MACE
crowdkit.aggregation.classification.mace.MACE | Source code
MACE( self, n_restarts: int = 10, n_iter: int = 50, method: str = 'vb', smoothing: float = 0.1, default_noise: float = 0.5, alpha: float = 0.5, beta: float = 0.5, random_state: int = 0, verbose: int = 0)The Multi-Annotator Competence Estimation (MACE) model is a probabilistic model that associates each worker with a label probability distribution.
A worker can be spamming on each task. If the worker is not spamming, they label a task correctly. If the worker is spamming, they answer according to their probability distribution.
We assume that the correct label comes from a discrete uniform distribution. When a worker annotates a task, they are spamming with probability . specifies whether or not worker is spamming on instance .
Thus, if the worker is not spamming on the task, i.e. , their response is the true label, i.e. . Otherwise, their response is drawn from a multinomial distribution with parameter vector .
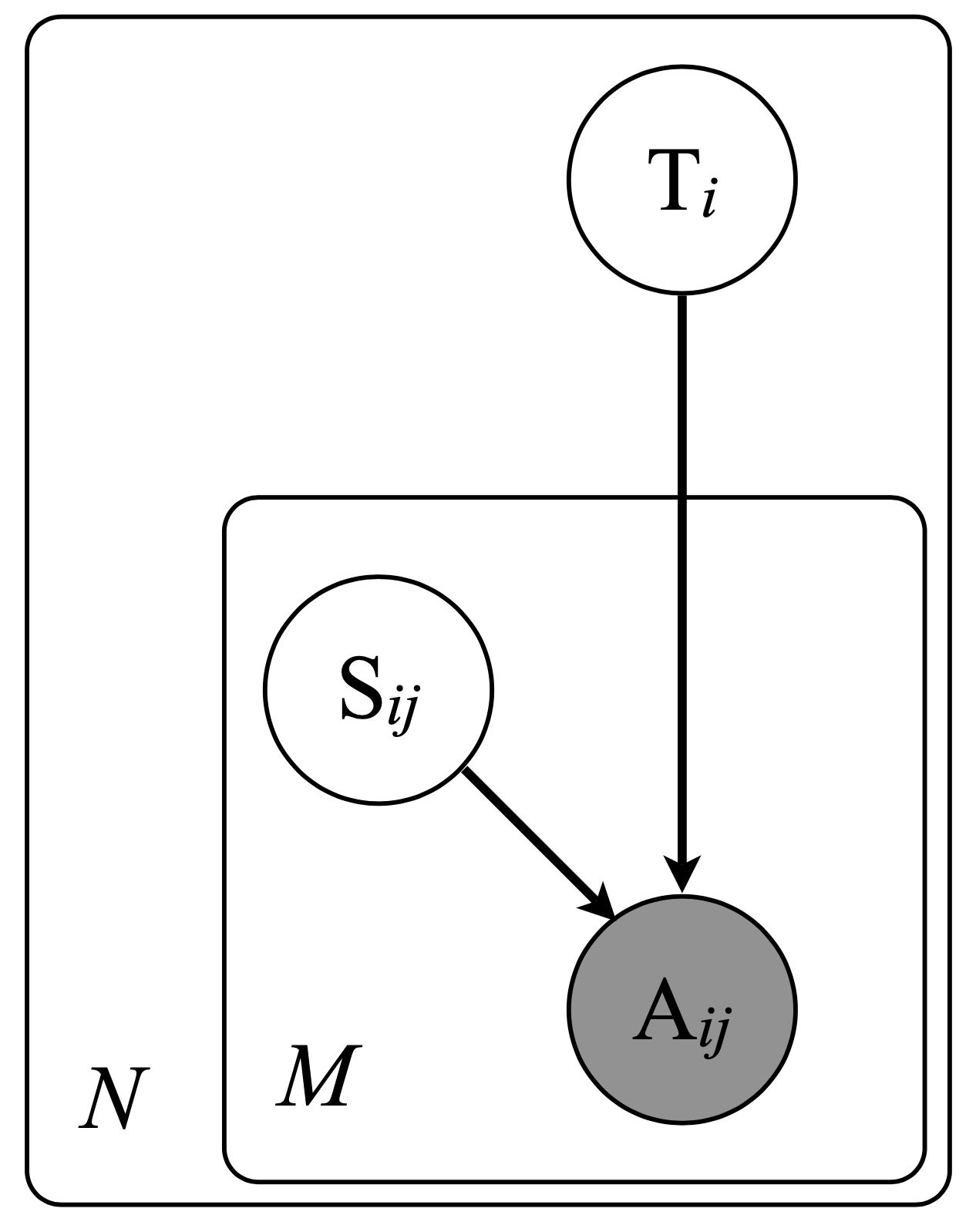
The model can be enhanced by adding the Beta prior on and the Diriclet prior on .
The marginal data likelihood is maximized with the Expectation-Maximization algorithm:
- E-step. Performs
n_restartsrandom restarts, and keeps the model with the best marginal data likelihood. - M-step. Smooths parameters by adding a fixed value
smoothingto the fractional counts before normalizing. - Variational M-step. Employs Variational-Bayes (VB) training with symmetric Beta priors on and symmetric Dirichlet priors on the strategy parameters .
D. Hovy, T. Berg-Kirkpatrick, A. Vaswani and E. Hovy. Learning Whom to Trust with MACE. In Proceedings of NAACL-HLT, Atlanta, GA, USA (2013), 1120–1130.
https://aclanthology.org/N13-1132.pdf
Parameters description
| Parameters | Type | Description |
|---|---|---|
n_restarts | int | The number of optimization runs of the algorithms. The final parameters are those that gave the best log likelihood. If one run takes too long, this parameter can be set to 1. Default: 10. |
n_iter | int | The maximum number of EM iterations for each optimization run. Default: 50. |
method | str | The method which is used for the M-step. Either 'vb' or 'em'. 'vb' means optimization with Variational Bayes using priors. 'em' means standard Expectation-Maximization algorithm. Default: 'vb'. |
smoothing | float | The smoothing parameter for the normalization. Default: 0.1. |
default_noise | float | The default noise parameter for the initialization. Default: 0.5. |
alpha | float | The prior parameter for the Beta distribution on . Default: 0.5. |
beta | float | The prior parameter for the Beta distribution on . Default: 0.5. |
random_state | int | The state of the random number generator. Default: 0. |
verbose | int | Specifies if the progress will be printed or not: 0 — no progress bar, 1 — only for restarts, 2 — for both restarts and optimization. Default: 0. |
labels_ | Optional[Series] | The task labels. The |
probas_ | Optional[DataFrame] | The probability distributions of task labels. The |
spamming_ | ... | The posterior distribution of workers' spamming states. |
thetas_ | ... | The posterior distribution of workers' spamming labels. |
theta_priors_ | Optional[...] | The prior parameters for the Beta distribution on . |
strategy_priors_ | Optional[...] | The prior parameters for the Diriclet distribution on . |
Examples:
from crowdkit.aggregation import MACEfrom crowdkit.datasets import load_datasetdf, gt = load_dataset('relevance-2')mace = MACE()result = mace.fit_predict(df)Methods summary
| Method | Description |
|---|---|
| fit | Fits the model to the training data. |
| fit_predict | Fits the model to the training data and returns the aggregated results. |
| fit_predict_proba | Fits the model to the training data and returns probability distributions of labels for each task. |
Last updated: March 31, 2023