How to set up a parking management system with Toloka

Subscribe to Toloka News
Subscribe to Toloka News
In this article, we will look at how to set up a modern parking management system. Such a system identifies license plates of the incoming and outgoing vehicles and coordinates how and where these vehicles enter and exit a parking space. For this to work, the system needs to know how to do image segmentation and character recognition. So, let’s imagine that you need to install this type of system at your workplace or university. Below are the steps to follow.
Step 1: Data collection
The first step is to acquire the necessary data, which in this case is all images. Ready datasets can be used, but they can prove insufficient when processing regional license plates with non-Western characters, like Arabic or Cyrillic. For this reason, we’re going to collect a completely new set of images by getting our crowd performers to do a simple field task – take pictures of different cars around them.
To do this, you can quickly utilize the ready-to-use “Product photo search” template on Toloka and adapt it to collecting pictures of cars.
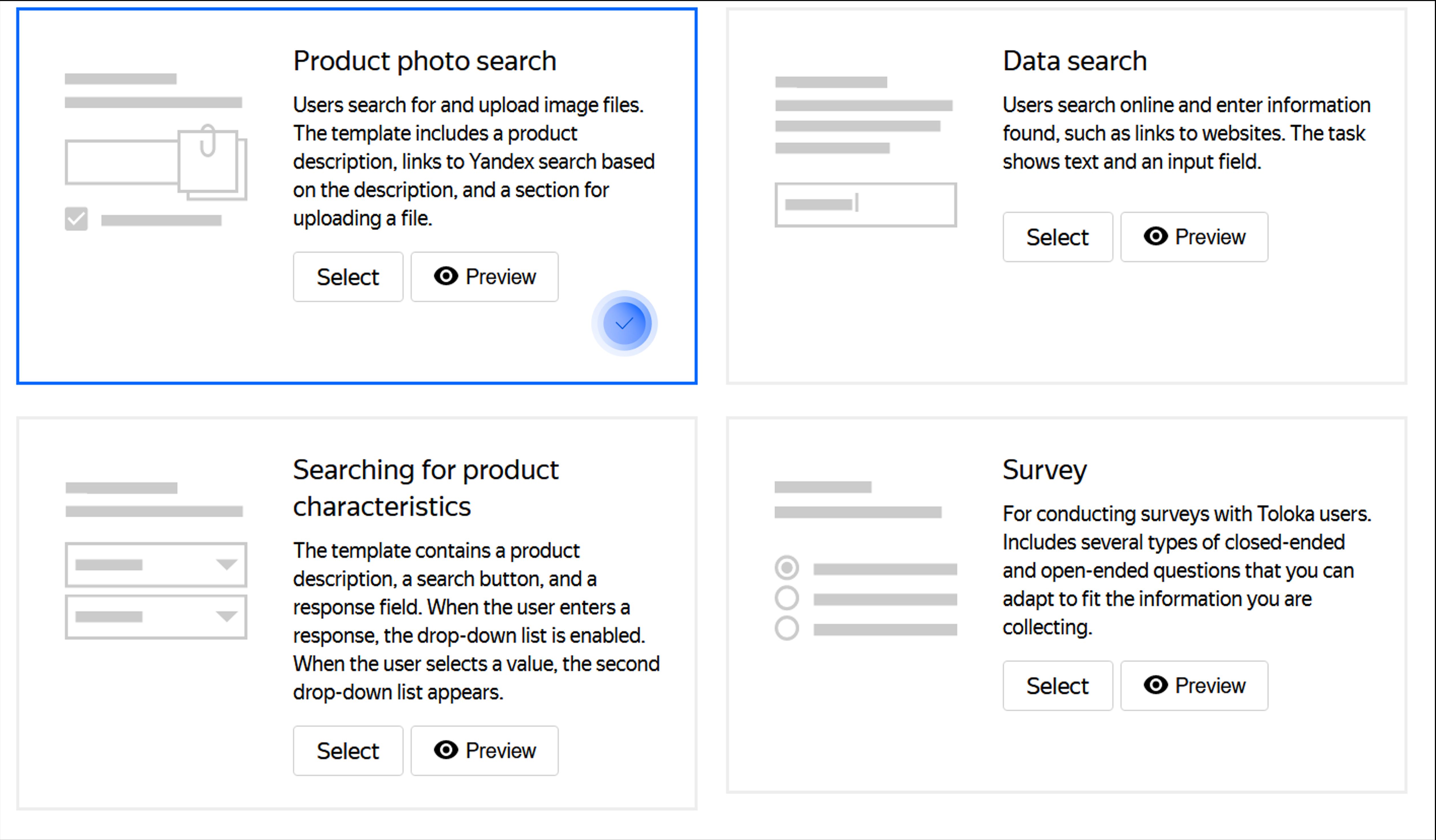
Make sure you explicitly lay out all of the requirements and other relevant information in the instructions. This will play a key role in obtaining a high-quality data set. As per usual, you can ensure that the quality is up to the standard by creating a simple classification project. This way, the performers will evaluate and verify each others’ work against the requirements you’ve put in place. Let’s assume you’ve done that already and now have a ready-to-go data set of, say, 1000 images.
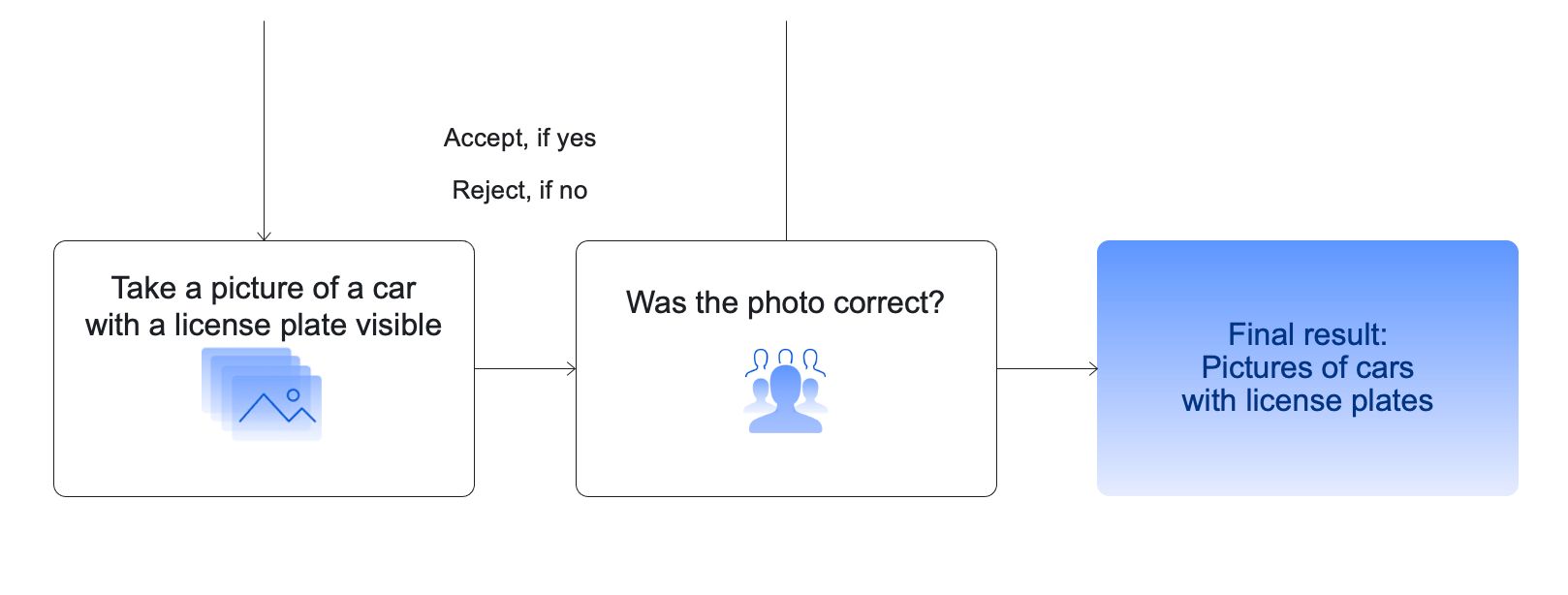
Step 2: Object detection
The next step is license plate detection. Since the images will likely contain quite a bit of information, we need to identify specifically the license plates and disregard the rest. For this task at hand, you can use the YOLO (You Only Look Once) object detection network. However, bear in mind that some training will be required afterwards.
To prepare your training set, use the “Selecting a region in an image” template on Toloka to get our crowd performers to outline all of the license plates in the collected images. To check that the quality is acceptable, you can again create a binary classification project and ask Tolokers to check each others’ work. Once it’s done, you will have your own custom dataset to train a license plate detection model using YOLO’s neural network.
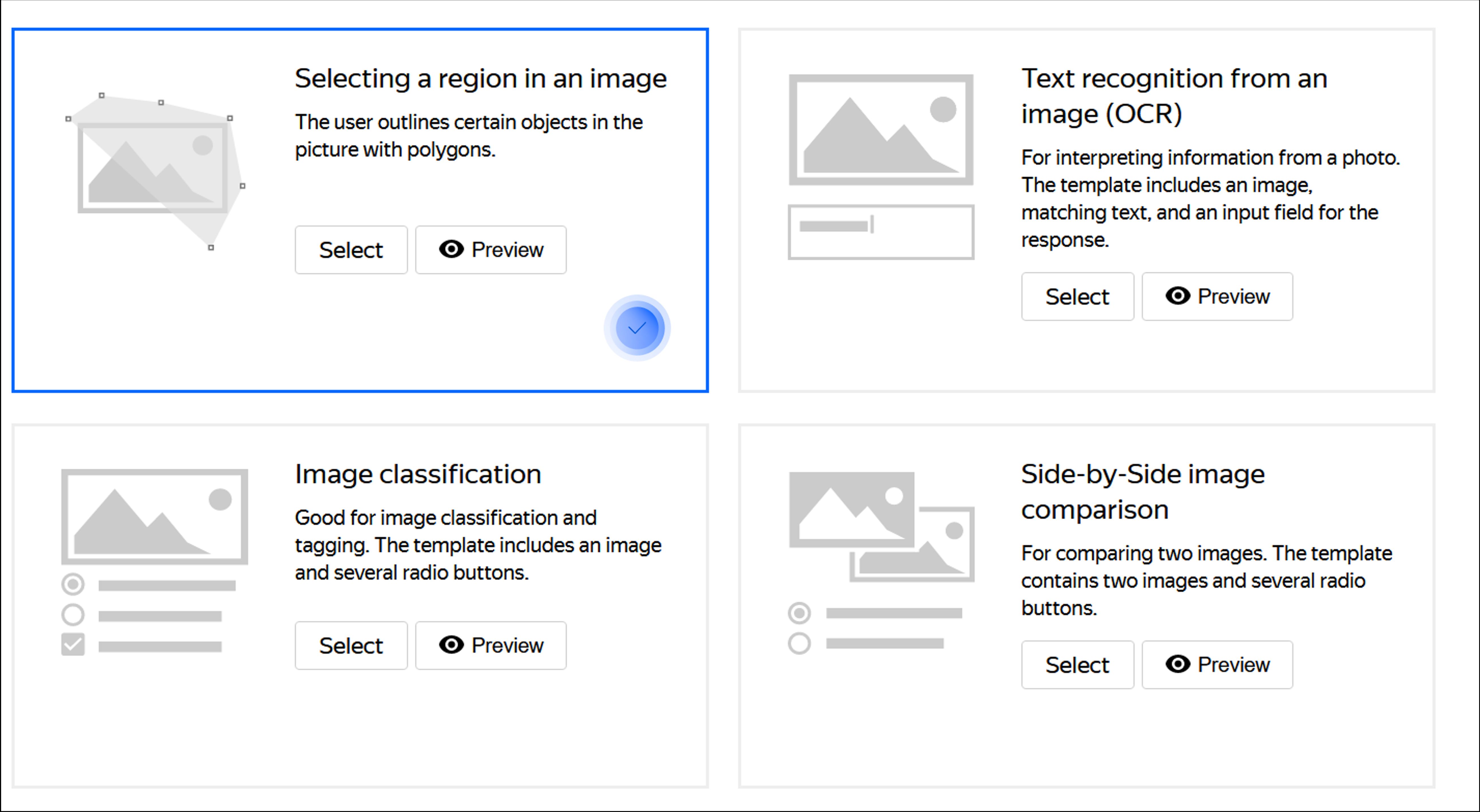
Step 3: Object segmentation
The next step is segmentation which implies extracting specific digits from the license plates you now have. This is another part of the project where quality is of the utmost importance. If the digits are not extracted correctly, the recognition will most likely go south as well. Fortunately, a multitude of segmentation solutions are available to help you with this. And in case you want something more specific, you can always ask the crowd to get involved here, too. This route is more manageable if your dataset isn’t very large.
The pipeline in this case will be the same as with the data collection phase from before – some performers will mark the digits contained within the license plates, and then the other performers will validate their counterparts’ work until we’re sure that everything is fine and dandy. Once you’re through with this phase, you can train the network to turn every license plate into a single line of digits that can be sent for recognition.
Step 4: Text recognition
The final phase is text recognition within the license plates. To train an OCR (Optical Character Recognition) network, you can again use Toloka to save time. To do so, you can quickly utilize the “Text recognition from an image” template available on the platform. Since this is a very common Toloka task, taking this path means falling back onto tried-and-true quality control techniques, among them golden sets and majority voting.
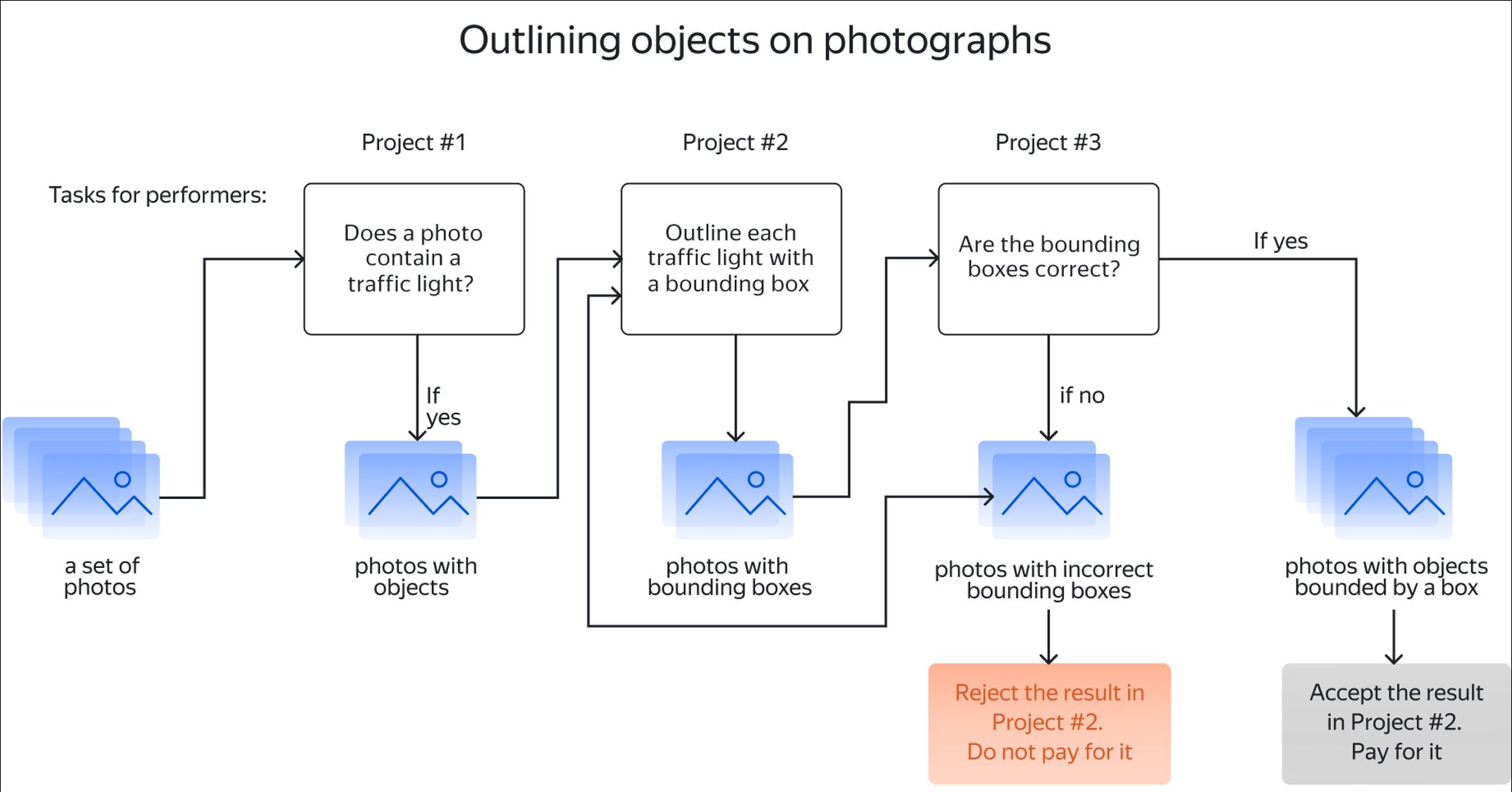
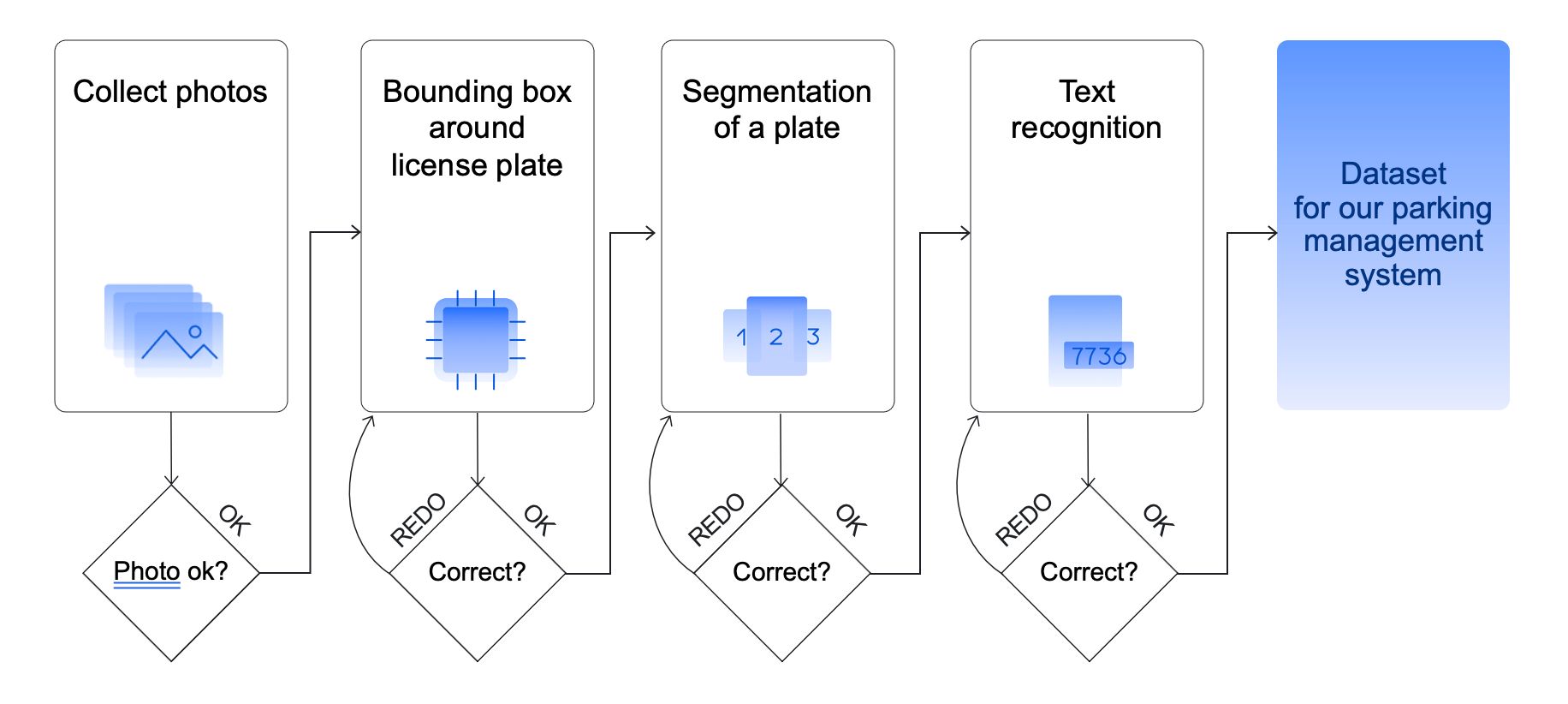
As you can see, there are quite a few crowdsourcing tasks in this parking management project. Toloka has a dynamic API to help you keep track of all of them. This means all of these steps can be easily automated – all you need to do is create a pipeline for your project at large that will allow the data to be transferred between your ongoing tasks. This way, you can also observe first-hand as the labeled data is coming in from Tolokers. A full pipeline for this project should look like this:
Your turn to try
That’s it! No doubt, it’s much easier than you imagined before. Now, it’s your turn to have a go. Follow these steps and also be sure to check out our new self-study guide to get even more hands-on help with our interactive video tutorials.

Recent articles




Have a data labeling project?

More about Toloka
- Our mission is to empower businesses with high quality data to develop AI products that are safe, responsible and trustworthy.
- Toloka is a European company. Our global headquarters is located in Amsterdam. In addition to the Netherlands, Toloka has offices in the US, Israel, Switzerland, and Serbia. We provide data for Generative AI development.
- We are the trusted data partner for all stages of AI development–from training to evaluation. Toloka has over a decade of experience supporting clients with its unique methodology and optimal combination of machine learning technology and human expertise. Toloka offers high quality expert data for training models at scale.
- The Toloka team has supported clients with high-quality data and exceptional service for over 10 years.
- Toloka ensures the quality and accuracy of collected data through rigorous quality assurance measures–including multiple checks and verifications–to provide our clients with data that is reliable and accurate. Our unique quality control methodology includes built-in post-verification, dynamic overlaps, cross-validation, and golden sets.
- Toloka has developed a state-of-the-art technology platform for data labeling and has over 10 years of managing human efforts, ensuring operational excellence at scale. Now, Toloka collaborates with data workers from 100+ countries speaking 40+ languages across 20+ knowledge domains and 120+ subdomains.
- Toloka provides high-quality data for each stage of large language model (LLM) and generative AI (GenAI) development as a managed service. We offer data for fine-tuning, RLHF, and evaluation. Toloka handles a diverse range of projects and tasks of any data type��—text, image, audio, and video—showcasing our versatility and ability to cater to various client needs.
- Toloka addresses ML training data production needs for companies of various sizes and industries– from big tech giants to startups. Our experts cover over 20 knowledge domains and 120 subdomains, enabling us to serve every industry, including complex fields such as medicine and law. Many successful projects have demonstrated Toloka's expertise in delivering high-quality data to clients. Learn more about the use cases we feature on our customer case studies page.