DawidSkene
crowdkit.aggregation.classification.dawid_skene.DawidSkene | Source code
DawidSkene( self, n_iter: int = 100, tol: float = 1e-05)The Dawid-Skene aggregation model is a probabilistic model that parametrizes the expertise level of workers with confusion matrices.
Let be a worker confusion (error) matrix of size in case of the class classification, be a vector of prior class probabilities, be a true task label, and be a worker response to the task . The relationship between these parameters is represented by the following latent label model.
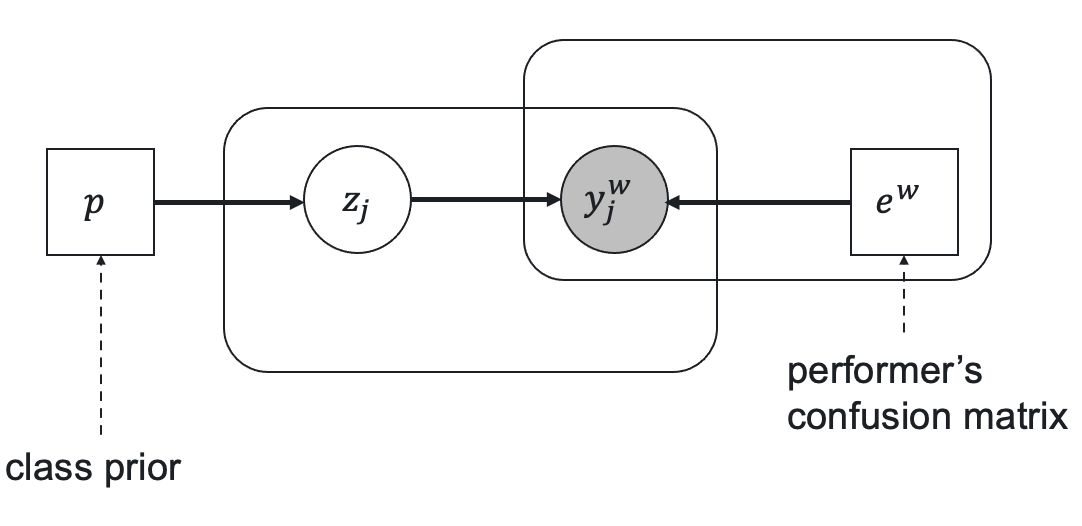
Here the prior true label probability is
,
and the probability distribution of the worker responses with the true label is represented by the corresponding column of the error matrix:
Parameters , , and latent variables are optimized with the Expectation-Maximization algorithm:
- E-step. Estimates the true task label probabilities using the specified workers' responses, the prior label probabilities, and the workers' error probability matrix.
- M-step. Estimates the workers' error probability matrix using the specified workers' responses and the true task label probabilities.
A. Philip Dawid and Allan M. Skene. Maximum Likelihood Estimation of Observer Error-Rates Using the EM Algorithm.
Journal of the Royal Statistical Society. Series C (Applied Statistics), Vol. 28, 1 (1979), 20–28.
https://doi.org/10.2307/2346806
Parameters description
| Parameters | Type | Description |
|---|---|---|
n_iter | int | The maximum number of EM iterations. |
tol | float | The tolerance stopping criterion for iterative methods with a variable number of steps. The algorithm converges when the loss change is less than the |
labels_ | Optional[Series] | The task labels. The |
probas_ | Optional[DataFrame] | The probability distributions of task labels. The |
priors_ | Optional[Series] | The prior label distribution. The |
errors_ | Optional[DataFrame] | The workers' error matrices. The |
loss_history_ | List[float] | A list of loss values during training. |
Examples:
from crowdkit.aggregation import DawidSkenefrom crowdkit.datasets import load_datasetdf, gt = load_dataset('relevance-2')ds = DawidSkene(100)result = ds.fit_predict(df)Methods summary
| Method | Description |
|---|---|
| fit | Fits the model to the training data with the EM algorithm. |
| fit_predict | Fits the model to the training data and returns the aggregated results. |
| fit_predict_proba | Fits the model to the training data and returns probability distributions of labels for each task. |
Last updated: March 31, 2023