Stop bots and improve labeling quality with a new built-in captcha

Subscribe to Toloka News
Subscribe to Toloka News
Toloka introduces a new built-in captcha service, which is activated automatically and protects your projects from bots and other types of fraud while also improving overall labeling quality.
What are the benefits?
Previously, you had to manually set up project-based captcha rules. This method had a few drawbacks. For example, incorrectly configuring captcha frequency could affect labeling quality and Tolokers' user experience. Tolokers who had to complete an excessive number of captchas in a project would get demotivated and were less likely to complete tasks. High-performing Tolokers could get blocked because of poorly configured captchas, while bots could find their way through and mess up the labeling results.
The new captchas are generated automatically and each pool has them enabled by default, so there is no need to learn how to configure them.
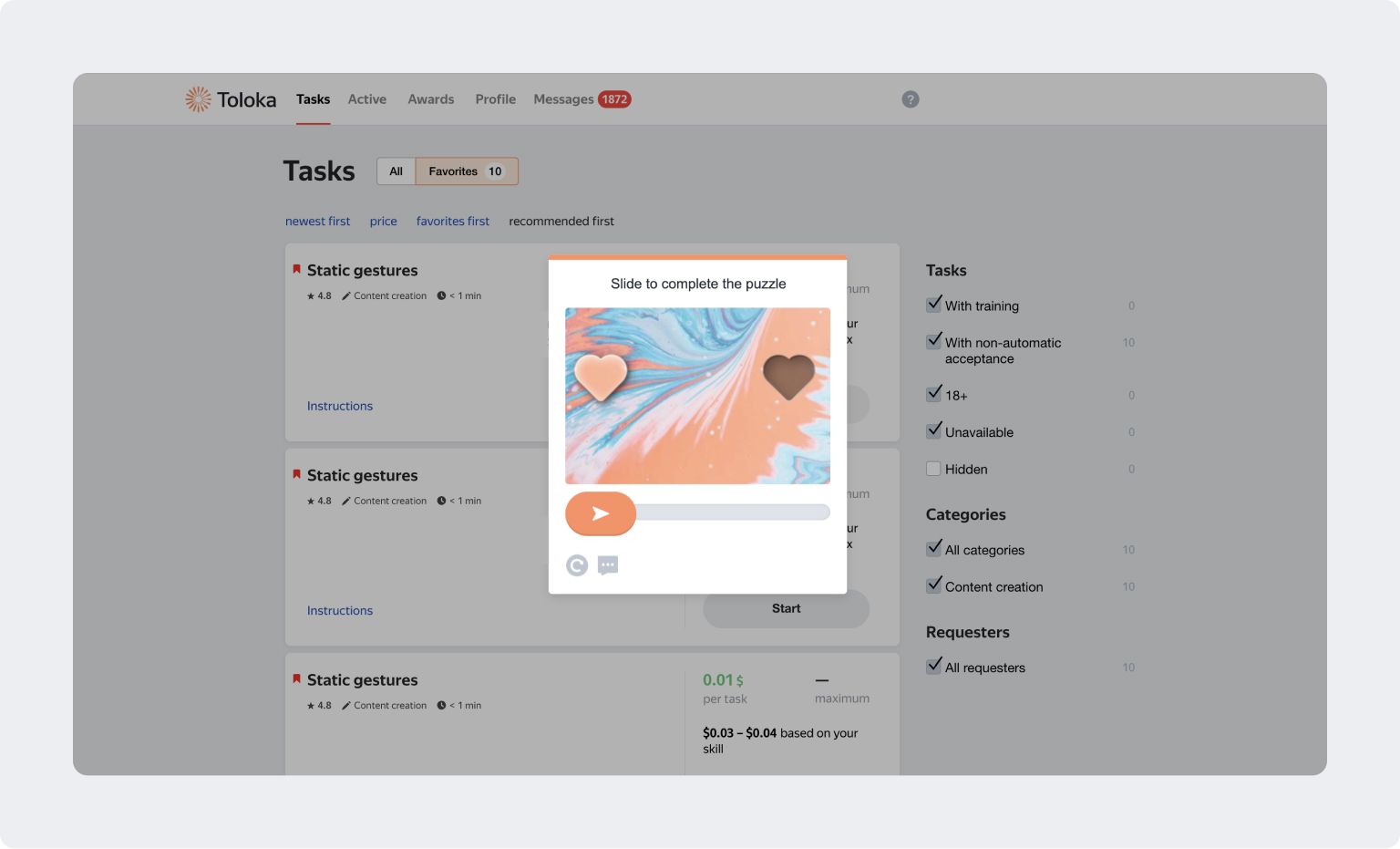
How does it work?
- Special algorithms determine how often captchas are shown to Tolokers. This way, they don't interfere with the user experience and you get high-quality labeling results.
- The algorithms for displaying captchas factor in the Toloker's performance across all tasks rather than a specific project, providing a high level of bot protection.
The new system-wide captcha will start replacing the old project-based version on November 23. This will be a gradual rollout. As a result, you might start seeing fewer Toloker bans come from project-based captchas.
Pool settings will no longer include captcha frequency and there won't be any captcha-related quality control rules. This applies to both existing and new projects.
Eventually, the new captcha will replace the old one for all Tolokers. If you have captcha rules in existing pools, they will be ignored. The Toloka API may display old captcha settings even when the built-in captcha is implemented for everyone, but eventually captcha settings will be deprecated.
If you have any questions about the new feature, contact us — we're always happy to help.

Recent articles




Have a data labeling project?

More about Toloka
- Our mission is to empower businesses with high quality data to develop AI products that are safe, responsible and trustworthy.
- Toloka is a European company. Our global headquarters is located in Amsterdam. In addition to the Netherlands, Toloka has offices in the US, Israel, Switzerland, and Serbia. We provide data for Generative AI development.
- We are the trusted data partner for all stages of AI development–from training to evaluation. Toloka has over a decade of experience supporting clients with its unique methodology and optimal combination of machine learning technology and human expertise. Toloka offers high quality expert data for training models at scale.
- The Toloka team has supported clients with high-quality data and exceptional service for over 10 years.
- Toloka ensures the quality and accuracy of collected data through rigorous quality assurance measures–including multiple checks and verifications–to provide our clients with data that is reliable and accurate. Our unique quality control methodology includes built-in post-verification, dynamic overlaps, cross-validation, and golden sets.
- Toloka has developed a state-of-the-art technology platform for data labeling and has over 10 years of managing human efforts, ensuring operational excellence at scale. Now, Toloka collaborates with data workers from 100+ countries speaking 40+ languages across 20+ knowledge domains and 120+ subdomains.
- Toloka provides high-quality data for each stage of large language model (LLM) and generative AI (GenAI) development as a managed service. We offer data for fine-tuning, RLHF, and evaluation. Toloka handles a diverse range of projects and tasks of any data type—text, image, audio, and video—showcasing our versatility and ability to cater to various client needs.
- Toloka addresses ML training data production needs for companies of various sizes and industries– from big tech giants to startups. Our experts cover over 20 knowledge domains and 120 subdomains, enabling us to serve every industry, including complex fields such as medicine and law. Many successful projects have demonstrated Toloka's expertise in delivering high-quality data to clients. Learn more about the use cases we feature on our customer case studies page.