Image classification: A case study on training self-driving cars

Subscribe to Toloka News
Subscribe to Toloka News
This article will be helpful for junior and middle ML engineers, data engineers, analysts, and anyone else wondering how to tackle image classification.
What is image classification in the context of self-driving cars?
While autonomous vehicles don’t need humans to drive them, they do need humans to train their algorithms. And image classification is a common way to get data for that.
Safety and efficiency of self-driving cars rely on millions of correctly labeled data points.
There are many people out on the roads, and all of them play a different role. To create a solution that predicts their behavior, you need a labeled dataset of images depicting them.
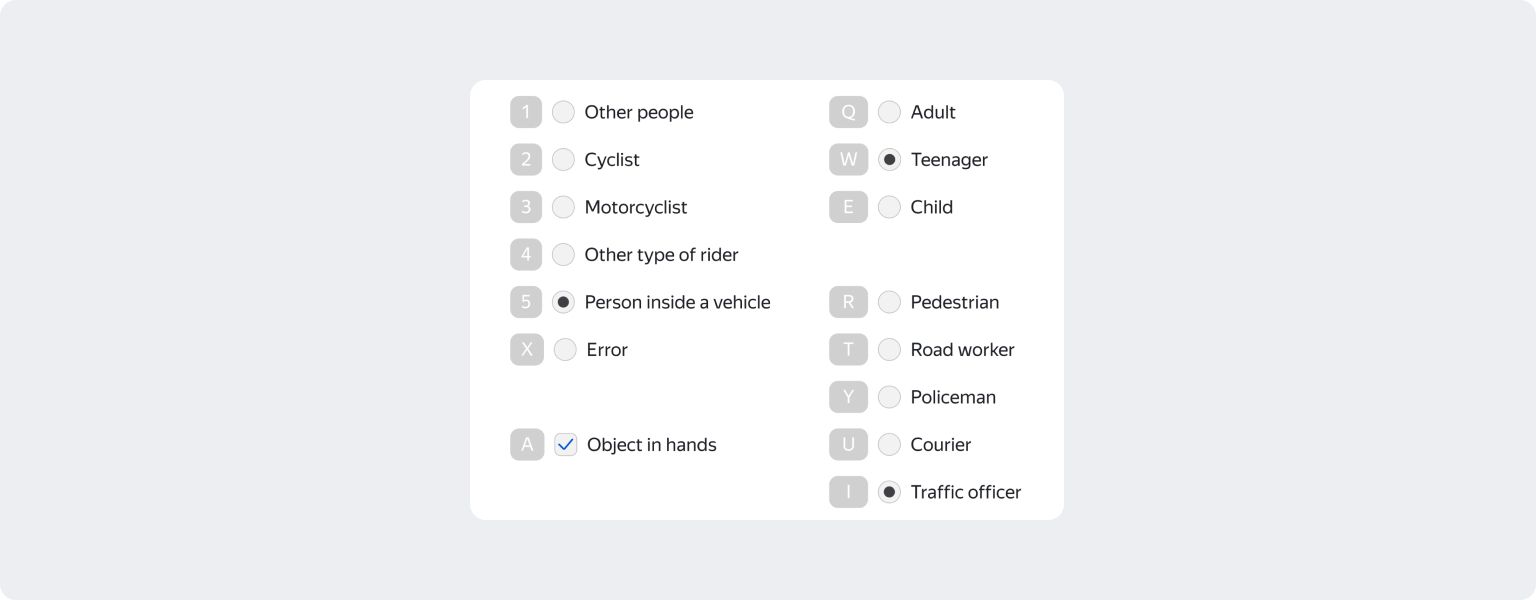
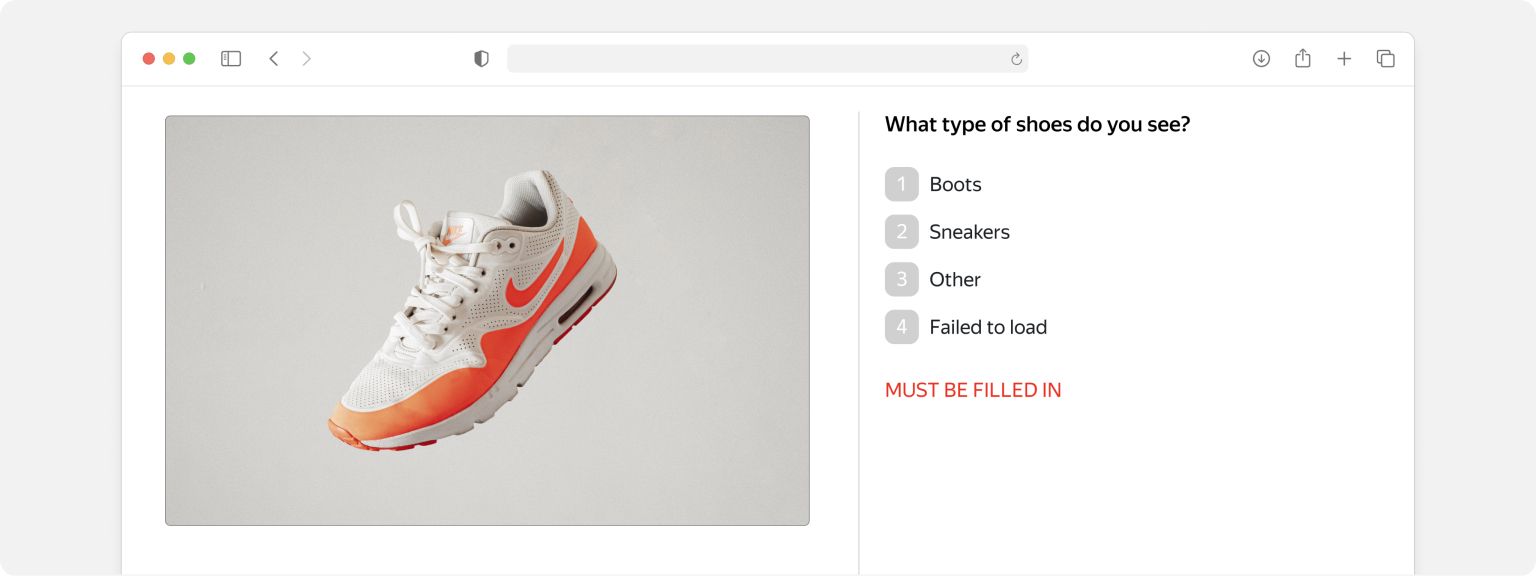
The tricky part in training an image classification model is assigning classes to the people: pedestrians of different ages, drivers, cyclists, and more. Out-of-the-box image classification models can find people in images, but labeling details about their role on the road takes a human touch.
Toloka has a data labeling preset designed specifically for this kind of job. Tolokers, which is what we call annotators, look at the images and pick a class. When they’re done, you have a labeled dataset you can use to train your model.
How to solve an image classification task in Toloka?
Here’s the basic pipeline for image classification work:
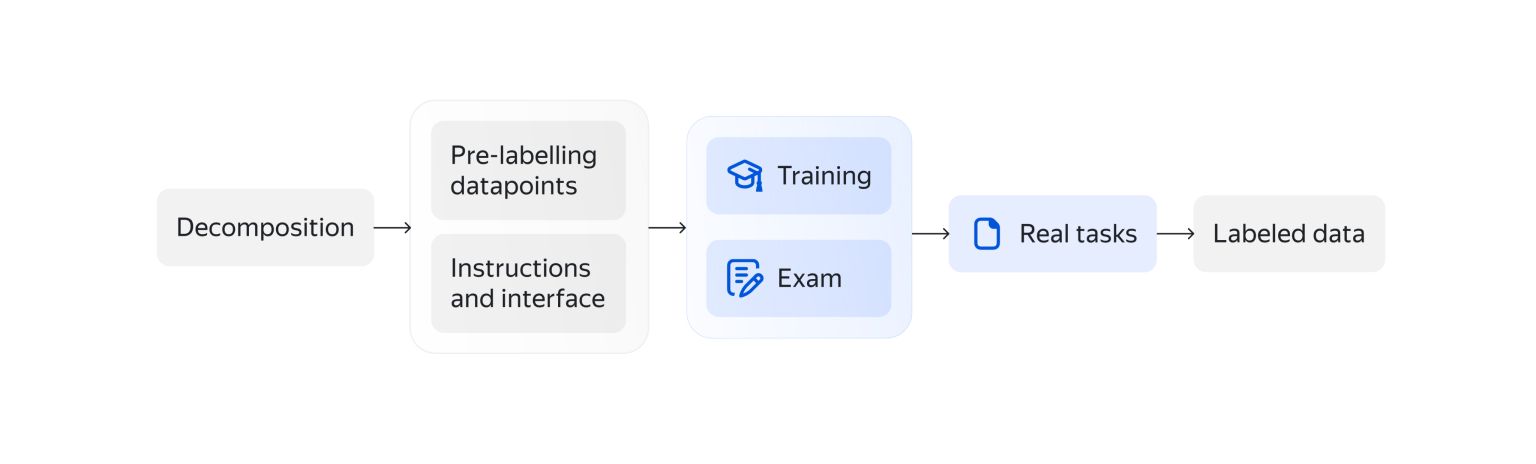
Below are some tips and tricks from our ML team.
Decomposition: Define the question and answer choices
In any image classification task, start with the main question you want to ask. If it’s too complicated, you may want to break the job down into subtasks you can sequentially.
After you’ve defined the question, ask yourself what classes you expect. They help you define the answers, prepare a task interface, and write instructions for Tolokers.
Quality: Prepare a control dataset
Control tasks, also known as golden tasks or honeypots, are a quality control tool that helps you monitor and fine-tune how accurate the labels are. Start by pre-labeling a small subset of your dataset. For large datasets (over 1000 tasks), we recommend adding at least 1% of the control tasks. For small datasets (around 100 tasks), you’ll need 10%.
If it’s an ongoing image classification project, you don’t need a fixed percentage. One or two hundred per class is enough for very large samples, though our experience shows that the fewer classes you have, the more examples of each you need.
Mix the control tasks in with the real ones. That way, you can compare Toloker answers with the answers to the control tasks to get an idea of labeling accuracy. See the documentation to learn more about control tasks.
Overlap: The key to crowdsourcing
Overlap is the number of people who answer each question. Most commonly, it’s set to three.
For complex image classification tasks, you can use dynamic overlap. Toloka assigns confidence to Toloker responses in that case. When confidence drops below a specified level, Toloka increases the overlap value until the confidence reaches the set value or the overlap reaches the predefined maximum.
Instructions: Get to know your dataset
The more complete and clear your instructions for Tolokers are, the better labeling quality you will get.
To improve your instructions, you can run labeling for a small part of your dataset without control tasks first. Read through the results. That will reveal the most common errors and identify cases the instructions don’t cover.
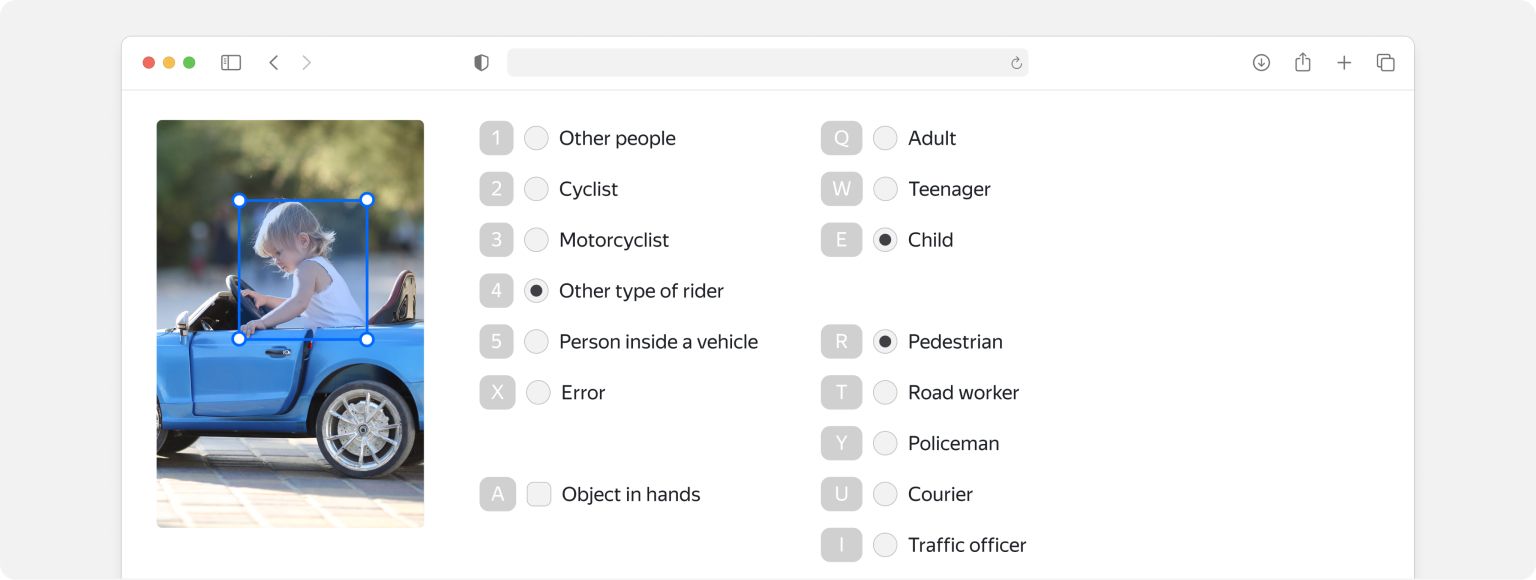
For example, would you consider a big toy car a vehicle when it comes to image classification? If putting together instructions that are short and sweet is a challenge, you may want to revisit the idea of breaking the job down. Read our guide on decomposition to learn why that’s important and how to do it.
Interface: How they see your task
The task interface defines what the job looks like for Tolokers, and the logic they follow to process their responses. If it’s clean and crisp, they can work faster and on different devices.
Adding automatic verifications improves labeling quality. For example, you can make sure Tolokers click links they’re supposed to click and ensure that input values match your expected format.
Toloka’s image classification preset comes with a basic interface designed for this kind of work. But you can still customize it, for example, if you decide to change the classes or replace the radio buttons with checkboxes.
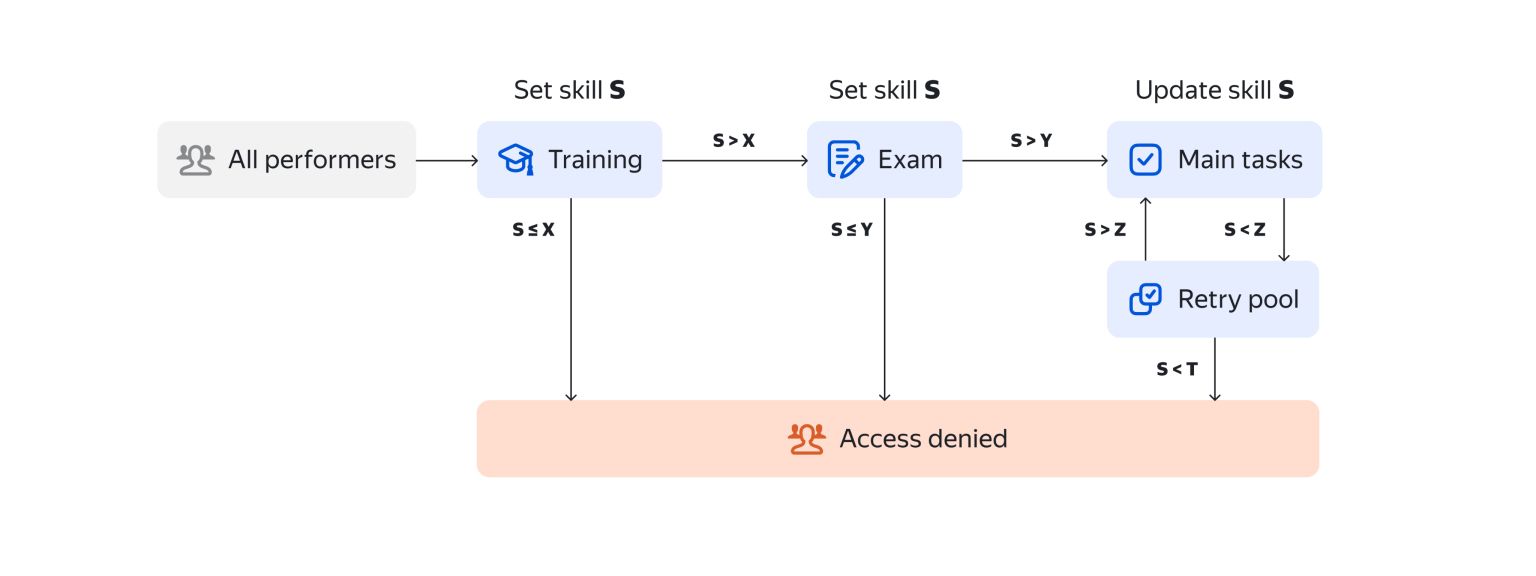
Training and exams: Human learning before machine learning
Training lets you select Tolokers who have mastered your task and thus offer superior quality. Whenever you’re ready to scale up, you can train more of them.
In our case, the team didn’t set high passing requirements for training. We figured people who didn’t perform well in training would still benefit from the tips they saw there.
If your work is complicated, placing higher demands on Tolokers, you can add an exam too. Learn more by checking out our guides on setting up training pools and exam pools.
Common challenges of image classification projects
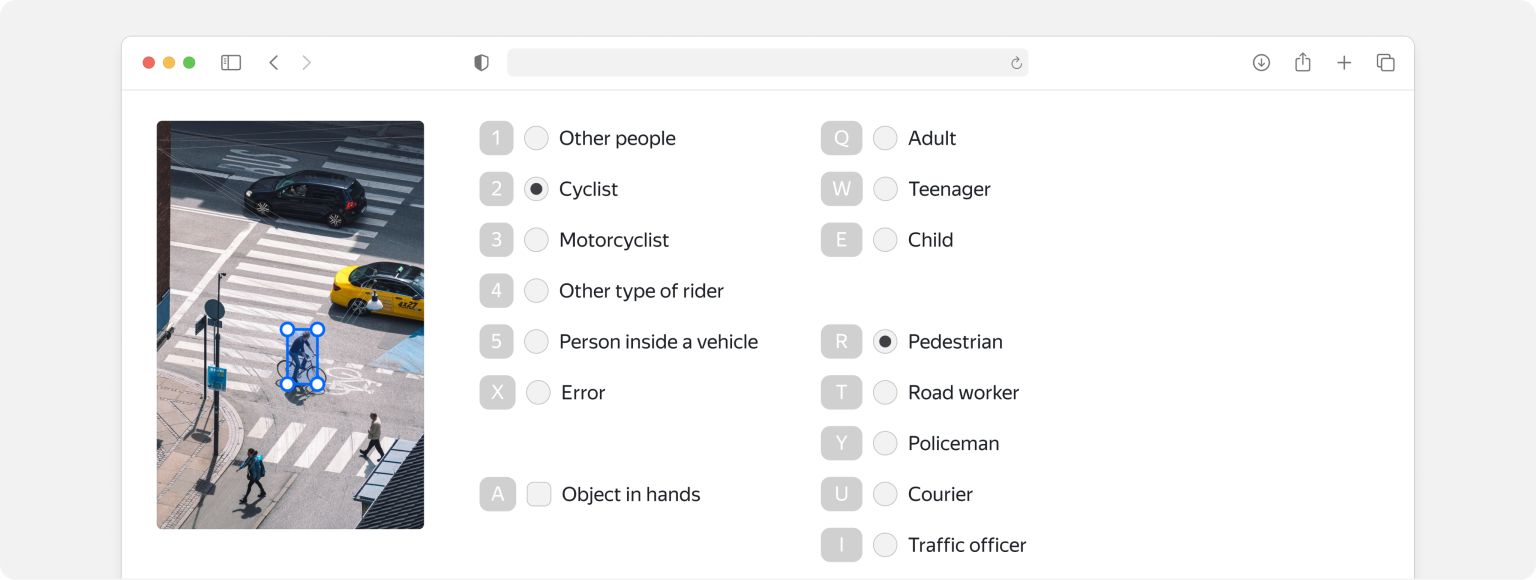
Inaccurate and ambiguous instructions can sabotage your results. Tolokers might struggle to distinguish between some classes, for instance.
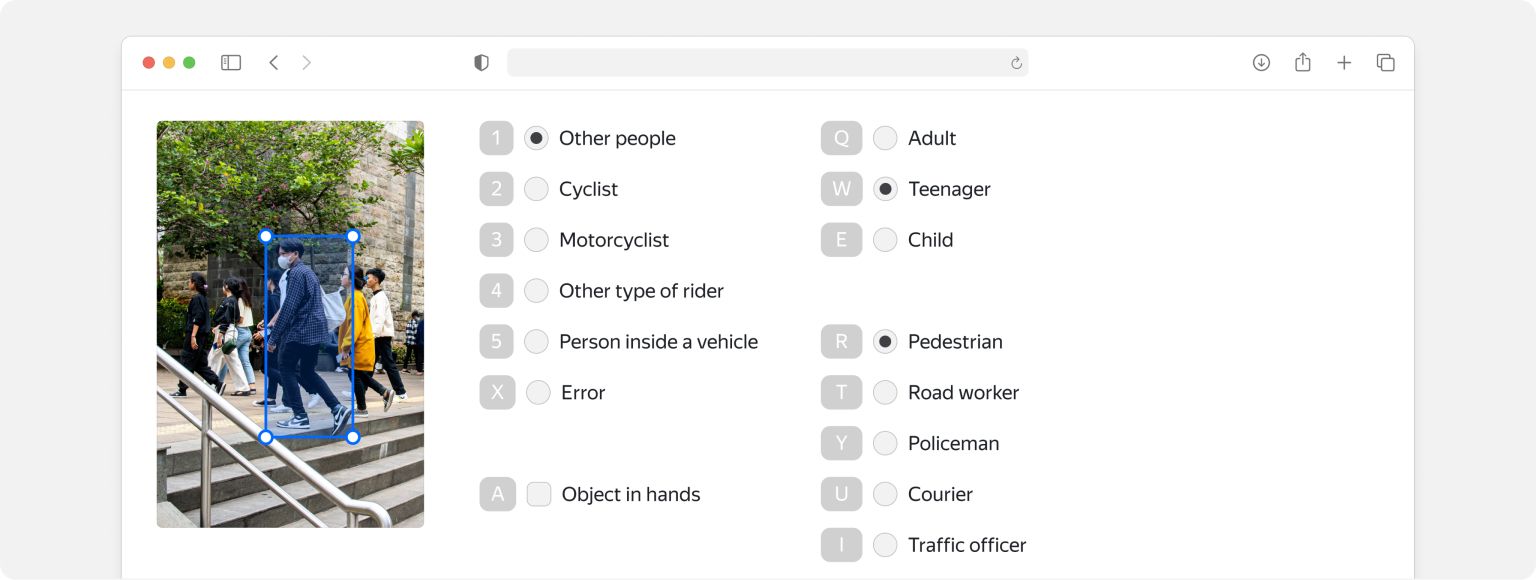
In the case above, Tolokers had a tough time defining the “teenager” class. That led to pervasive problems distinguishing teenagers from children and adults.
The team solved the problem by adding examples of the class to training, control tasks, and exams. They selected examples of teenagers who clearly looked different from children or adults, in some cases because of their height.
Gathering feedback from Tolokers is also helpful. It sometimes includes valuable information about bugs in the interface or important points about the dataset. You can answer their questions and ask for more details.

Automation tips
You can automate your work with Toloka by using Toloka API. To make integrating your processes with the API easier, we offer Toloka-Kit (for Python) and Toloka-Java-SDK (for all JVM-based languages). Check out this simple Jupyter Notebook example of an image classification task done with Toloka-Kit.
You can also find a step-by-step image classification tutorial in our documentation.


Recent articles




Have a data labeling project?

More about Toloka
- Our mission is to empower businesses with high quality data to develop AI products that are safe, responsible and trustworthy.
- Toloka is a European company. Our global headquarters is located in Amsterdam. In addition to the Netherlands, Toloka has offices in the US, Israel, Switzerland, and Serbia. We provide data for Generative AI development.
- We are the trusted data partner for all stages of AI development–from training to evaluation. Toloka has over a decade of experience supporting clients with its unique methodology and optimal combination of machine learning technology and human expertise. Toloka offers high quality expert data for training models at scale.
- The Toloka team has supported clients with high-quality data and exceptional service for over 10 years.
- Toloka ensures the quality and accuracy of collected data through rigorous quality assurance measures–including multiple checks and verifications–to provide our clients with data that is reliable and accurate. Our unique quality control methodology includes built-in post-verification, dynamic overlaps, cross-validation, and golden sets.
- Toloka has developed a state-of-the-art technology platform for data labeling and has over 10 years of managing human efforts, ensuring operational excellence at scale. Now, Toloka collaborates with data workers from 100+ countries speaking 40+ languages across 20+ knowledge domains and 120+ subdomains.
- Toloka provides high-quality data for each stage of large language model (LLM) and generative AI (GenAI) development as a managed service. We offer data for fine-tuning, RLHF, and evaluation. Toloka handles a diverse range of projects and tasks of any data type—text, image, audio, and video—showcasing our versatility and ability to cater to various client needs.
- Toloka addresses ML training data production needs for companies of various sizes and industries– from big tech giants to startups. Our experts cover over 20 knowledge domains and 120 subdomains, enabling us to serve every industry, including complex fields such as medicine and law. Many successful projects have demonstrated Toloka's expertise in delivering high-quality data to clients. Learn more about the use cases we feature on our customer case studies page.