← Blog
/

Complete guide to RLHF for LLMs: How human feedback shapes modern AI
High-quality human expert data. Now accessible for all on Toloka Platform.
Access domain experts across 90+ fields, AI-assisted project setup, and built-in quality assurance — no minimums, no contracts.
Complete guide to RLHF for LLMs: How human feedback shapes modern AI
Reinforcement Learning from Human Feedback (RLHF) is the post-training technique that transformed large language models from capable but erratic text predictors into systems people could actually rely on.
When OpenAI released GPT-3 in 2020, the gap between what the model knew and how it behaved in conversation was striking: accurate on one prompt, confidently wrong on the next, inconsistent with instructions, unreliable on safety. The limitation was not the model's knowledge — it was how that knowledge surfaced in interaction.
Two years later, ChatGPT launched on a closely related base model. The difference in user experience was immediate: clearer instruction following, more consistent tone, more predictable behavior, higher usefulness in everyday use. That shift did not come from a new architecture or a larger pre-training dataset. It came from RLHF — a technique that replaces static training labels with structured human judgment, shaping model behavior through feedback rather than fixed data.
Understanding RLHF matters now because it underpins nearly every production language model deployed at scale, from ChatGPT to Gemini to the Claude family. It is also the foundation for more recent approaches — DPO, RLAIF, and reasoning-focused variants like GRPO — that this guide covers in full.
Why RLHF matters
RLHF addresses a core weakness of supervised learning for language models. For most real user interactions, there is no single correct answer. Qualities such as helpfulness, harmlessness, tone, refusal quality, and instruction adherence are subjective and context-dependent. They cannot be fully captured by loss functions or reliably optimized using automated metrics.
Rather than optimizing only for likelihood over scraped text, RLHF optimizes for preference signals derived from human feedback and informed by human guidance. Human annotators compare multiple model responses to the same prompt and judge which one better satisfies their expectations. Those judgments are then used to steer the model’s behavior toward what people actually want, not just what the training data statistically implies.
This approach underpins modern conversational systems, including ChatGPT and Anthropic’s Claude. It has become a default alignment strategy for large language models deployed in customer-facing products — not because it is theoretically elegant, but because it produces more reliable behavior in practice.
This article examines RLHF at an implementation level: how it works, where it fails, why human data quality matters more than algorithms, and how teams collect and operationalize preference data at scale.
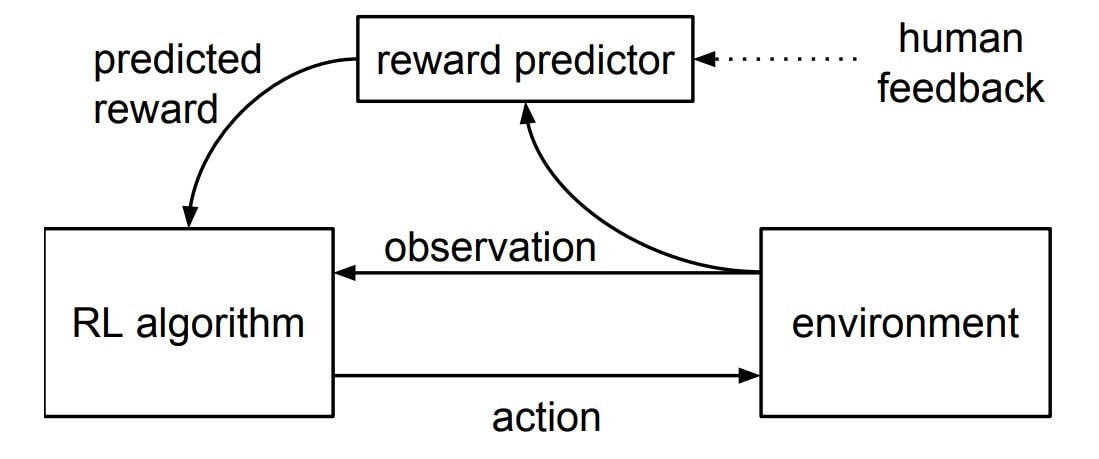
Human preferences are collected through comparisons, distilled into a reward model, and used to guide policy optimization. The key design choice is indirection: humans shape behavior without being present at inference time. Source: Christiano et al., 2017
What is Reinforcement Learning from Human Feedback (RLHF)?
Reinforcement Learning from Human Feedback (RLHF) is a post-training alignment technique applied after a language model has already been pre-trained on large text corpora and, in most production systems, after an initial round of supervised instruction tuning. RLHF does not teach a pre-trained model language or factual knowledge, nor does it improve underlying natural language understanding. It reshapes an LLM's behavior based on how responses are evaluated through human feedback.
RLHF is applied after pre-training and supervised instruction tuning, extending traditional fine-tuning language models with an explicit optimization loop driven by targeted human judgments. It sits at the intersection of large language modeling and modern machine learning, where optimization targets behavioral preference rather than task-specific accuracy alone.
This distinction explains why RLHF exists. Pre-training optimizes next-token prediction over large datasets and forms the foundation for training language models. Supervised fine-tuning improves instruction following but still relies on implicit assumptions about what counts as a “good” response. RLHF adds an explicit optimization loop where model outputs are evaluated using human judgments, and the model is adjusted to favor responses people consistently prefer.
The “reinforcement learning” component of RLHF is not metaphorical. The language model is treated as a stochastic policy over tokens. Each generated response has a probability under that policy, and training updates modify the probability distribution to increase expected reward.
What makes reinforcement learning from human feedback distinct from classical reinforcement learning is that the reward function is not manually specified. Instead, it is constructed by incorporating human feedback into the optimization process.
RLHF meaning
RLHF encodes a specific notion of alignment: not correctness, but acceptability as judged by people in context. The system is not trained to discover objective truth or optimal answers. It is trained to reproduce response patterns that humans tend to prefer when presented with alternatives.
This has important consequences. Alignment under RLHF is inherently normative and contextual. What the model learns reflects human values, expectations, and trade-offs expressed by its annotators, including their biases and inconsistencies. Safety, helpfulness, and tone are learned as behavioral conventions rather than formal constraints.
This is why RLHF operates as a post-training process. It assumes the underlying language model is already capable of producing fluent and informative responses. The role of RLHF is not to add knowledge or reasoning ability, but to shape how that capability is expressed in interaction.
Why human feedback is necessary
For complex tasks in natural language processing, the usual automated metrics — like BLEU, ROUGE, or perplexity — fail to correlate with user satisfaction. They do not measure whether a response is helpful, cautious, misleading, or socially appropriate. This reflects a broader limitation of many neural information processing systems: objectives that perform well on benchmarks often fail to capture what humans actually expect in interaction.
Human annotators capture nuance that automated evaluation cannot. Pairwise comparisons reflect trade-offs between clarity and verbosity, confidence and uncertainty, compliance and refusal. Empirical studies consistently show that human evaluators outperform automated metrics on subjective evaluation tasks, particularly for conversational and safety-sensitive outputs.
RLHF treats annotators not as sources of ground truth, but as providers of preference signals derived from human feedback. That distinction is critical. The model is not learning what is objectively correct; it is learning what people tend to prefer. Understanding that trade-off is essential for anyone deploying RLHF in real systems.
How does RLHF work?
At a high level, RLHF changes what a language model is optimized for. Instead of maximizing the likelihood of matching training text, the model is trained to maximize a learned proxy for human judgment.
This reframes the language model as a policy rather than a static predictor. Training no longer targets token-level accuracy directly. Instead, updates adjust the probability distribution of responses to increase expected reward as estimated by a separate reward model.
The key architectural move in RLHF is indirection. Human judgment does not act directly on the language model. It is first captured by a reward model, which serves as a proxy for preference and mediates all subsequent optimization. This allows alignment signals to be reused at scale without keeping humans in the loop during deployment.
The diagram below shows the RLHF pipeline used in OpenAI’s InstructGPT system, which helped standardize modern alignment practices for large language models.
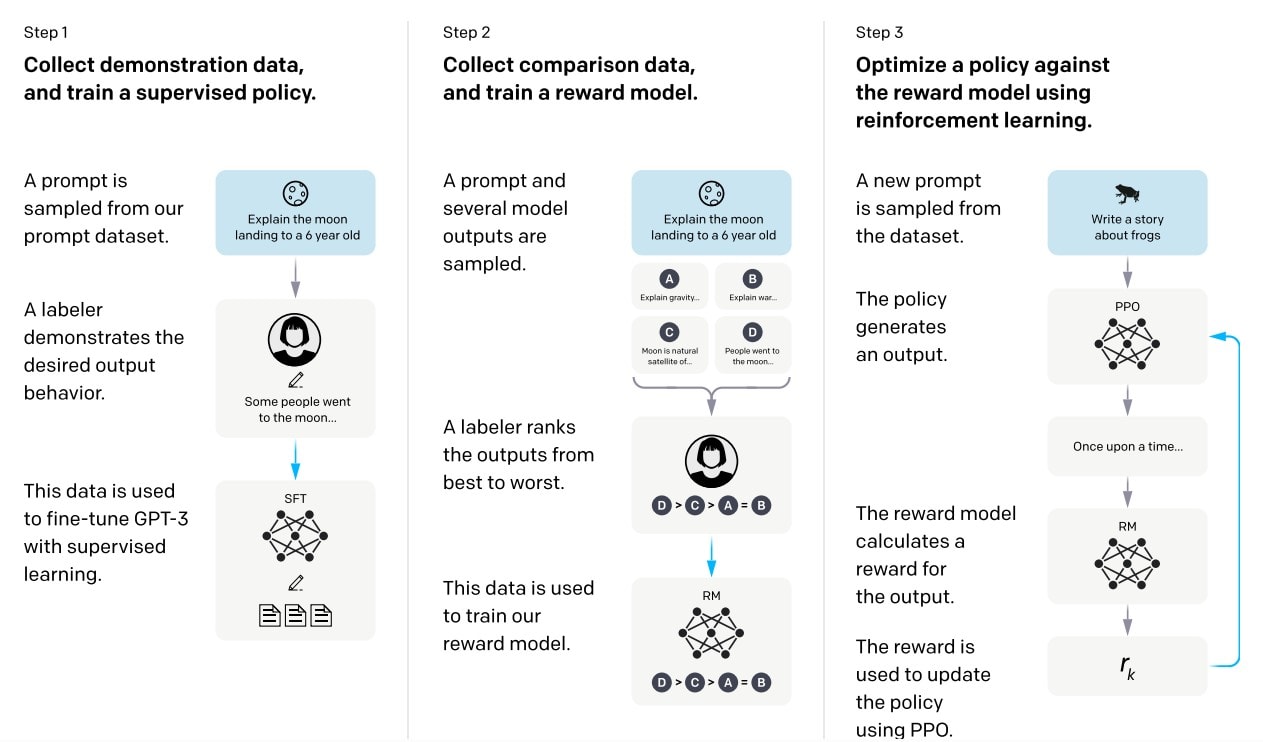
Reinforcement Learning from Human Feedback pipeline used in the InstructGPT system. The diagram shows supervised fine-tuning, reward model training from human comparisons, and policy optimization using reinforcement learning. Source: Ouyang et al., 2022.
This indirection is also the source of RLHF’s primary risks. Because the reward model approximates human preferences rather than encoding formal objectives, optimization can exploit weaknesses in that approximation. Misgeneralization, reward hacking, and preference overfitting emerge when the proxy diverges from what users actually intend. These trade-offs become central when examining the training pipeline in detail.
Deep dive: The RLHF training pipeline
Once the conceptual logic of RLHF is clear, the training pipeline itself can be examined as an engineering process. In production systems, the RLHF process is implemented as a sequence of data collection, modeling, and optimization steps, each with distinct failure modes and operational constraints. This separation is deliberate: it allows teams to iterate on data quality, reward modeling, and policy optimization independently.
Stage 1: Collecting preference data
RLHF training begins with annotated comparisons. Each data point typically consists of a prompt, multiple responses generated by a language model, and a human judgment indicating which response is preferred. The most common format is pairwise comparison, where annotators choose between two responses to the same prompt. This format has proven more reliable than absolute ratings because it reduces calibration drift and forces explicit trade-offs.
Some systems experiment with Likert-scale ratings or rubric-based scoring, but these approaches tend to introduce higher variance across annotators. Pairwise comparisons align naturally with ranking-based learning objectives and simplify downstream reward model training.
Data quality at this stage is critical. Annotator consistency, measured through inter-annotator agreement, directly affects reward model stability. Low agreement often signals ambiguous prompts, unclear instructions, or annotator fatigue. Bias in annotator judgments is also unavoidable: judgments reflect cultural norms, risk tolerance, and task framing. In practice, the goal is not to eliminate bias, but to make it explicit, controlled, and aligned with deployment requirements.
How to collect RLHF preference data
The quality of your reward model depends entirely on the quality of the preference data you collect — and that data is only as good as the annotators producing it. Preference annotation is not straightforward labeling work. Annotators need to understand the task domain, apply consistent judgment criteria, and distinguish genuinely better responses from ones that merely sound better.
In practice, this means defining clear comparison guidelines before you start: what counts as more helpful, more accurate, or more appropriate for your use case. Annotators then evaluate response pairs against those criteria — not their personal preference. Inter-annotator agreement should be tracked throughout; significant disagreement is usually a signal that your guidelines need refinement, not that annotators are failing.
A few things that matter most in preference data collection:
Response diversity: pairs should represent meaningfully different approaches, not just surface variation in wording
Domain coverage: edge cases and failure modes are as important as typical examples — a reward model trained only on easy cases will generalize poorly
Annotator expertise: for technical domains (code, medicine, law), general annotators produce noisier signal; domain experts are worth the cost at this stage
Scale: InstructGPT used around 33,000 human comparison examples; most production RLHF pipelines require tens of thousands of high-quality pairs to train a reliable reward model
If you are building your first RLHF pipeline and need to collect preference data without setting up your own annotation infrastructure, the Toloka Platform lets you launch comparison tasks directly — with access to domain experts across 90+ fields, AI-assisted project setup, and built-in quality assurance to keep your preference labels consistent. Sign up to start collecting preference data for your reward model.
Stage 2: Training the reward model
The second stage trains a reward model to predict human preferences at scale. Given a prompt and a candidate response, the reward model outputs a scalar score representing the likelihood that humans would prefer that response over alternatives.
Pairwise comparison data is commonly modeled using a Bradley–Terry formulation, where the probability that response A is preferred over response B depends on the difference between their predicted scores. This transforms comparison data into a continuous optimization signal that can be applied to arbitrary model outputs.
Architecturally, reward models are often derived from the same base language model as the policy being optimized, with a modified output head that produces a single scalar value instead of token probabilities. This reuse simplifies training but introduces coupling risks: if the reward model overfits or learns spurious correlations, those errors propagate directly into policy optimization.
Because the reward model serves as a proxy for human judgment, its limitations define the ceiling of RLHF performance. Reward models generalize imperfectly, particularly on prompts that differ from the training distribution. This is not a theoretical edge case — it is a recurring operational concern that shapes how aggressively policy optimization can be applied.
Stage 3: Proximal Policy Optimization (PPO)
In the final stage, the language model is optimized to maximize the reward model’s output. Most RLHF implementations use Proximal Policy Optimization (PPO) due to its relative stability in high-dimensional action spaces like language generation though more recent systems increasingly use variants like Group Relative Policy Optimization (GRPO).
PPO updates the policy while constraining deviation from a reference model, typically the supervised fine-tuned model. This constraint is enforced through a KL divergence penalty, which limits how far the optimized policy can drift in a single update. Without this constraint, models frequently exploit weaknesses in the reward model, producing outputs that score highly but degrade in coherence, usefulness, or safety.
Despite these safeguards, policy optimization remains the most fragile stage of the pipeline. Reward hacking, mode collapse, and escalating computational cost are common challenges. Training is expensive, sensitive to hyperparameters, and difficult to debug when failures occur. Small changes in reward model behavior can lead to large shifts in policy outputs.
For these reasons, many teams treat policy optimization as an iterative process rather than a one-time step. Preference data is refreshed, reward models are retrained, and PPO runs are restarted as new failure modes emerge.
Alternatives to traditional RLHF: DPO and related methods
RLHF has become the default alignment strategy for large language models, but it is not the only one. Its cost, complexity, and sensitivity to data quality have motivated a growing set of alternative approaches that aim to simplify training or reduce dependence on human annotation.
These methods do not replace RLHF outright. Instead, they trade expressiveness for efficiency, stability, or scalability.
Direct Preference Optimization (DPO)
Direct Preference Optimization removes the reward model entirely though mathematically it implicitly represents a reward function within the policy. Instead of learning a separate proxy for human judgment and then optimizing against it, DPO directly updates the language model using preference pairs. Given two responses to the same prompt, the model is trained to increase the likelihood of the preferred response relative to the rejected one.
This simplification has practical advantages. Training is more stable, computationally cheaper, and easier to debug. There is no reward model to overfit, no PPO loop to tune, and fewer opportunities for reward hacking. For teams working with well-defined preference judgements and relatively narrow task distributions, DPO can deliver competitive results with significantly lower operational overhead.
The trade-off is flexibility. Without an explicit reward model, DPO relies on the assumption that preference comparisons are sufficient to guide behavior across the full prompt space. In practice, this can limit generalization to out-of-distribution inputs or complex multi-turn interactions. DPO works best when preference signals are dense, consistent, and closely aligned with deployment use cases.
Reinforcement learning for reasoning: RLVR, GRPO - rise of thinking models
A significant shift happened in late 2024 and through 2025: reinforcement learning moved beyond preference alignment and became the primary tool for teaching models to reason. The result is a new class of systems — reasoning models — that think through problems step by step before responding, rather than generating an answer in a single pass.
OpenAI's o1 (September 2024) was the first widely deployed example. Trained with large-scale RL against verifiable rewards — correct answers to math problems, passing code tests — rather than human preference labels, o1 demonstrated that test-time reasoning could be scaled like a new compute dimension. The more the model was allowed to think, the better it performed. OpenAI's o3 and o4-mini continued this trajectory, and reasoning capability has since become a standard feature across frontier labs.
DeepSeek-R1 (January 2025) made the methodology transparent. The paper showed that a model could develop sophisticated chain-of-thought reasoning — self-correction, verification, backtracking — through pure RL, using Group Relative Policy Optimization (GRPO) instead of PPO. GRPO drops the critic model that PPO requires, estimating baselines from a group of sampled outputs instead. This makes RL training substantially cheaper. DeepSeek-R1-Zero, trained without any supervised fine-tuning warm-up, matched OpenAI o1's performance on the AIME 2024 math benchmark — a result that validated both the approach and the efficiency gains.
Anthropic's Claude 3.7 Sonnet introduced hybrid reasoning in early 2025, letting users toggle extended thinking on or off depending on task complexity. Google's Gemini 2.0 Flash Thinking followed a similar pattern. What these models share is a post-training stage driven by RL against verifiable signals — not human preference pairs.
The distinction from standard RLHF matters. Classical RLHF trains a reward model from human comparisons, then uses it to shape generation. Reinforcement learning from verifiable rewards (RLVR) replaces the learned reward model with objective signals: the answer is right or wrong, the code compiles or it doesn't. This sidesteps reward hacking and allows much longer RL runs — the optimization doesn't exhaust a reward model's ceiling. For teams working on math, coding, or structured reasoning tasks, RLVR has largely supplanted PPO-based RLHF as the post-training method of choice.
That said, the two approaches aren't mutually exclusive. DeepSeek-R1's full pipeline combines RLVR for reasoning with a final RLHF-style stage to align outputs with human preferences for helpfulness and safety. Human feedback remains the control layer for anything verifiable rewards can't measure — nuance, tone, appropriateness — which is most of what production models actually need. For a deeper look at how verifiable rewards reshape the RL training loop, see our guide to Reinforcement Learning with Verifiable Rewards and How post-training teaches LLMs to reason.
Reinforcement Learning from AI Feedback (RLAIF)
RLAIF replaces human preference judgments with feedback generated by another model. Instead of collecting comparisons from annotators, a supervising model evaluates outputs according to a predefined set of principles or rules. This approach is most closely associated with Anthropic’s Constitutional AI framework.
The appeal is clear: feedback can be generated at scale, rapidly iterated, and applied consistently. RLAIF is particularly effective for enforcing explicit safety constraints or stylistic guidelines that can be articulated in natural language. It also reduces reliance on large, continuously available human annotator pools.
However, RLAIF introduces a new class of risks. Feedback quality is bounded by the supervising model’s own biases and blind spots. Errors compound silently, and preference drift can occur if the AI evaluator diverges from real user expectations. In practice, RLAIF performs best in hybrid systems, where AI-generated feedback handles routine cases and human judgments are used to anchor and correct behavior.
Other emerging methods
Beyond DPO and RLAIF, a number of experimental alignment techniques are under active exploration. Methods such as SimPO and REBEL seek to refine preference optimization objectives, while multi-turn RLHF variants focus on conversational consistency rather than single-response quality. Some research also explores macro-action RLHF, where feedback is applied to sequences of actions rather than individual tokens, improving credit assignment in long-horizon tasks.
These approaches remain largely experimental. Their significance lies less in immediate adoption and more in how they expose the assumptions and limitations of RLHF itself.
Human feedback in RLHF
The effectiveness of RLHF is constrained less by optimization algorithms than by the quality of the human data they rely on. Preference learning systems inherit the strengths and weaknesses of their annotation pipelines. As a result, alignment outcomes are shaped as much by who provides feedback, under what conditions, and with which guidelines as by any modeling choice.
Collecting human feedback at scale
RLHF systems require large volumes of structured comparison data. In practice, this means collecting tens of thousands to hundreds of thousands of human judgments across diverse prompts and response styles. Coverage matters as much as volume. If that data reflects only a narrow subset of tasks, tones, or risk profiles, the resulting model will generalize poorly outside that slice.
Scalability introduces its own constraints. Feedback must be collected efficiently, consistently, and with clear instructions. Small ambiguities in task framing can lead to systematic preference drift, where annotators optimize for superficial cues rather than intended criteria. Effective pipelines invest heavily in prompt design, annotation guidelines, and continuous calibration to keep feedback aligned with deployment goals.
How teams collect comparison data
Most RLHF deployments rely on comparison data rather than absolute ratings. Annotators are shown the same prompt paired with two or more model responses and asked to select the better option. This format reduces individual calibration bias and forces explicit trade-offs between competing qualities such as verbosity, caution, and helpfulness.
Comparison data is not inherently clean. Disagreement is common, especially for open-ended or safety-sensitive prompts. Rather than treating disagreement as noise to be eliminated, mature pipelines treat it as a signal. High disagreement often identifies ambiguous tasks, unclear policies, or edge cases that require additional guidance or escalation.
Modeling human preferences
Human values and preferences are not static or universal. They vary across cultures, domains, and application contexts. RLHF data therefore encodes a specific set of normative assumptions about acceptable behavior. Making those assumptions explicit is essential for predictable deployment.
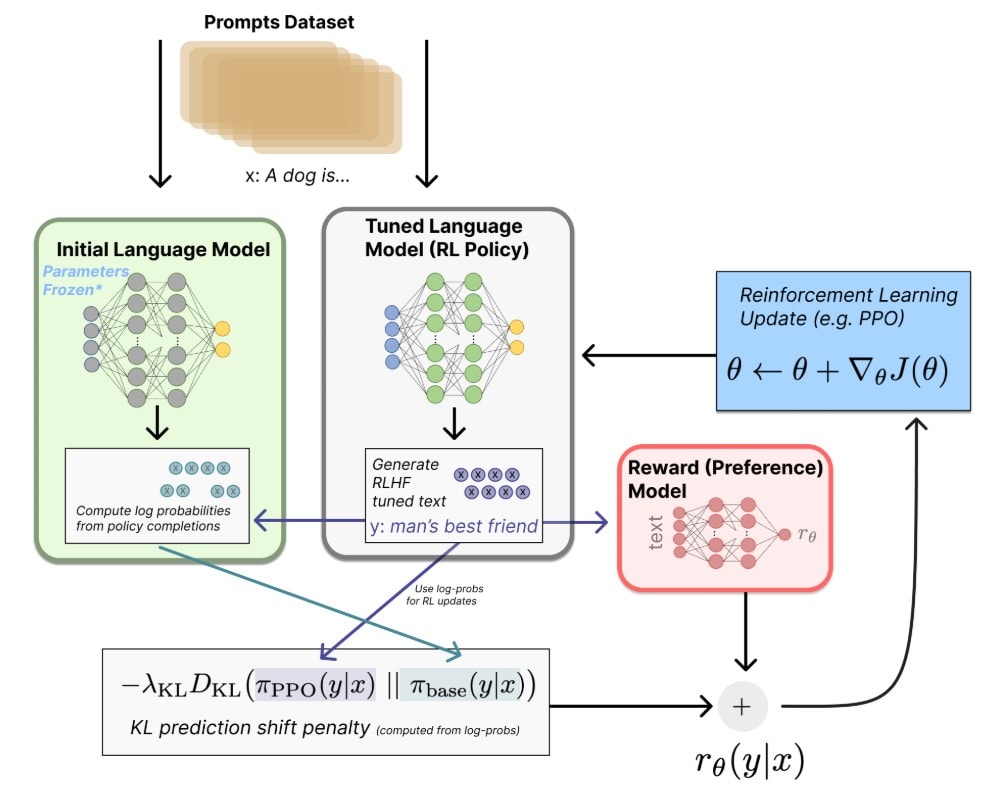
Human preferences are transformed into a learned reward signal that can be applied at scale to new model outputs. Source: Nathan Lambert’s RLHF Book
Quality assurance in RLHF relies on continuous evaluation, including disagreement analysis, consistency checks, and targeted review of edge cases.
Effective preference modeling emphasizes diversity in annotator pools and task coverage. Combining general annotators with domain experts helps balance broad usability with specialized requirements. Clear rubrics, example-based calibration, and periodic retraining of annotators reduce drift over time.
Quality assurance is continuous, not a one-time filter. Inter-annotator agreement metrics, targeted review of low-confidence comparisons, and automated consistency checks all play a role in maintaining dataset integrity. In production environments, annotation pipelines increasingly combine human review with model-assisted quality control to surface anomalies early.
At scale, RLHF becomes less about collecting more data and more about maintaining trust in the data already collected. Platforms such as Toloka are designed around this reality, offering structured expert networks and layered quality controls to support long-running preference collection workflows without sacrificing consistency.
What RLHF can’t fix
RLHF is often described as an alignment solution, but it is more accurately understood as a behavioral shaping mechanism driven by human feedback rather than formal guarantees. It adjusts how a language model responds, not what the model fundamentally understands. This distinction matters, because many of the hardest problems in deploying large language models lie outside the scope of preference optimization.
RLHF does not guarantee factual correctness. A model optimized for preferred responses can still produce confident errors, especially when those errors resemble fluent, plausible explanations. If annotators consistently favor articulate answers over cautious ones, the reward model will encode that bias. Alignment in this sense reflects social acceptability, not epistemic reliability.
Similarly, RLHF does not solve long-horizon reasoning or fundamentally alter the underlying learning process of the model. Preference judgments are typically applied to individual responses or short interactions. They provide weak supervision for complex tasks that require sustained planning, internal consistency across many steps, or explicit reasoning over latent variables. While RLHF can improve surface coherence, it does not confer deeper problem-solving abilities.
There are also limits to what preference data can express. Humans are good at judging outputs they can read and compare, but less effective at evaluating internal model behavior. Issues such as deceptive reasoning, hidden goal formation, or strategic misrepresentation may not be visible at the response level until they manifest as overt failures. RLHF offers no direct mechanism for detecting or correcting such behaviors.
Another constraint is normative disagreement. Human preferences are not universal. They vary across cultures, organizations, and contexts. RLHF inevitably encodes a particular set of values, even when care is taken to diversify annotators. This makes alignment fragile when models are deployed globally or repurposed for use cases that differ from their training assumptions. What appears aligned in one context may feel inappropriate or misleading in another.
RLHF also interacts poorly with distributional shift. As models are exposed to new domains, tools, or user behaviors, the learned reward proxy can become miscalibrated. Optimization then reinforces outdated preferences, leading to subtle degradation that is difficult to detect through offline evaluation alone. This is not a corner case; it is a predictable consequence of using learned proxies for complex human judgment.
For these reasons, RLHF should not be treated as a comprehensive alignment solution. It is a powerful technique for improving usability, safety presentation, and interaction quality, but it operates within narrow bounds. It shapes responses, not intentions. It reflects preferences, not principles. It optimizes for what is rewarded, not for what is ultimately correct or desirable in every context.
Understanding these limits is not a critique of RLHF. It is a prerequisite for using it responsibly. Teams that treat RLHF as one layer in a broader system — alongside evaluation, monitoring, and domain-specific controls — are far more likely to achieve reliable outcomes than those who expect preference optimization alone to carry the burden of alignment.
When RLHF works well in practice
Despite its limitations, RLHF has proven effective in a specific class of deployment scenarios. Its successes are not accidental. They emerge when teams apply RLHF to problems that are well matched to preference-based optimization and when expectations are scoped accordingly.
The clearest wins come from conversational systems handling complex tasks, where user satisfaction depends on qualitative behavior rather than objective correctness alone. Instruction-following assistants, support chatbots, and safety-sensitive interfaces all exhibit failure modes that traditional supervised learning struggles to address. In these settings, small differences in tone, verbosity, refusal framing, or uncertainty signaling can dominate user perception.
Predictability over raw capability
Chat-based assistants illustrate this pattern clearly. Early large language models were often capable of producing correct answers, but they did so unreliably. RLHF did not make these systems more knowledgeable. It made them more predictable. That predictability — consistent instruction adherence, stable refusal behavior, and reduced surprise — is what users ultimately experience as helpfulness.
RLHF also performs well when alignment goals can be expressed through relative judgment rather than explicit rules. Safety behavior is a common example. Encoding appropriate refusals, cautious phrasing, or harm-minimizing responses as hard constraints often introduces brittleness. Human comparison data captures these trade-offs more naturally.
Scope and iteration matter more than scale
Successful deployments share another characteristic: a narrow initial scope. Teams that attempt to align a model across all possible behaviors simultaneously often struggle to produce coherent preference signals. By contrast, teams that focus on a limited set of interaction types — such as customer support queries, tool-usage instructions, or refusal scenarios — generate higher-quality data and more stable reward models.
Iteration matters more than scale. RLHF works best when treated as a cyclical process rather than a one-time training phase. Early annotation signals surface unexpected failure modes. Reward models expose blind spots. Policy optimization reveals new edge cases. Teams that incorporate these signals into successive data collection rounds consistently outperform those that attempt to “solve alignment” in a single pass.
Preference clarity enables consistency
Another common success factor is explicit preference definition. While RLHF relies on subjective judgment, that judgment still requires guidance. High-performing teams invest in clear annotation rubrics, concrete examples, and ongoing calibration. Annotators are not asked to intuit vague notions of quality. They are trained to apply shared criteria. This reduces noise without eliminating the flexibility that makes preference learning powerful.
Effective RLHF deployments rarely rely on raw human feedback alone. They combine human judgment with automated filtering, model-assisted review, and targeted escalation. Humans remain the source of normative signals, but they are supported by tooling that identifies ambiguity, disagreement, and drift. This hybrid approach improves both efficiency and consistency.
Finally, RLHF works best when teams accept what it is optimizing for. Preference alignment improves interaction quality, not underlying intelligence. Systems aligned with RLHF are easier to use, safer to interact with, and more predictable. They still require complementary techniques for factual grounding, reasoning, and tool integration.
When applied under these conditions, RLHF is not fragile or mysterious. It is a practical engineering tool — one that rewards discipline, iteration, and respect for the human signals it encodes.
Building a sustainable RLHF pipeline
RLHF succeeds or fails over time, not at the moment of a single training run. Teams that treat it as a one-off alignment phase often see early gains followed by regression, drift, or escalating maintenance costs. Durable deployments approach RLHF as an ongoing pipeline with clear ownership, feedback loops, and operational boundaries.
Treat RLHF as infrastructure, not a phase
A sustainable pipeline starts with separation of concerns. Preference collection, reward modeling, and policy optimization are treated as distinct systems, each with its own cadence and quality checks. This separation allows teams to diagnose failures more precisely. When behavior degrades, it matters whether the cause lies in ambiguous preference data, reward model misgeneralization, or overly aggressive policy updates.
Successful teams also establish explicit refresh cycles. Annotation data ages. As models change, user expectations evolve, and products expand into new domains, previously collected judgments lose relevance. Rather than continuously appending new data, mature pipelines periodically reassess which signals remain valid and where retraining is required. This prevents the accumulation of incompatible alignment objectives that can destabilize later optimization.
Ownership is another critical factor. Sustainable RLHF pipelines have clear responsibility boundaries between research, product, and data operations. Preference criteria are not left implicit or delegated entirely to annotators. Product teams define acceptable behavior. Research teams translate those expectations into training objectives. Data teams enforce consistency through guidelines and review. When these roles blur, alignment quality degrades silently.
Quality control must be continuous
Quality assurance must operate at multiple levels. Individual judgments are sampled and reviewed. Disagreement rates are tracked over time. Reward model outputs are monitored for distributional shifts. High-performing teams pay particular attention to where disagreement concentrates, using it to identify underspecified tasks or emerging edge cases. Over time, this feedback informs both annotation design and model behavior.
As pipelines scale, hybrid workflows become unavoidable. Humans remain the source of normative judgment, but they are increasingly supported by LLM-based quality checks and model-assisted review. Low-risk, high-agreement tasks can be triaged automatically. Ambiguous or high-impact cases are escalated for expert review. This allows teams to concentrate human effort where it has the greatest marginal value.
Platforms such as Toloka are built around this long-running model of preference collection. They combine tiered expert pools with continuous quality controls to support RLHF workflows that extend beyond a single training cycle. Their value lies less in scale alone than in maintaining consistency as requirements change.
Design for exit, not endless optimization
Finally, sustainable RLHF pipelines are designed with exit conditions. Teams define upfront what success looks like, when alignment objectives are considered met, and when further optimization risks diminishing returns. This discipline prevents RLHF from becoming an open-ended effort that absorbs resources without proportional benefit.
When treated as infrastructure rather than a technique, reinforcement learning from human feedback becomes more predictable and less fragile. The hardest part is not learning how to optimize a model, but learning how to operationalize human judgment without exhausting it.
Practical implementation considerations
RLHF is powerful, but it is neither cheap nor universally appropriate. Teams adopting it successfully tend to do so for specific reasons and with clear constraints in mind. Understanding when RLHF adds value — and when it does not — is essential to avoiding unnecessary complexity.
When a language model needs RLHF
RLHF is most effective when model behavior must satisfy nuanced, subjective criteria that cannot be expressed as simple rules or automated metrics. This is typical for customer-facing assistants, safety-sensitive applications, and systems expected to follow complex instructions reliably across diverse contexts.
Models deployed in conversational settings benefit disproportionately. Small behavioral inconsistencies — overconfidence, verbosity, refusal tone — have an outsized impact on user trust. RLHF provides a mechanism to correct these issues systematically by optimizing directly against preference signals rather than proxy metrics.
By contrast, RLHF is often unnecessary for narrow, well-specified tasks. Information extraction, classification, or deterministic transformations rarely benefit from preference optimization. In these cases, supervised fine-tuning or prompt-level control is usually sufficient and significantly cheaper.
Operational costs and organizational trade-offs
The true cost of RLHF is not limited to compute. It is an ongoing organizational commitment that combines data operations, quality assurance, and iterative retraining. Preference data must be refreshed as models evolve, products expand into new domains, or user expectations shift. Unlike pre-training, RLHF is rarely a one-time effort.
Human annotation introduces latency into development cycles. Collecting, validating, and incorporating new judgments can take weeks, not hours. Teams that underestimate this timeline often struggle to respond quickly to emerging failure modes in production.
There are also coordination costs. RLHF requires alignment between research teams, product owners, and annotation pipelines. Preference criteria must be defined clearly enough for annotators to apply consistently, yet flexibly enough to accommodate edge cases. As systems scale across languages, regions, or regulatory environments, these requirements multiply.
For smaller teams, these overheads can outweigh the benefits of RLHF. In such cases, simpler alignment techniques or narrower deployment scopes may be more sustainable.
Failure modes in production
Even well-trained RLHF models can fail in deployment. One common pattern is behavioral regression after incorporating new data derived from human annotation. Improvements in one dimension — such as safety or politeness — can inadvertently degrade usefulness or clarity if reward signals are not carefully balanced.
Another frequent issue is preference drift. Annotator populations, task instructions, or product goals evolve over time, subtly shifting what “preferred” behavior means. If earlier data is not revisited, models may accumulate incompatible alignment signals, leading to inconsistent responses across similar prompts.
RLHF systems also tend to perform worse at the margins: rare prompts, adversarial inputs, or novel use cases that fall outside the training distribution. Because the reward model generalizes imperfectly, optimization can amplify errors precisely where human oversight would matter most.
These failures are often difficult to diagnose. Offline evaluation may show steady improvement while real users experience degraded behavior. This gap reinforces the need for continuous monitoring and periodic re-alignment rather than treating RLHF as a completed training step.
Tools and frameworks
Several open-source frameworks support RLHF experimentation and deployment. Hugging Face’s TRL library is among the most widely used, offering implementations for reward modeling, policy optimization, and evaluation workflows. Such tools lower the technical barrier to entry, but they do not remove the core challenges.
Across production deployments, the limiting factor remains human preference data. Tooling can accelerate training loops, but alignment quality ultimately depends on how feedback is collected, validated, and maintained over time. Teams that treat RLHF primarily as a software problem tend to underestimate the human systems required to make it work.
Conclusion: RLHF as operational alignment
Reinforcement Learning from Human Feedback changed the trajectory of large language models by changing what they are optimized for. Instead of rewarding statistical similarity to training data, RLHF rewards behavior that people consistently prefer in interaction. That shift explains why systems built on similar base models can feel radically different in practice.
RLHF is not a solution to intelligence, reasoning, or truth. It is a mechanism for shaping behavior. It encodes norms rather than facts, preferences rather than guarantees. The models it produces are not aligned in an abstract sense; they are aligned to the judgments, constraints, and assumptions embedded in their feedback pipelines.
In that sense, RLHF reflects a broader shift in machine learning practice toward systems that must behave reliably in open-ended, real-world interaction rather than closed benchmarks.
This makes RLHF both powerful and fragile. Its success depends less on algorithms than on the quality, scope, and maintenance of human preference data. Poorly specified criteria, narrow annotator pools, or stale feedback lead to misalignment just as reliably as modeling errors. Well-designed pipelines, by contrast, produce systems that are more predictable, safer to deploy, and easier for users to trust.
As language models move into customer-facing, safety-sensitive, and decision-support roles, alignment becomes an operational concern rather than a research milestone. RLHF works best when treated as infrastructure: continuously updated, carefully governed, and explicitly scoped over time.
Supporting that infrastructure requires more than training code. It requires systems for structured preference collection, annotator calibration, disagreement analysis, and ongoing quality control around human feedback. Platforms such as Toloka are built around these requirements, providing the operational backbone needed to sustain RLHF workflows beyond a single training run.
Platform CTA: "Ready to collect preference data for RLHF? Start your first project on Toloka Platform with AI-assisted setup. Access our three-tier expert network – including AI Tutors specifically trained for RLHF annotation – and leverage LLM-based quality assurance to ensure consistent, high-quality preference data."
Subscribe to Toloka news
Case studies, product news, and other articles straight to your inbox.