Error reduction in a recommendation system for e-commerce: a case study

Subscribe to Toloka News
Subscribe to Toloka News
Yandex.Market is an e-commerce marketplace with over one million items available in its product catalog. When the company needed to tune their product recommendation engine, they developed a data labeling pipeline in Toloka to get the data they needed.
Challenge
Recommender (or recommendation) systems are algorithms used by e-commerce companies to suggest related products when customers are choosing products online. The ultimate goal is to increase average purchase value and CTR in the online store. An effective recommender system needs vast amounts of labeled data to support its ML model.
Yandex.Market started out by using automated solutions to train their recommendation model, but the algorithm was not performing well enough. They developed a new strategy using the Toloka platform:
- Label products with matching accessories and related items.
- Train a gradient boosting model to apply filters based on the labeled dataset.
- Measure precision and recall and then retrain the model until satisfied.
Solution
The product pairs were pre-selected by analyzing the content of numerous shopping carts. If any two products were purchased together at least five times, that was a good indicator that the two were either related products or one of them was an accessory to the other.
Initially, the team merged related products and accessories into one labeling project but soon decided to separate the two. They discovered that most accessories are associated with a single product, whereas related items tend to be connected to multiple products.
For example, for the iPhone 13, a phone case would be considered an accessory, while AirPods would be considered related products (listed under "Frequently bought together" on the site).
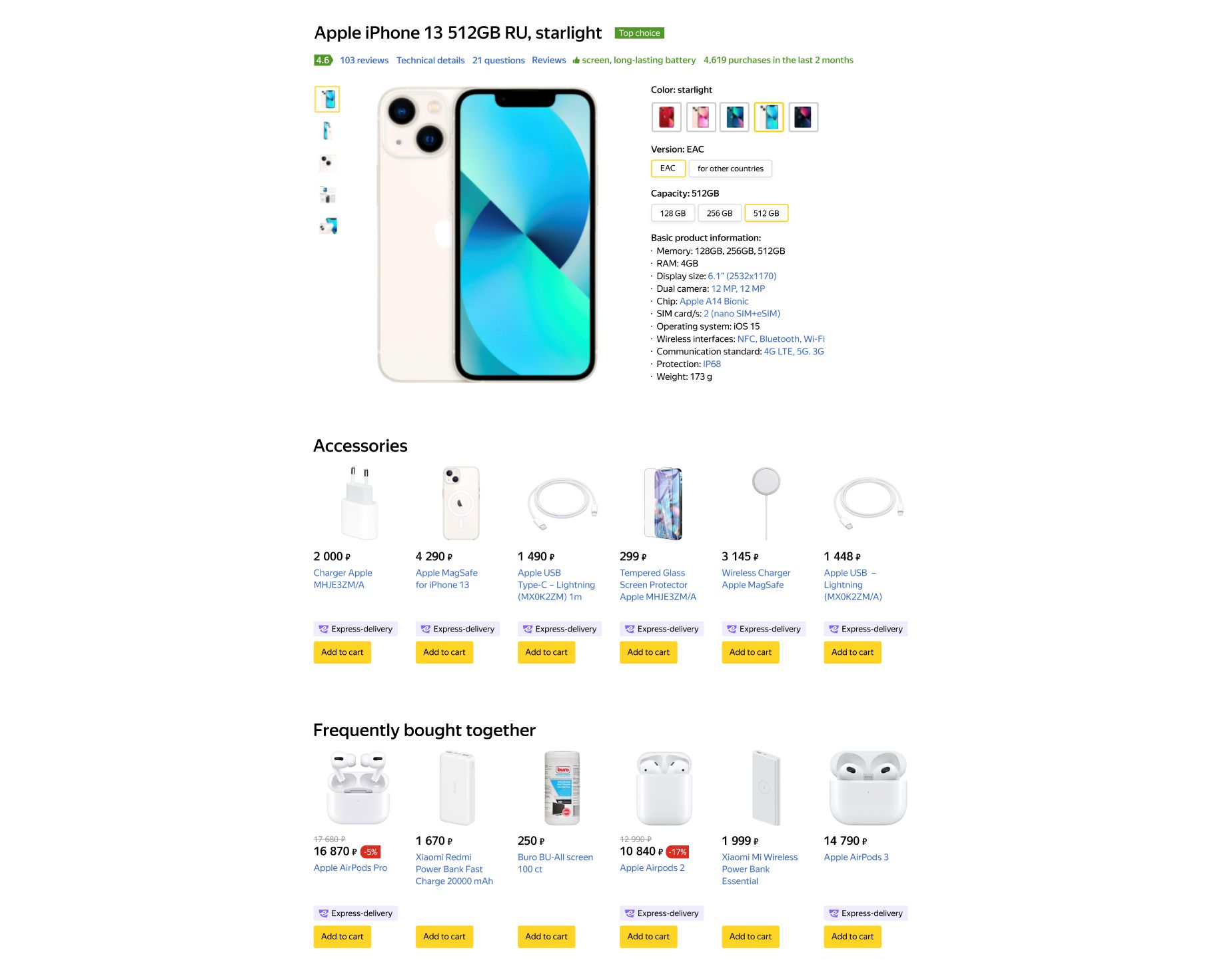
After realizing that related products and accessories needed separate labeling processes, the company used pre-labeling to prepare separate datasets. Then they set up quality control and launched the two labeling projects with trained and tested performers.
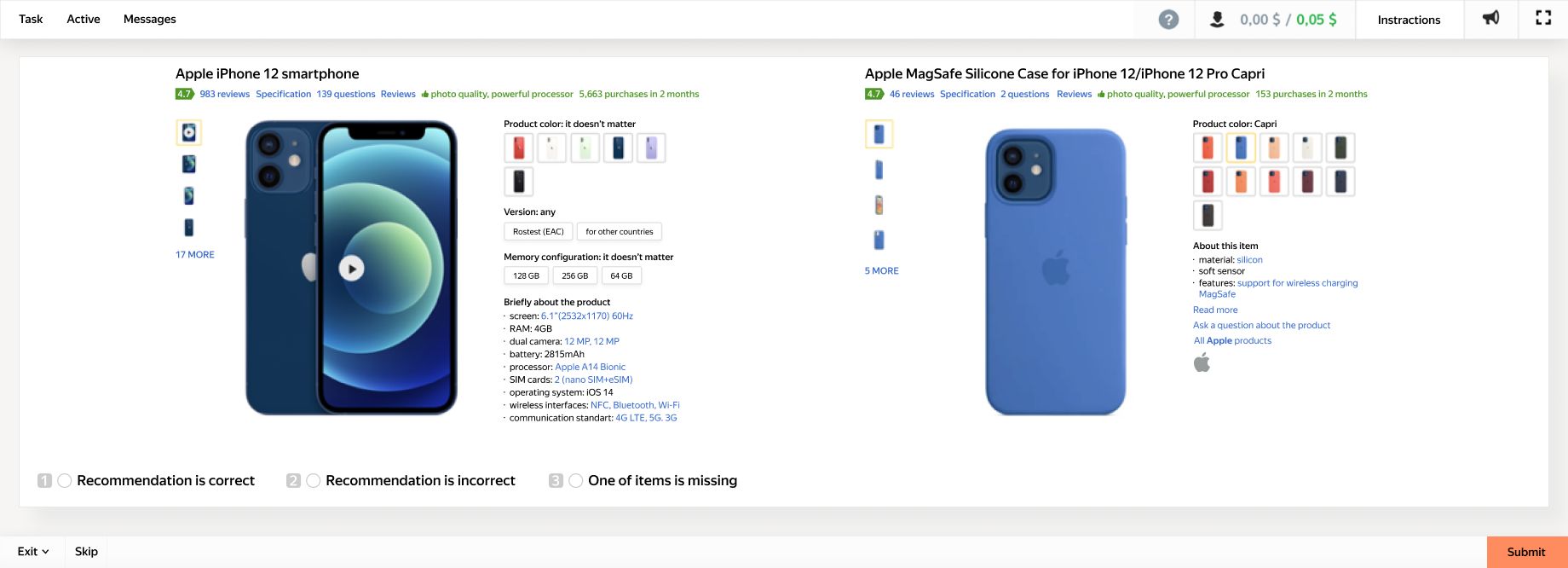
The labeled data was sent back to Toloka in a new project to check the quality of results. If there were too many mistakes or the engineers disagreed with Tolokers’ judgments, they improved the task instructions and added more examples to the training tasks, then continued the process. High-quality labels were also collected and reused as control tasks in subsequent projects.
The pipeline for both projects looked like this:
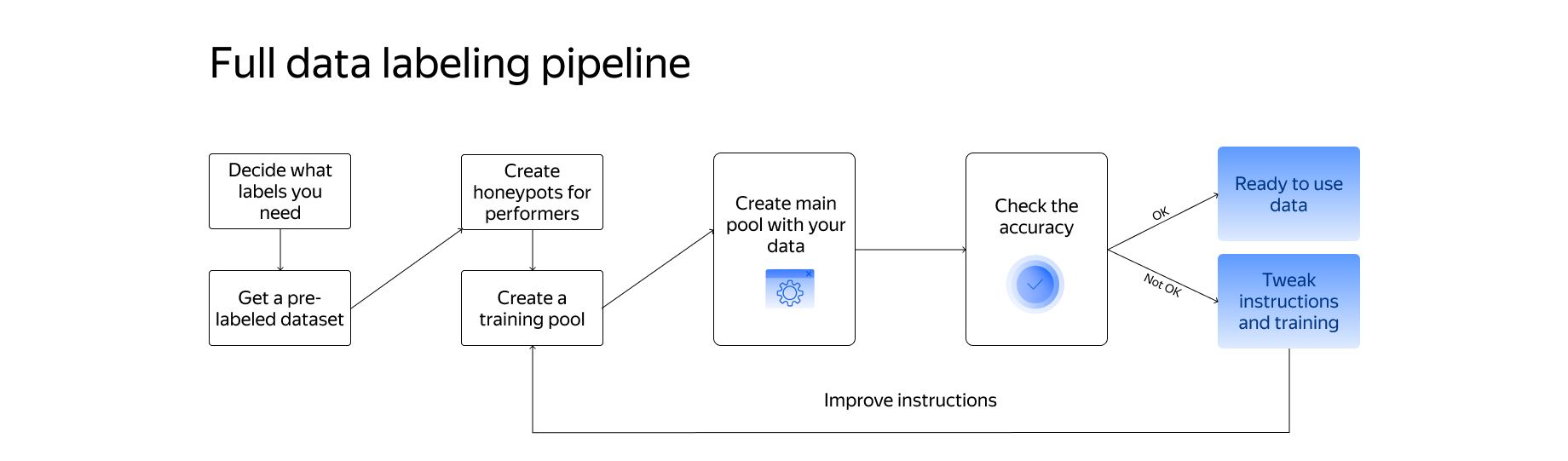
Once the labeled dataset was ready, it was fed into a gradient boosting framework to train and improve the performance of the recommendation model. Finally, accuracy and recall were measured and the model was retrained as much as necessary.
Unexpected issues
One of the problems that impeded labeling was that some items had unclear descriptions and Tolokers didn’t have enough information to label them correctly.

The team tried labeling with in-house experts to get around this issue, but the process was not effective enough. Now they have switched to using Tolokers to search for missing information.
Results
Special thanks to Maxim Eliseev for providing the data for this post.

Recent articles




Have a data labeling project?

More about Toloka
- Our mission is to empower businesses with high quality data to develop AI products that are safe, responsible and trustworthy.
- Toloka is a European company. Our global headquarters is located in Amsterdam. In addition to the Netherlands, Toloka has offices in the US, Israel, Switzerland, and Serbia. We provide data for Generative AI development.
- We are the trusted data partner for all stages of AI development–from training to evaluation. Toloka has over a decade of experience supporting clients with its unique methodology and optimal combination of machine learning technology and human expertise. Toloka offers high quality expert data for training models at scale.
- The Toloka team has supported clients with high-quality data and exceptional service for over 10 years.
- Toloka ensures the quality and accuracy of collected data through rigorous quality assurance measures–including multiple checks and verifications–to provide our clients with data that is reliable and accurate. Our unique quality control methodology includes built-in post-verification, dynamic overlaps, cross-validation, and golden sets.
- Toloka has developed a state-of-the-art technology platform for data labeling and has over 10 years of managing human efforts, ensuring operational excellence at scale. Now, Toloka collaborates with data workers from 100+ countries speaking 40+ languages across 20+ knowledge domains and 120+ subdomains.
- Toloka provides high-quality data for each stage of large language model (LLM) and generative AI (GenAI) development as a managed service. We offer data for fine-tuning, RLHF, and evaluation. Toloka handles a diverse range of projects and tasks of any data type—text, image, audio, and video—showcasing our versatility and ability to cater to various client needs.
- Toloka addresses ML training data production needs for companies of various sizes and industries– from big tech giants to startups. Our experts cover over 20 knowledge domains and 120 subdomains, enabling us to serve every industry, including complex fields such as medicine and law. Many successful projects have demonstrated Toloka's expertise in delivering high-quality data to clients. Learn more about the use cases we feature on our customer case studies page.