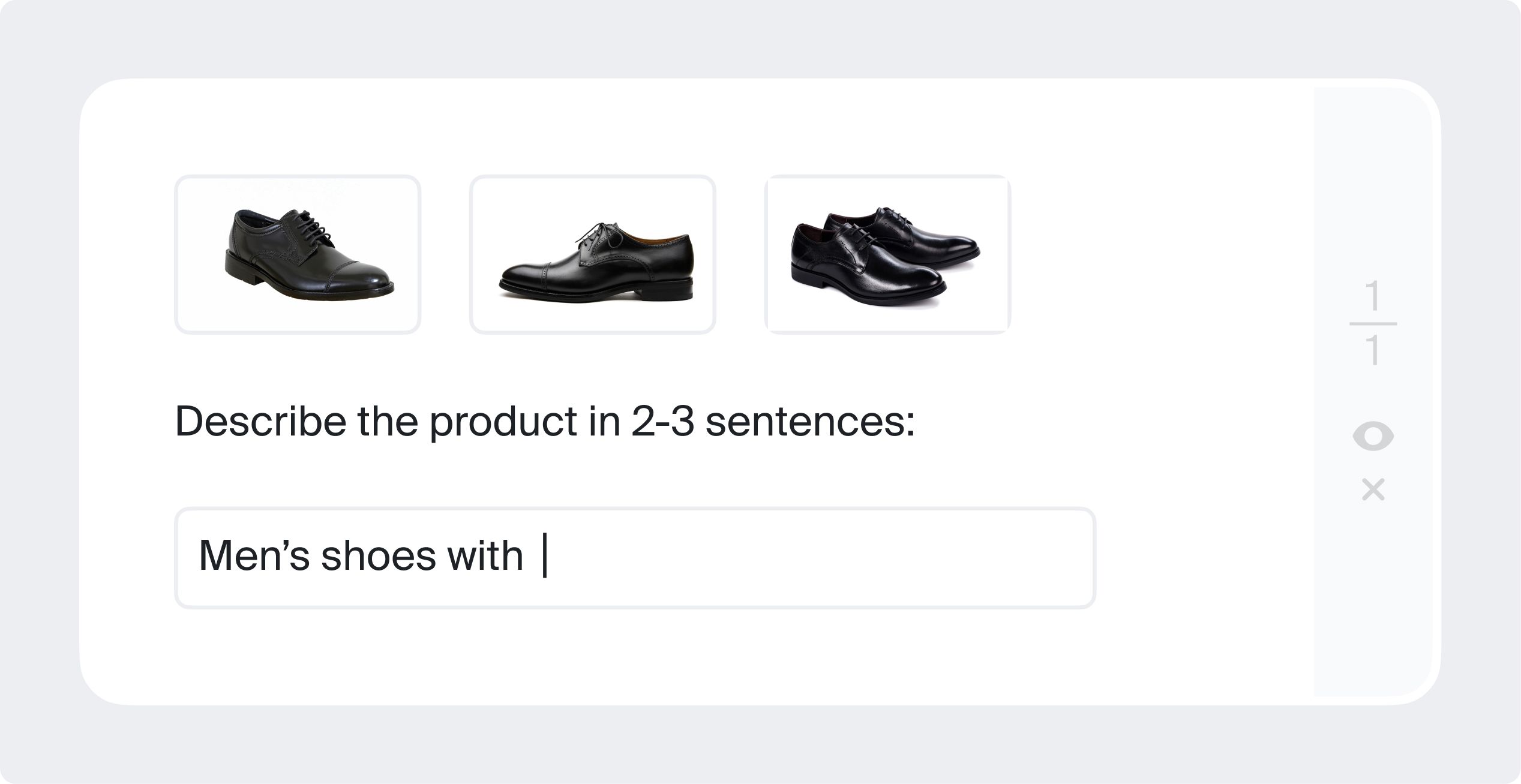
Text generation
In this type of text annotation, you may need to come up with your best description of an image/video/audio or a series of them (normally in 2-3 sentences).
Side-by-side comparison
You may need to compare two texts provided next to each other and decide which one is more informative or sounds better in your native tongue.
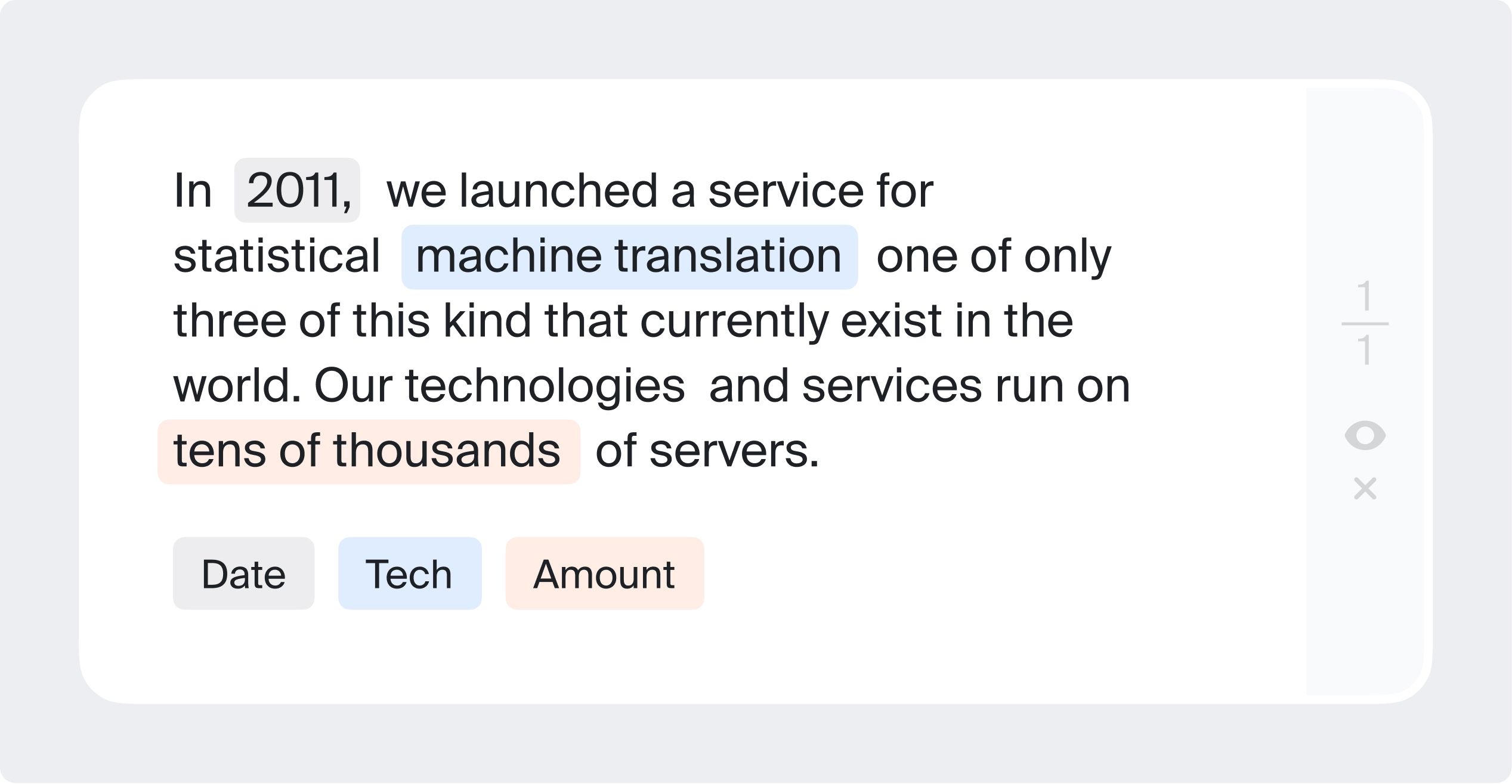
Named entity recognition
You may need to identify parts of text, classify proper nouns, or label any other entities. This type of text entity annotation is also called semantic annotation or semantic segmentation.
Sentiment Annotation
This is an annotation task which requires the annotator to determine the sentiment of a text. Such datasets are used in sentiment analysis, for example, to monitor customer feedback, or in content moderation. ML algorithms have to rely on human-labeled datasets to provide reliable sentiment analysis, especially in such a complicated area as human emotions.
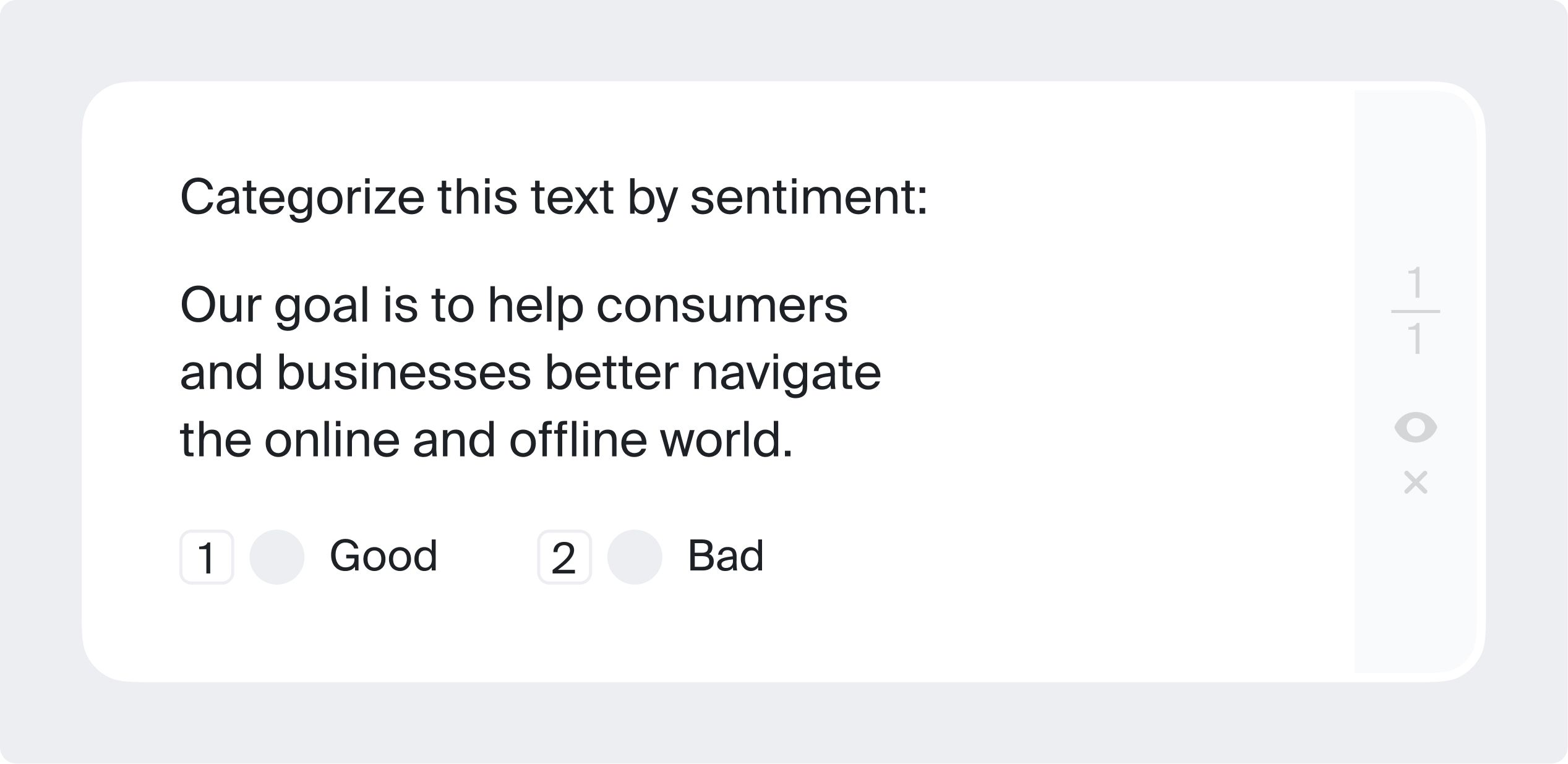
Image annotation
Training data produced by performing image annotation is usually used to train various computer vision models. Such models are used, for example, in self-driving cars or in face recognition technologies. Image annotation tasks include working with images: identifying objects, bounding box annotation, deciding whether an image fits a specified topic, and so on.
Object recognition and detection
You may be asked to select and/or draw the edges (bounding boxes) of certain items within an image, such as street signs or human faces. A computer vision model needs an image with a distinct object marked by labelers, so that it can provide accurate results.

Image classification
You may be asked whether what you see in an image contains something specific, such as an animal, an item of clothing, or a kitchen appliance.
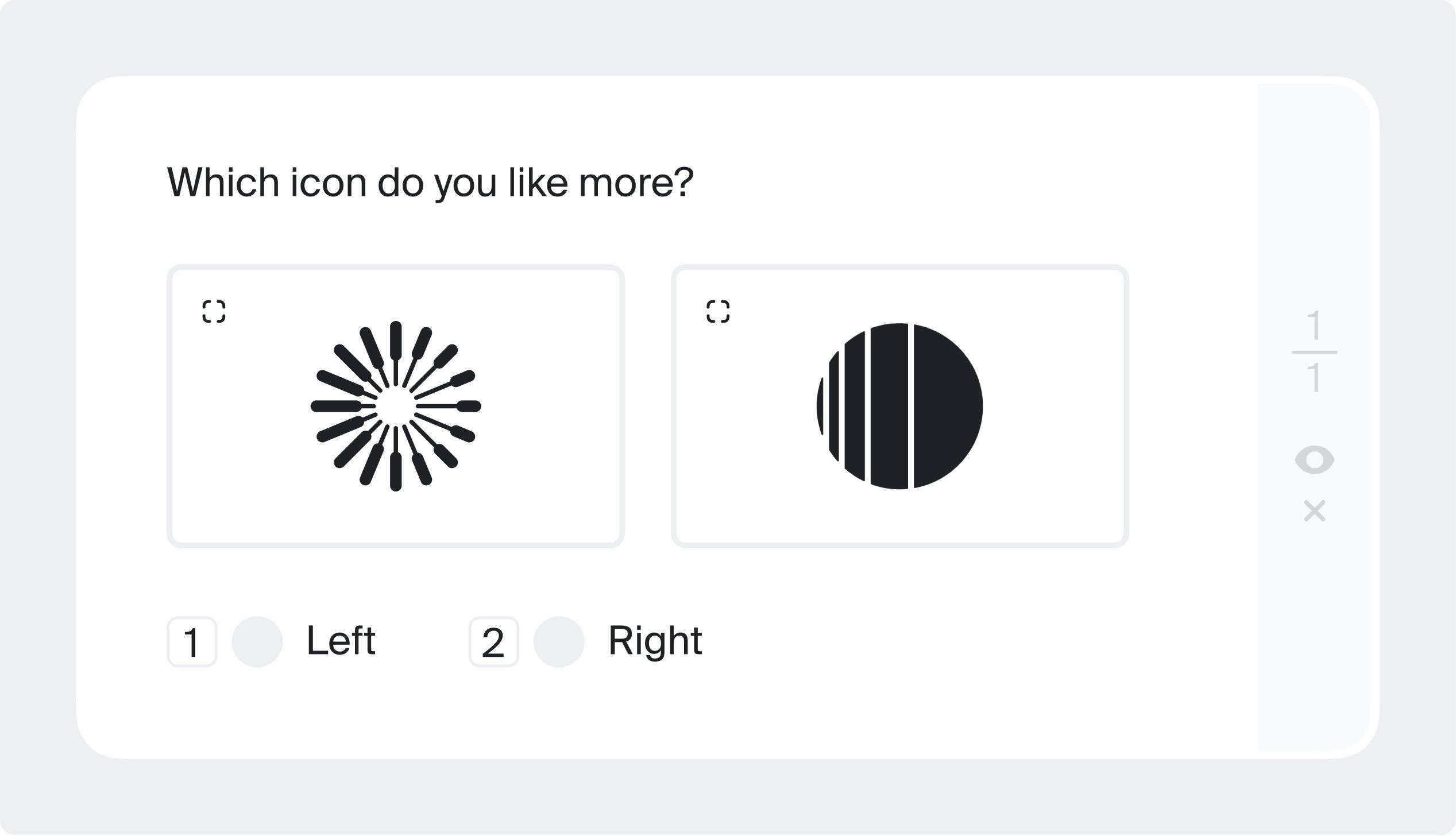
Side-by-side
You may be given two images and asked which one you think looks better, either in your own view or based on a particular characteristic outlined in the task. Later, these annotated images can be used to improve recommender systems in online shops.
Audio annotation
Audio classification
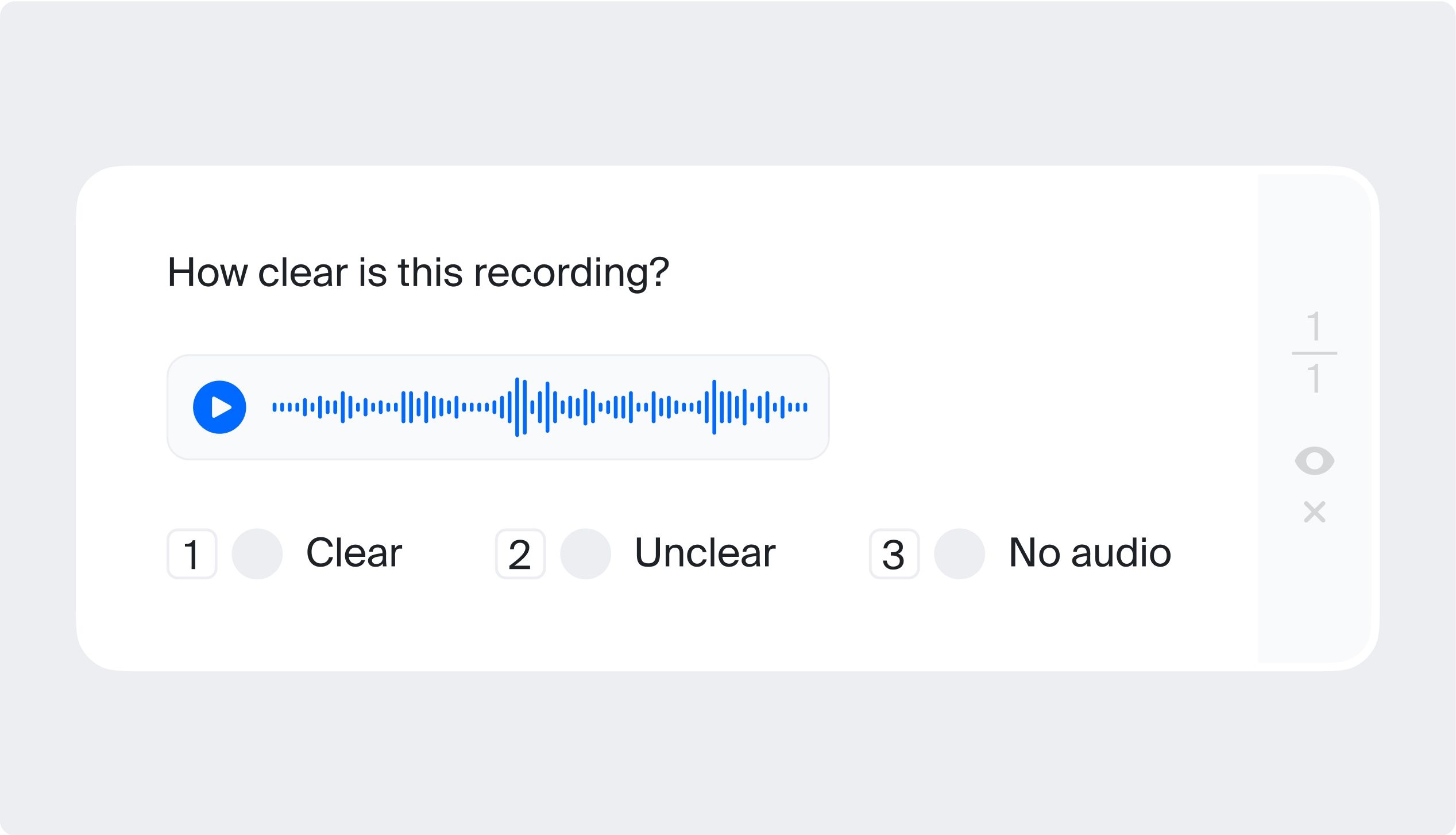
In this audio annotation task, you may need to listen to an audio recording and answer whether it contains a particular feature, such as a mood, a certain topic, or a reference to some event.
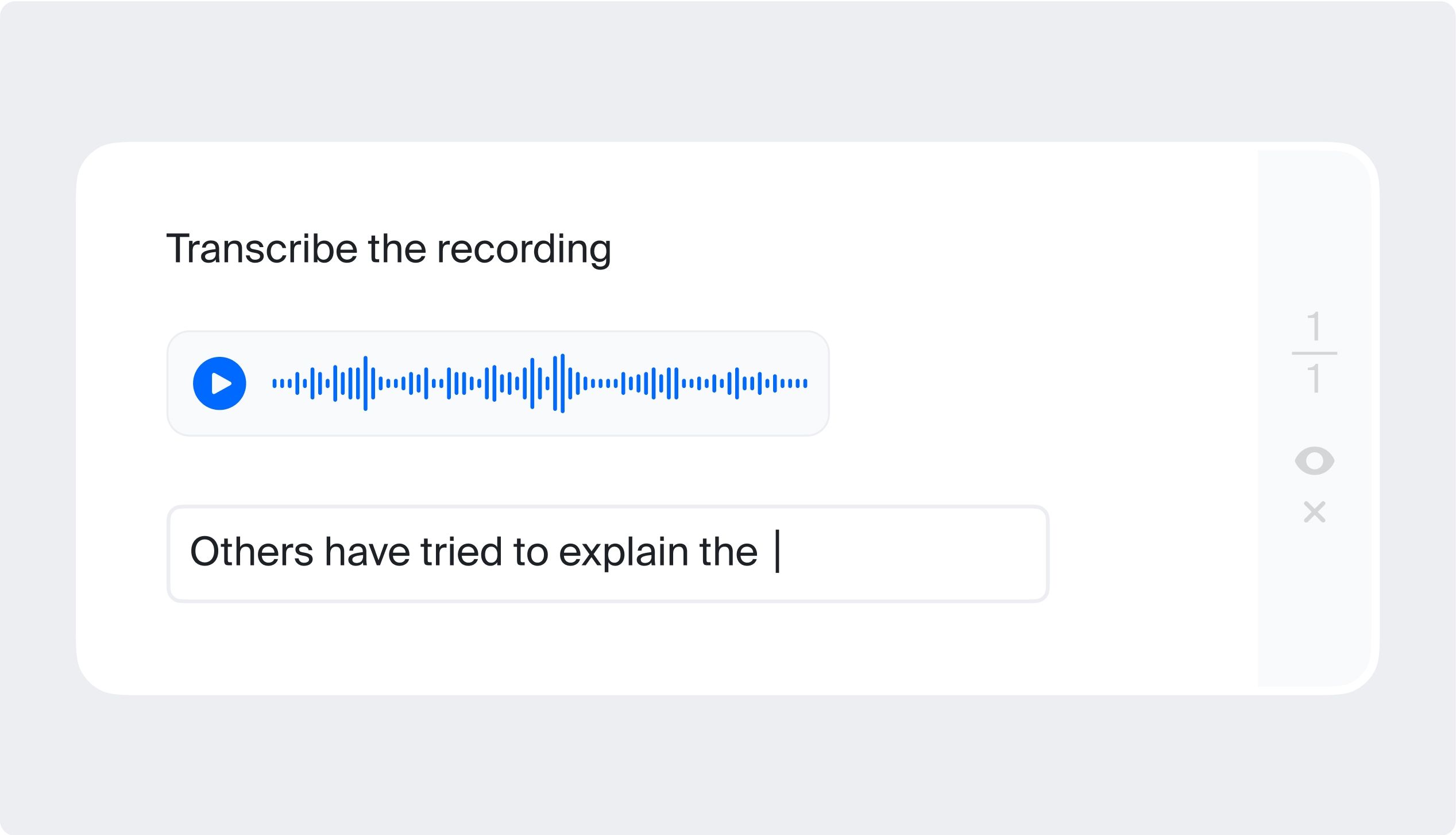
Audio transcription
You may need to listen to some audio data and write or “transcribe” what you hear. Such labeled data can be used, for example, in speech recognition technologies.
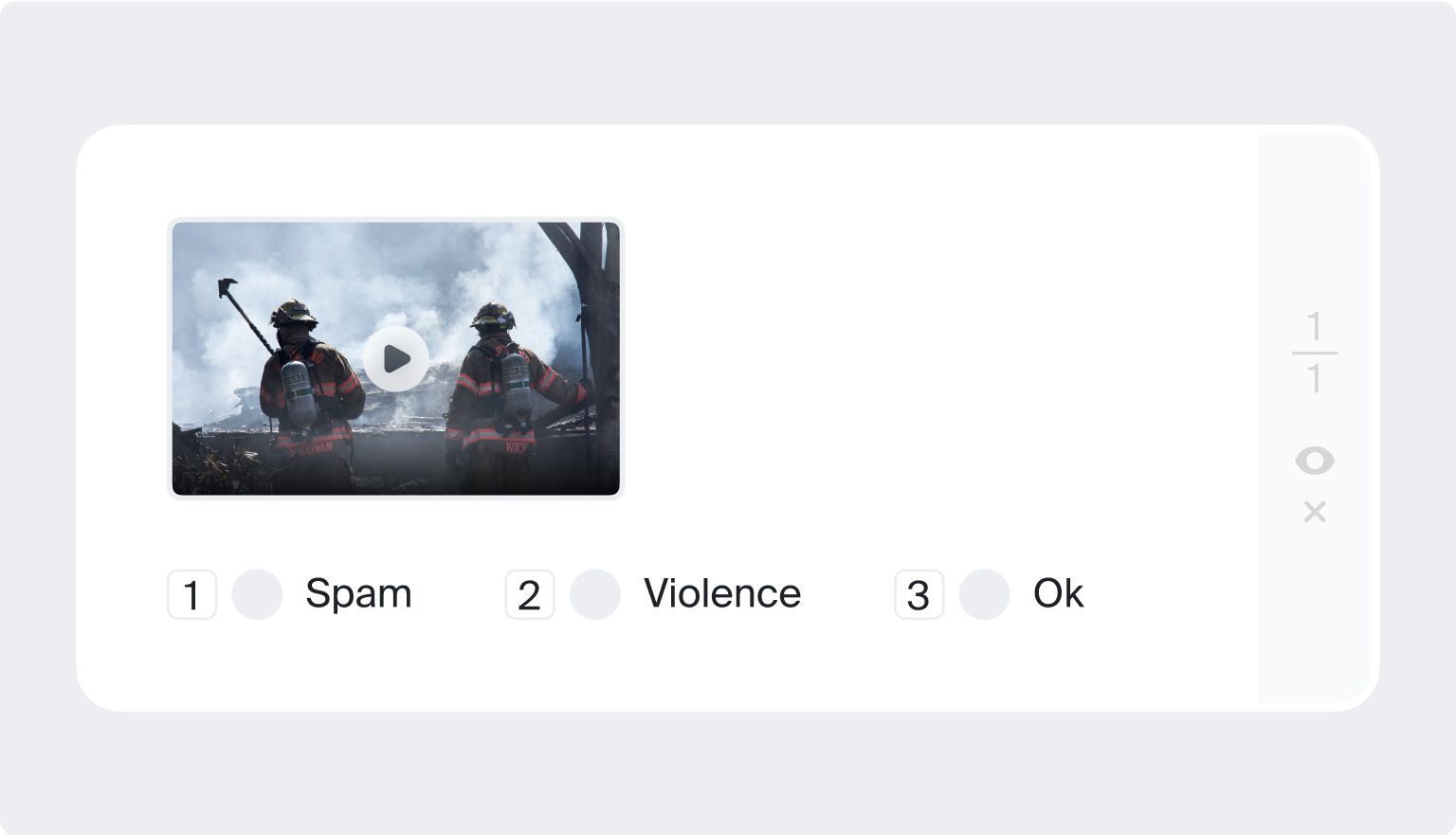
Video annotation
Image and video annotation tasks quite often overlap. It's common to divide videos into single frames and annotate specific data in these frames.
Video classification
You may have to watch a video and decide whether it belongs to a certain category, such as “content for children,” “advertising materials,” “sporting event,” or “mature content with drug references or nudity”.
Video collection
This is not exactly a video annotation task, but rather a data collection one. You may be asked to produce your own short videos in various formats containing specified features, such as hand gestures, items of clothing, facial expressions, etc. Video data produced by annotators is also often used to improve computer vision models.

Data annotation analysts and CSAs
When we explained how crowdsourcing works using our example of a painted canvas, we mentioned a “data annotation analyst” (who are also sometimes data scientists). Without these analysts, none of it is possible. This special breed of ML engineers specializes in processing and analyzing labeled data. They play a vital role in any AI product creation. In the context of human-handled labeling, it’s precisely data annotation analysts who “manage” human labelers by providing them with specific tasks. They also supervise data annotation processes and – together with more colleagues – feed all of the data they receive into training models.
It’s up to data annotation analysts to find the most suitable data annotators to carry out specific labeling tasks and also set quality control mechanisms in place to ensure adequate quality. Crucially, data annotation analysts should be able to clearly explain everything to their data annotators. This is an important aspect of their job, as any confusion or misinterpretation at any point in the annotation process will lead to improperly labeled data and a low-quality AI product.
At Toloka, data annotation analysts are known as Crowd Solutions Architects (CSAs). They differ from other data annotation analysts in that they specialize in crowdsourced data and human-in-the-loop pipelines involving global crowd contributors.
Become a data annotator
As you can see, labeling data has an essential role to play in both AI-based products and modern business in general. Without high-quality annotated data, an ML algorithm cannot run and AI solutions cannot function. As our planet continues to go through exceedingly more digitization, traditional businesses are beginning to show their need for annotated data, too.
With that in mind, human annotators – people who annotate data – are in high demand all over the world. What’s more, crowdsourced data annotators are at the forefront of the global AI movement with the support they provide. If you feel like becoming a Toloker by joining our global crowd of data annotators, follow this link to sign up and find out more. As a crowd contributor at Toloka, you’ll be able to complete micro tasks online and offline whenever it suits you best.
About Toloka
Toloka is a European company based in Amsterdam, the Netherlands that provides data for Generative AI development. Toloka empowers businesses to build high quality, safe, and responsible AI. We are the trusted data partner for all stages of AI development from training to evaluation. Toloka has over a decade of experience supporting clients with its unique methodology and optimal combination of machine learning technology and human expertise, offering the highest quality and scalability in the market.
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.